Återförsäljare och konsumentvarumärken fokuserar på att se till att de har rätt produkter och tjänster som konsumenterna försöker köpa på marknadsplatsen. När du tittar på att maximera försäljningen är produkter (eller kombinationer av produkter) den största delen av shoppingupplevelsen. Tillgängligheten för erbjudanden – inventering – är ett ständigt problem för konsumentvarumärken.
Produktinventering, även kallat SKU-sortiment, är ett komplext problem som omfattar värdekedjan för leverans och logistik. För den här artikeln fokuserar vi specifikt på problemet med att optimera SKU-sortimentet för att maximera intäkterna ur konsumentvarusynpunkt
Pusslet med SKU-sortimentsoptimering kan lösas genom att utveckla algoritmer för att besvara följande frågor:
- Vilka SKU:er presterar bäst på en viss marknad eller butik?
- Vilka SKU:er ska allokeras till en viss marknad eller butik baserat på deras prestanda?
- Vilka SKU:er har låga prestanda och bör ersättas av SKU:er med högre prestanda?
- Vilka andra insikter kan vi härleda om våra konsument- och marknadssegment?
Automatisera beslutsfattande
Traditionellt närmade sig konsumentvarumärken frågan om konsumentefterfrågan genom att öka antalet SKU:er i SKU-portföljen. I takt med att antalet SKU:er ökade och konkurrensen ökade beräknas 90 procent av intäkterna endast tillskrivas 10 procent av produkt-SKU:erna i portföljen. Normalt uppkommer 80 procent av intäkterna från 20 procent av SKU:erna. Och detta förhållande är en kandidat för att förbättra lönsamheten.
Traditionella metoder för statisk rapportering använder historiska data, vilket begränsar insikter. I bästa fall fattas och implementeras beslut fortfarande manuellt. Detta innebär mänsklig intervention och bearbetningstid. Med utvecklingen av AI och molnbaserad databehandling är det möjligt att använda avancerad analys för att tillhandahålla en rad olika val och förutsägelser. Den här typen av automatisering förbättrar resultat och hastighet till kund.
SKU-sortimentsoptimering
En SKU-sortimentslösning måste hantera miljontals SKU:er genom att segmentera försäljningsdata i meningsfulla och detaljerade jämförelser. Målet med lösningen är att använda avancerad analys för att maximera försäljningen i varje försäljningsställe eller butik genom att justera produktsortimentet. Ett andra mål är att eliminera out-of-stocks och förbättra sortimentet. Det finanspolitiska målet är en försäljningsökning på 5 till tio procent. För detta ändamål kan insikter göra det möjligt för en att:
- Förstå SKU-portföljprestanda och hantera låga prestanda.
- Optimera fördelningen av SKU:er för att minska out-of-stocks.
- Förstå hur nya SKU:er stöder kortsiktiga och långsiktiga strategier.
- Skapa repeterbara, skalbara och användbara insikter från befintliga data.
Beskrivande analys
Beskrivande modeller aggregerar datapunkter och utforskar relationer mellan faktorer som kan påverka produktförsäljningen. Informationen kan utökas med vissa externa datapunkter, till exempel plats, väder och censusdata. Visualiseringar hjälper människor att härleda insikter genom att tolka data. När du gör det begränsas dock förståelsen till vad som hände under den föregående försäljningscykeln, eller möjligen vad som händer i den aktuella (beroende på hur ofta data uppdateras).
En traditionell metod för datalagerhantering och rapportering räcker i det här fallet för att till exempel förstå vilka SKU:er som har varit bäst och sämst presterande under en viss tidsperiod.
Följande bild visar en typisk rapport över historiska försäljningsdata. Den innehåller flera block med kryssrutor för att välja villkor för att filtrera resultatet. I mitten visas två stapeldiagram som visar försäljning över tid. Det första diagrammet visar den genomsnittliga försäljningen per vecka. Den andra visar kvantiteter per vecka.

Förutsägelseanalys
Historisk rapportering hjälper dig att förstå vad som hände. I slutändan vill vi ha en prognos för vad som sannolikt kommer att hända. Tidigare information kan vara användbar för det ändamålet. Vi kan till exempel identifiera säsongstrender. Men det kan inte hjälpa med konsekvensscenarier, till exempel för att modellera introduktionen av en ny produkt. För att göra det måste vi fokusera på att modellera kundernas beteende, eftersom det är den ultimata faktorn som avgör försäljningen.
En djupgående titt på problemet: valmodeller
Vi börjar med att definiera vad vi letar efter och vilka data vi har:
Sortimentsoptimering innebär att hitta en delmängd av produkter att sälja som maximerar de förväntade intäkterna. Det här är vad vi letar efter.
Transaktionsdata samlas rutinmässigt in för ekonomiska ändamål.
Sortimentsdata kan innehålla allt som gäller SKU:er: Här är ett exempel på vad vi vill ha:
- Antalet SKU:er
- SKU-beskrivningar
- Allokerade kvantiteter
- Köpt SKU och kvantitet
- Tidsstämplar för händelser (till exempel inköp)
- SKU-pris
- SKU-pris på POS
- Lagernivå för varje SKU när som helst
Sådana data samlas tyvärr inte in lika tillförlitligt som transaktionsdata.
I den här artikeln tar vi för enkelhetens skull bara hänsyn till transaktionsdata och SKU-data, inte externa faktorer.
Men observera att med tanke på en uppsättning n-produkter finns det 2n möjliga sortiment. Detta gör optimeringsproblemet till en beräkningsintensiv process. Att utvärdera alla möjliga kombinationer är opraktiskt med ett stort antal produkter. Så vanligtvis segmenteras sortiment efter kategori (till exempel spannmål), plats och andra kriterier för att minska antalet variabler. Optimeringsmodeller försöker rensa antalet permutationer till en fungerande delmängd.
Problemets kärna ligger i att modellera konsumenternas beteende effektivt. I en perfekt värld kommer de produkter som presenteras för dem att matcha dem som de vill köpa.
Matematiska modeller för att förutsäga konsumentval har utvecklats under årtionden. Valet av modell avgör i slutändan den lämpligaste implementeringstekniken. Därför sammanfattar vi dem och erbjuder några saker att tänka på.
Parametriska modeller
Parametriska modeller approximeras kundens beteende med hjälp av en funktion med en begränsad uppsättning parametrar. Vi uppskattar den uppsättning parametrar som passar bäst för de data som står till vårt förfogande. En av de äldsta och mest kända är Multinomial Logistic Regression (även känd som MNL, multi-class logit eller softmax regression). Den används för att beräkna sannolikheten för flera möjliga utfall i klassificeringsproblem. I det här fallet kan du använda MNL för att beräkna:
Sannolikheten att en konsument (c) väljer ett objekt (i) vid en viss tidpunkt (t), givet en uppsättning objekt i den kategorin i ett sortiment (a) med ett känt verktyg för kunden (v).
Vi antar också att verktyget för ett objekt kan vara en funktion av dess funktioner. Extern information kan också ingå i måttet för nytta (till exempel är ett paraply mer användbart när det regnar).
Vi använder ofta MNL som ett riktmärke för andra modeller på grund av dess dragbarhet vid beräkning av parametrar och vid utvärdering av resultat. Med andra ord, om du gör värre än MNL är din algoritm inte till någon nytta.
Flera modeller har härletts från MNL, men det ligger utanför det här dokumentets omfång för att diskutera dem.
Det finns bibliotek för programmeringsspråken R och Python. För R kan du använda glm (och derivat). För Python finns scikit-learn, biogeme och lärk. De här biblioteken erbjuder verktyg för att ange MNL-problem och parallella lösare för att hitta lösningar på en mängd olika plattformar.
Nyligen har implementeringen av MNL-modeller på GPU:er föreslagits för att beräkna komplexa modeller med ett antal parametrar som annars skulle göra dem svårlösta.
Neurala nätverk med ett softmax-utdatalager har använts effektivt på stora problem med flera klasser. Dessa nätverk skapar en vektor av utdata som representerar en sannolikhetsfördelning över ett antal olika utfall. De är långsamma att träna jämfört med andra implementeringar, men de kan hantera ett stort antal klasser och parametrar.
Icke-parametriska modeller
Trots sin popularitet placerar MNL några betydande antaganden om mänskligt beteende som kan begränsa dess användbarhet. I synnerhet förutsätter det att den relativa sannolikheten för att någon väljer mellan två alternativ är oberoende av ytterligare alternativ som introduceras i uppsättningen senare. Det är opraktiskt i de flesta fall.
Om du till exempel gillar produkt A och produkt B på samma sätt väljer du en över de andra 50 % av tiden. Nu ska vi introducera produkt C i mixen. Du kan fortfarande välja produkt A 50 % av tiden, men nu delar du upp din inställning 25 % till produkt B och 25 % till produkt C. Den relativa sannolikheten har ändrats.
Dessutom har MNL och derivat inget enkelt sätt att ta hänsyn till ersättningar som beror på lager eller sortimentsvariabel (det vill: när du inte har någon tydlig idé och väljer ett slumpmässigt objekt bland dem på hyllan).
Icke-parametriska modeller är utformade för att ta hänsyn till ersättningar och medför färre begränsningar för kundernas beteende.
De introducerar begreppet rangordning, där konsumenterna uttrycker en strikt preferens för produkter i ett sortiment. Deras köpbeteende kan därför modelleras genom att sortera produkterna i fallande prioritetsordning.
Problem med sortimentsoptimering kan uttryckas som maximering av intäkter:
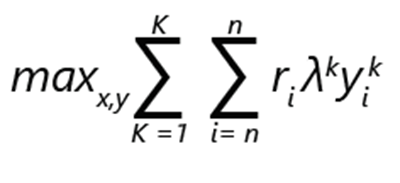
- ri anger intäkterna från produkt i.
- yik är 1 om produkten jag väljs i rangordning k. Annars är det 0.
- λk är sannolikheten att kunden gör ett val enligt rangordning k.
- xi är 1, om produkten ingår i sortimentet. Annars är det 0.
- K är antalet rankningar.
- n är antalet produkter.
Kommentar
Med förbehåll för begränsningar:
- Det kan finnas exakt 1 val för varje rangordning.
- Under en rangordning k, en produkt jag kan väljas endast om det är en del av sortimentet.
- Om en produkt i ingår i sortimentet kan inget av de mindre föredragna alternativen i rankning k väljas.
- Inget köp är ett alternativ, och därför kan inget av de mindre föredragna alternativen i en rangordning väljas.
I en sådan formulering kan problemet betraktas som en optimering av blandat heltal.
Låt oss tänka på att om det finns n produkter är det maximala antalet möjliga rankningar, inklusive alternativet utan val, faktoriell: (n+1)!
Begränsningarna i formuleringen möjliggör en relativt effektiv rensning av möjliga alternativ. Till exempel väljs endast det mest föredragna alternativet och anges till 1. Resten är inställt på 0. Du kan tänka dig att implementeringens skalbarhet kommer att vara viktig med tanke på antalet möjliga alternativ.
Vikten av data
Vi nämnde tidigare att försäljningsdata är lättillgängliga. Vi vill använda den för att informera vår sortimentsoptimeringsmodell. I synnerhet vill vi hitta vår sannolikhetsfördelning λ.
Försäljningsdata från point-of-sales-systemet består av transaktioner som har tidsstämplar och en uppsättning produkter som visas för kunder vid den tidpunkten och platsen. Från dessa kan vi konstruera en vektor för faktisk försäljning, vars element vi,m representerar sannolikheten att sälja objekt i till en kund med tanke på ett sortiment S m
Vi kan också skapa en matris:
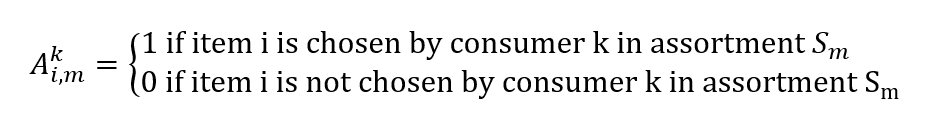
Att hitta vår sannolikhetsfördelning λ med tanke på våra försäljningsdata blir ett annat optimeringsproblem. Vi vill hitta en vektor λ för att minimera vårt försäljningsuppskattningsfel:
minλ |Λλ - v|
Observera att beräkningen också kan uttryckas som en regression och därför kan modeller som beslutsträd med flera variater användas.
Implementeringsdetaljer
Som vi kan härleda från den tidigare formuleringen är optimeringsmodeller både datadrivna och beräkningsintensiva.
Microsofts partner, till exempel Neal Analytics, har utvecklat robusta arkitekturer för att uppfylla dessa villkor. Se SKU-sortimentsoptimering. Vi använder dessa arkitekturer som exempel och erbjuder några saker att tänka på.
- Först förlitar de sig på en robust och skalbar datapipeline för att mata modellerna och på en robust och skalbar körningsinfrastruktur för att köra dem.
- För det andra kan resultaten enkelt användas av planerare via en instrumentpanel.
Bild 2 visar en exempelarkitektur. Den innehåller fyra huvudblock: avbilda, bearbeta, modellera och operationalisera. Varje block innehåller större processer. Insamling omfattar förbearbetning av data. innehåller funktionen för lagringsdata. modellen innehåller funktionen träna maskininlärningsmodell; och operationalize inkluderar lagringsdata och rapporteringsalternativ (till exempel instrumentpaneler).

Bild 2: Arkitektur för en SKU-optimering, med tillstånd av Neal Analytics
Datapipelinen
Arkitekturen belyser vikten av att upprätta en datapipeline för både träning och drift av modellen. Vi samordnar aktiviteterna i pipelinen med hjälp av Azure Data Factory, en hanterad tjänst för extrahering, transformering och inläsning (ETL) som gör att du kan utforma och köra dina integreringsarbetsflöden.
Azure Data Factory är en hanterad tjänst med komponenter som kallas aktiviteter som förbrukar och/eller producerar datauppsättningar.
Aktiviteter kan delas upp i:
- Dataflytt (till exempel kopiering från källa till mål)
- Datatransformering (till exempel aggregering med en SQL-fråga eller körning av en lagrad procedur)
Arbetsflöden som länkar samman uppsättningar med aktiviteter kan schemaläggas, övervakas och hanteras av datafabrikstjänsten. Det fullständiga arbetsflödet kallas för en pipeline.
I insamlingsfasen kan vi använda kopieringsaktiviteten för Data Factory för att överföra data från en mängd olika källor (både lokalt och i molnet) till Azure SQL Data Warehouse. Exempel på hur du gör det finns i dokumentationen:
Följande bild visar definitionen av en pipeline. Den består av tre lika stora block i en rad. De två första är en datauppsättning och en aktivitet som är ansluten med pilar för att indikera dataflöden. Den tredje är märkt Pipeline och pekar på de två första för att indikera inkapsling.

Bild 3: Grundläggande begrepp i Azure Data Factory
Ett exempel på det dataformat som används av Neal Analytics-lösningen finns på sidan Microsofts kommersiella marknadsplats. Lösningen innehåller följande datauppsättningar:
- Försäljningshistorikdata för varje kombination av butik och SKU
- Arkiv- och konsumentposter
- SKU-koder och beskrivning
- SKU-attribut som samlar in funktioner i produkterna (till exempel storlek och material). Dessa används vanligtvis i parametriska modeller för att skilja mellan produktvarianter.
Om datakällorna inte uttrycks i det specifika formatet erbjuder Data Factory en serie transformeringsaktiviteter.
I processfasen är SQL Data Warehouse den huvudsakliga lagringsmotorn. Du kan uttrycka en sådan transformeringsaktivitet som en SQL-lagrad procedur, som automatiskt kan anropas som en del av pipelinen. Dokumentationen innehåller detaljerade instruktioner:
Observera att Data Factory inte begränsar dig till SQL Data Warehouse- och SQL-lagrade procedurer. I själva verket integreras den med en mängd olika plattformar. Du kan till exempel använda Databricks och köra ett Python-skript i stället för transformering. Det här är en fördel eftersom du kan använda en plattform för lagring, transformering och träning av maskininlärningsalgoritmer i följande modellsteg.
Träna ML-algoritmen
Det finns flera verktyg som kan hjälpa dig att implementera parametriska och icke-parametriska modeller. Ditt val beror på dina skalbarhets- och prestandakrav.
Azure ML Studio är ett bra verktyg för prototyper. Det är ett enkelt sätt för dig att skapa och köra ett träningsarbetsflöde med dina kodmoduler (i R eller Python) eller med fördefinierade ML-komponenter (till exempel klassificerare med flera klasser och förbättrad regression av beslutsträd) i en grafisk miljö. Det gör det också enkelt för dig att publicera en tränad modell som en webbtjänst för ytterligare förbrukning, vilket genererar ett REST-gränssnitt åt dig.
Den datastorlek som den kan hantera är dock för närvarande begränsad till 10 GB och antalet kärnor som är tillgängliga för varje komponent är begränsat till två.
Om du behöver skala ytterligare men ändå vill använda några av de snabba, parallella Microsoft-implementeringarna av vanliga maskininlärningsalgoritmer (till exempel multinom logistisk regression) kan du överväga microsoft ML Server som körs på Azure Data Science Virtual Machine.
För mycket stora datastorlekar (TB) är det klokt att välja en plattform där lagrings- och beräkningselementet kan:
- Skala separat för att begränsa kostnaderna när du inte tränar modellerna.
- Distribuera beräkningen över flera kärnor.
- Kör beräkningen nära lagringen för att begränsa dataflytten.
Både Azure HDInsight och Databricks uppfyller dessa krav. Dessutom är de båda körningsplattformar som stöds i Azure Data Factory-redigeraren. Det är relativt enkelt att integrera någon av dem i ett arbetsflöde.
ML Server och dess bibliotek kan distribueras ovanpå HDInsight, men för att dra full nytta av plattformsfunktionerna kan du implementera valfri ML-algoritm med hjälp av SparkML, Microsoft ML Spark-bibliotek i Python eller andra specialiserade linjära programmeringslösare som TFoCS, Spark-LP eller SolveDF.
När du startar träningsprocessen blir det en fråga om att anropa lämpligt pySpark-skript eller en notebook-fil från ett Data Factory-arbetsflöde. Detta stöds fullt ut i den grafiska redigeraren. Mer information finns i Köra en Databricks-notebook-fil med Databricks Notebook-aktiviteten i Azure Data Factory.
Följande bild visar Data Factory-användargränssnittet, som nås via Azure-portalen. Den innehåller block för de olika processerna i arbetsflödet.

Bild 4: Exempel på en Data Factory-pipeline med en Databricks Notebook-aktivitet
Observera också att vi i vår lageroptimeringslösning föreslår en containerbaserad implementering av lösare som skalas via Azure Batch. Specialiserade optimeringsbibliotek som pyomo gör det möjligt för dig att uttrycka ett optimeringsproblem med hjälp av programmeringsspråket Python och sedan anropa oberoende lösare som bonmin (öppen källkod) eller gurobi (kommersiell) för att hitta en lösning.
Dokumentationen om inventeringsoptimering hanterar ett annat problem (orderkvantiteter) än sortimentsoptimering, men implementeringen av lösare i Azure är på samma sätt tillämplig.
Även om det är mer komplext än de som hittills föreslagits möjliggör den här tekniken maximal skalbarhet, vilket främst begränsas av antalet kärnor som du har råd med.
Köra modellen (operationalisera)
När modellen har tränats kräver körningen vanligtvis en annan infrastruktur än den som används för distribution. För att göra det enkelt att använda kan du distribuera det som en webbtjänst med ett REST-gränssnitt. Både Azure ML Studio och ML Server automatiserar processen med att skapa sådana tjänster. När det gäller ML Server tillhandahåller Microsoft mallar för distribution av en stödjande infrastruktur. Se relevant dokumentation.
Följande bild visar distributionens arkitektur. Den innehåller representationer av servrar som kör R-språket och Python. Båda servrarna kommunicerar med en delmängd av webbnoder som utför beräkningen. Ett stort datalager är anslutet till beräkningsblocket.

Bild 5: Exempel på en ML-serverdistribution
Modeller som skapas på HDInsight eller Databricks är beroende av Spark-miljön (bibliotek, parallella funktioner och så vidare). Du kan överväga att köra dem i ett kluster. Vägledning finns här. Detta har fördelen att driftmodellen själv kan anropas via en Data Factory-pipelineaktivitet för bedömning.
Om du vill använda containrar kan du paketera dina modeller och distribuera dem i Azure Kubernetes Service. Prototyper kräver användning av den virtuella Azure Data Science-datorn. Du måste också installera Azure ML-kommandoradsverktygen på den virtuella datorn.
Datautdata och rapportering
När den har distribuerats kan modellen bearbeta arbetsflöden för finansiella transaktioner och lageravläsningar för att generera optimala sortimentsförutsägelser. De data som skapas kan lagras i Azure SQL Data Warehouse för ytterligare analys. I synnerhet är det möjligt att studera historiska prestanda för olika SKU:er och identifiera de bästa intäktsgeneratorerna och förlustskaparna. Du kan sedan jämföra dem med de sortiment som föreslås av modellerna och utvärdera prestanda och behovet av omträning.
Power BI är ett sätt att analysera och visa de data som produceras i processen.
Följande bild visar en typisk Power BI-instrumentpanel. Den innehåller två diagram som visar SKU-lagerinformation.
Säkerhetsfrågor
En lösning som hanterar känsliga data innehåller finansiella poster, lagernivåer och prisinformation. Sådana känsliga data måste skyddas. Du kan minska oron för säkerhet och sekretess för data på följande sätt:
- Du kan köra en del av Azure Data Factory-pipelinen lokalt med hjälp av Azure Integration Runtime. Körningen kör dataförflyttningsaktiviteter till och från lokala källor. Den skickar också aktiviteter för körning lokalt.
- Du kan utveckla en anpassad aktivitet för att anonymisera data som ska överföras till Azure och köra dem lokalt.
- Alla tjänster som nämns stöder kryptering under överföring och i vila. Om du väljer att lagra data med hjälp av Azure Data Lake är kryptering aktiverat som standard. Om du använder Azure SQL Data Warehouse kan du aktivera transparent datakryptering (TDE).
- Alla tjänster som nämns, med undantag för ML Studio, stöder integrering med Microsoft Entra-ID för autentisering och auktorisering. Om du skriver din egen kod måste du skapa den integreringen i ditt program.
Mer information om den allmänna dataskyddsförordningen (GDPR), en dataskydds- och sekretessförordning i Europeiska unionen, finns på vår efterlevnadssida .
Komponenter
Följande tekniker presenterades i den här artikeln:
- Azure Batch
- Microsoft Entra ID
- Azure Data Factory
- HDInsight
- Databricks
- Data Science Virtual Machines
- Azure Kubernetes Service
- Microsoft Power BI
Deltagare
Den här artikeln underhålls av Microsoft. Det har ursprungligen skrivits av följande medarbetare.
Huvudförfattare:
- Scott Seely | Programvaruarkitekt
Om du vill se icke-offentliga LinkedIn-profiler loggar du in på LinkedIn.
Nästa steg
- Vad är Azure Data Factory?
- Integration Runtime i Azure Data Factory
- Vad är en dedikerad SQL-pool (tidigare SQL DW) i Azure Synapse Analytics?
- Microsoft Mašinsko učenje Studio (klassisk)
- Vad är Mašinsko učenje Server
- Pyomo-optimeringsmodelleringsspråk
- Bonmin solver
- TFoCS-lösare för Spark
Relaterade resurser
Relaterad detaljhandelsvägledning:
- Lösningar för detaljhandeln
- Migrera din e-handelslösning till Azure
- Visuell sökning i detaljhandeln med Azure Cosmos DB
Relaterade arkitekturer: