Vad är Azure Data Factory?
GÄLLER FÖR:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
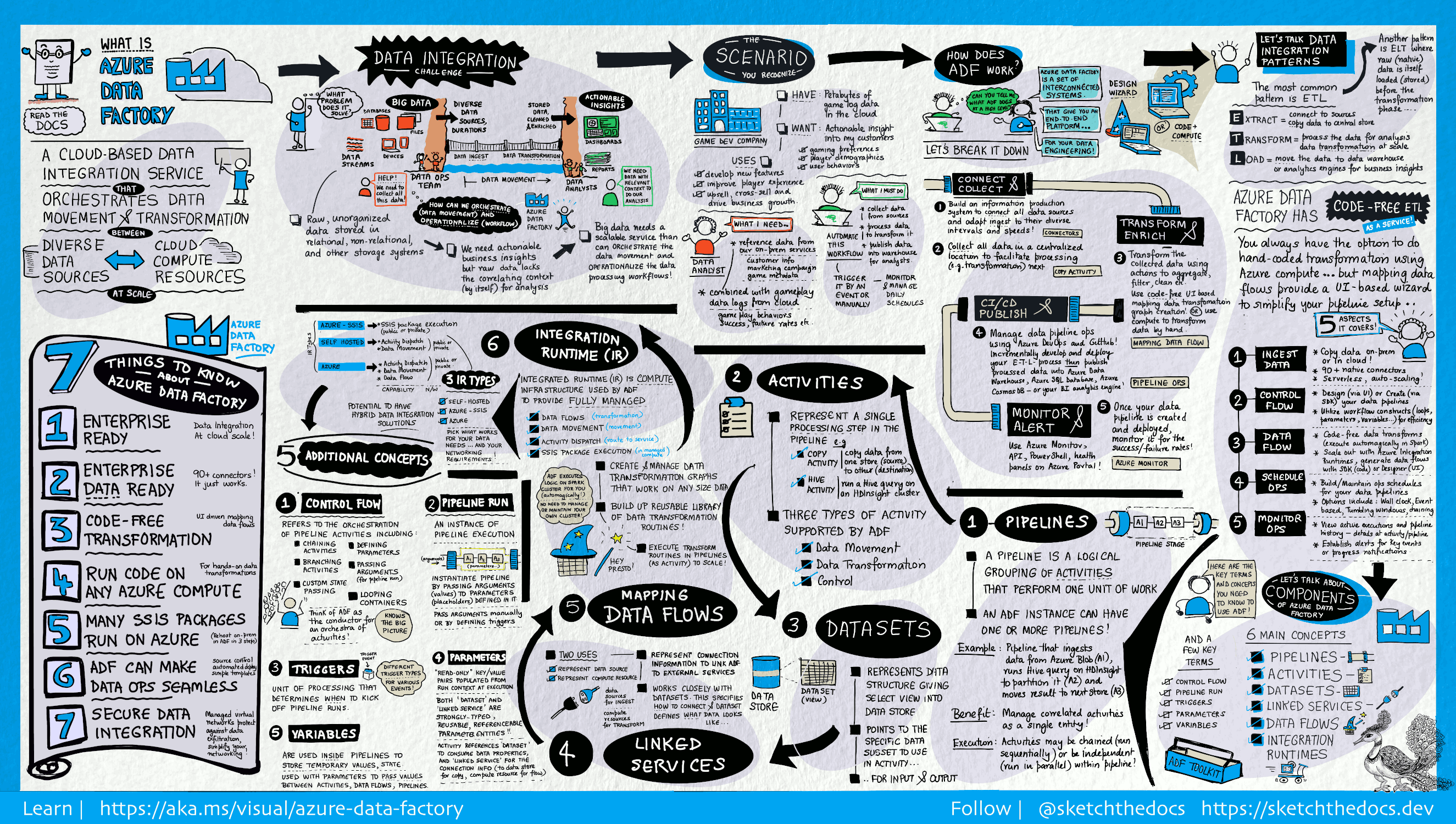
När det gäller stordata, lagras råa, oordnade data ofta i relationella, icke-relationella och andra lagringssystem. Men i sig självt så har rådata inte rätt kontext eller mening för att ge analytiker, dataforskare och beslutsfattare meningsfulla insikter.
Stordata kräver en tjänst som kan samordna och operationalisera processer för att förfina dessa enorma lager av rådata till användbara affärsinsikter. Azure Data Factory är en hanterad molntjänst som skapats för dessa komplexa, hybrida, ETL- (extract-transform-load), ELT- (extract-load-transform) och dataintegreringsprojekt.
Funktioner i Azure Data Factory
Datakomprimering: Under datakopieringsaktiviteten är det möjligt att komprimera data och skriva komprimerade data till måldatakällan. Den här funktionen hjälper till att optimera bandbreddsanvändningen vid datakopiering.
Omfattande anslutningsstöd för olika datakällor: Azure Data Factory ger brett anslutningsstöd för anslutning till olika datakällor. Detta är användbart när du vill hämta eller skriva data från olika datakällor.
Anpassade händelseutlösare: Med Azure Data Factory kan du automatisera databearbetningen med hjälp av anpassade händelseutlösare. Med den här funktionen kan du automatiskt köra en viss åtgärd när en viss händelse inträffar.
Dataförhandsgranskning och validering: Under datakopieringsaktiviteten tillhandahålls verktyg för förhandsgranskning och validering av data. Den här funktionen hjälper dig att se till att data kopieras korrekt och skrivs till måldatakällan korrekt.
Anpassningsbara dataflöden: Med Azure Data Factory kan du skapa anpassningsbara dataflöden. Med den här funktionen kan du lägga till anpassade åtgärder eller steg för databearbetning.
Integrerad säkerhet: Azure Data Factory erbjuder integrerade säkerhetsfunktioner som Integrering av Entra-ID och rollbaserad åtkomstkontroll för att styra åtkomsten till dataflöden. Den här funktionen ökar säkerheten vid databehandling och skyddar dina data.
Användningsscenarier
Tänk dig till exempel ett spelföretag som samlar in petabyte med spelloggar som produceras av spel i molnet. Företaget vill analysera dessa loggar för att få insikter om kundpreferenser, demografi och användningsbeteende. Det vill också identifiera möjligheter till merförsäljning och korsförsäljning, utveckla intressanta nya funktioner, driva affärstillväxten och ge en bättre kundupplevelse.
När företaget ska analysera loggarna måste de använda referensdata, till exempel kundinformation, spelinformation och marknadsföringskampanjinformation som finns i ett lokalt datalager. Företaget vill använda dessa data från det lokala datalagret och kombinera dem med ytterligare loggdata som de har i ett molndatalager.
För att extrahera insikter hoppas den kunna bearbeta anslutna data med hjälp av ett Spark-kluster i molnet (Azure HDInsight) och publicera omvandlade data till ett molndatalager som Azure Synapse Analytics för att enkelt skapa en rapport ovanpå dem. De vill automatisera det här arbetsflödet samt övervaka och hantera det enligt ett dagligt schema. De vill även köra det när filer landar i en bloblagringscontainer.
Azure Data Factory är en plattform som löser den här typen av datascenarier. Det är den molnbaserade ETL- och dataintegreringstjänsten som gör att du kan skapa datadrivna arbetsflöden för att orkestrera dataflytt och transformera data i stor skala. Med Azure Data Factory kan du skapa och schemalägga datadrivna arbetsflöden (så kallade ”pipelines”) som kan mata in data från olika datalager. Du kan skapa komplexa ETL-processer som transformerar data visuellt med dataflöden eller med hjälp av beräkningstjänster som Azure HDInsight Hadoop, Azure Databricks och Azure SQL Database.
Dessutom kan du publicera dina transformerade data till datalager som Azure Synapse Analytics för BI-program (Business Intelligence) att använda. Slutligen kan rådata ordnas, via Azure Data Factory, i meningsfulla datalager och datasjöar för att ge bättre beslutsunderlag.
Hur fungerar det?
Data Factory innehåller en serie sammankopplade system som tillsammans utgör en komplett plattform för datatekniker.

Den här visuella guiden ger en detaljerad översikt över den fullständiga Data Factory-arkitekturen:

Om du vill se mer information väljer du föregående bild för att zooma in eller bläddrar till den högupplösta bilden.
{kind=link}
Ansluta och samla in
Företag har olika typer av data som befinner sig på olika platser, lokalt, i molnet, strukterade, ostrukturerade och delvis strukturerade och alla dessa data anländer i olika intervall och med olika hastighet.
Det första steget när det gäller att skapa ett informationsproduktionssystem är att ansluta till alla nödvändiga data- och bearbetningskällor, exempelvis SaaS-tjänster, databaser, filresurser och FTP-webbtjänster. Nästa steg är att flytta data efter behov till en central plats för senare bearbetning.
Utan Data Factory måste företag skapa egna dataöverföringskomponenter eller skriva anpassade tjänster för att integrera dessa data- och bearbetningskällor. Det är dyrt och svårt att integrera och underhålla sådana system. De saknar dessutom ofta övervakning, varningar och de kontroller i företagsklass som en helt hanterad tjänst kan erbjuda.
Med Data Factory kan du använda kopieringsaktiviteten i en datapipeline för att flytta data från datalager lokalt och molnet till ett centralt datalager i molnet där du kan analysera dem. Du kan till exempel samla in data i Azure Data Lake Storage och transformera data senare med hjälp av en Azure Data Lake Analytics-beräkningstjänst. Eller så kan du samla in data i en Azure Blob Storage och sedan omvandla de med ett Azure HDInsight Hadoop-kluster.
Omvandla och berika
När data finns i ett centraliserat datalager i molnet bearbetar eller transformerar du insamlade data med hjälp av ADF-mappning av dataflöden. Med dataflöden kan datatekniker skapa och underhålla datatransformeringsdiagram som körs på Spark utan att behöva förstå Spark-kluster eller Spark-programmering.
Om du föredrar att koda transformeringar för hand stöder ADF externa aktiviteter för att köra dina omvandlingar på beräkningstjänster som HDInsight Hadoop, Spark, Data Lake Analytics och Mašinsko učenje.
CI/CD och publicera
Data Factory har fullt stöd för CI/CD för dina datapipelines med hjälp av Azure DevOps och GitHub. På så sätt kan du stegvis utveckla och leverera dina ETL-processer innan du publicerar den färdiga produkten. När rådata har förfinats till ett företagsklart förbrukningsformulär läser du in data i Azure Data Warehouse, Azure SQL Database, Azure Cosmos DB eller den analysmotor som dina företagsanvändare kan peka på från sina business intelligence-verktyg.
Monitor
När du har skapat och distribuerat din pipeline för dataintegrering och fått affärsvärde från förfinade data, kan du övervaka schemalagda aktiviteter och pipelines för att se hur många som lyckats respektive misslyckats. Azure Data Factory har ett inbyggt stöd för pipelineövervakning via Azure Monitor, API, PowerShell, Azure Monitor-loggar och hälsopaneler i Azure-portalen.
Toppnivåbegrepp
En Azure-prenumeration kan ha en eller flera Azure Data Factory-instanser (eller datafabriker). Azure Data Factory består av följande nyckelkomponenter:
- Pipelines
- Aktiviteter
- Datauppsättningar
- Länkade tjänster
- Dataflöden
- Integreringskörningar
De här komponenterna samverkar för att tillhandahålla en plattform där du kan skapa datadrivna arbetsflöden med steg för att flytta och omvandla data.
Pipeline
En datafabrik kan ha en eller flera pipelines. En pipeline är en logisk gruppering av aktiviteter som utför en arbetsenhet. Tillsammans utför aktiviteterna i en pipeline en uppgift. En pipeline kan till exempel innehålla en grupp med aktiviteter som matar in data från en Azure-blob och sedan kör en Hive-fråga på ett HDInsight-kluster för att partitionera data.
Fördelen med detta är att pipelinen låter dig hantera aktiviteter som en uppsättning istället för enskilt. Aktiviteter i en pipeline kan sammanlänkas för att köras sekventiellt eller så kan de köras fristående och parallellt.
Mappa dataflöden
Skapa och hantera grafer med datatransformeringslogik som du kan använda för att transformera data i valfri storlek. Du kan bygga upp ett återanvändbart bibliotek med datatransformeringsrutiner och köra dessa processer på ett utskalat sätt från dina ADF-pipelines. Data Factory kör din logik på ett Spark-kluster som snurrar upp och snurrar ner när du behöver det. Du behöver aldrig hantera eller underhålla kluster.
Aktivitet
Aktiviteter representerar ett bearbetningssteg i en pipeline. Du kan till exempel använda en kopieringsaktivitet för att kopiera data från ett datalager till ett annat. På samma sätt kan du använda en Hive-aktivitet som kör en Hive-fråga på ett Azure HDInsight-kluster för att transformera eller analysera dina data. Data Factory stöder tre typer av aktiviteter: dataförflyttning, datatransformering och kontroll.
Datauppsättningar
Datauppsättningar representerar datastrukturer i datalager som pekar på eller refererar till de data som du vill använda i dina aktiviteter som indata eller utdata.
Länkade tjänster
Länkade tjänster liknar anslutningssträngar som definierar den anslutningsinformation som behövs för att Data Factory ska kunna ansluta till externa resurser. Man kan se det som att datamängden representerar strukturen för data och den länkade tjänsten definierar anslutningen till datakällan. Till exempel anger en länkad Azure Storage-tjänst en anslutningssträng för att ansluta till ett Azure Storage-konto. Och en Azure Blob-datauppsättning anger vilken blobcontainer och mapp som innehåller data.
Länkade tjänster används för två syften i Data Factory:
För att representera ett datalager som innehåller, men inte är begränsat till, en SQL Server-databas, Oracle-databas, filresurs eller Azure Blob Storage-konto. En lista över datalager som stöds finns i artikeln om kopieringsaktiviteter.
Så här visar du en beräkningsresurs som kan vara värd för körningen av en aktivitet. HDInsightHive-aktiviteten körs till exempel på ett HDInsight Hadoop-kluster. En lista över transformeringsaktiviteter och beräkningsmiljöer som stöds finns i artikeln om omvandling av data.
Integration Runtime
I Data Factory definierar en aktivitet åtgärden som ska utföras. En länkad tjänst definierar ett datalager som mål eller en beräkningstjänst. Integration Runtime utgör bryggan mellan aktiviteten och länkade tjänster. Den refereras av den länkade tjänsten eller aktiviteten och tillhandahåller beräkningsmiljön där aktiviteten antingen körs på eller skickas från. På så sätt kan aktiviteten utföras i regionen som är den närmaste möjliga till måldatalagret eller beräkningstjänsten på det bästa sättet samtidigt som den uppfyller säkerhets- och efterlevnadsbehoven.
Utlösare
Utlösare representerar en bearbetningsenhet som avgör när en pipelinekörning måste startas. Det finns olika typer av utlösare för olika typer av händelser.
Pipelinekörningar
En pipelinekörning är en instans av en pipelinekörning. Pipelinekörningar initieras vanligen genom att skicka argumenten till de parametrar som definierats i pipelines. Argumenten kan skickas manuellt eller i en utlösardefinition.
Parametrar
Parametrar är nyckel/värde-par i en skrivskyddad konfiguration. Parametrar har definierats i pipelinen. Argumenten för de definierade parametrarna skickas vid körning från körningskontexten som skapats av en utlösare eller en pipeline som körs manuellt. Aktiviteter i pipelinen använder parametervärdena.
En datauppsättning är en starkt typifierad parameter och en återanvändbar/refererbar entitet. En aktivitet kan referera till datauppsättningar och kan använda egenskaperna som definierats i definitionen för datauppsättningen.
En länkad tjänst är också en starkt typifierad parameter som innehåller anslutningsinformationen till antingen ett datalager eller en beräkningsmiljö. Det är också en återanvändningsbar/refererbar entitet.
Kontrollflöde
Kontrollflöde är en orkestrering av pipelineaktiviteter som innefattar kedjesammansättning av aktiviteter i en sekvens, branchning definiering av parametrar på pipelinenivå och argument som skickas vid anrop till pipelinen på begäran eller från en utlösare. Det innefattar även att skicka anpassade tillstånd och loopcontainer, d.v.s. for-each-iteratorer.
Variabler
Variabler kan användas i pipelines för att lagra temporära värden och kan även användas tillsammans med parametrar för att aktivera överföringsvärden mellan pipelines, dataflöden och andra aktiviteter.
Relaterat innehåll
Här är viktiga nästa steg dokument att utforska: