Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Du kan migrera dina data, arbetsbelastningar och program från Azure Data Lake Storage Gen1 till Azure Data Lake Storage Gen2. Den här artikeln förklarar den rekommenderade migreringsmetoden och beskriver de olika migreringsmönstren och när var och en ska användas. För enklare läsning använder den här artikeln termen Gen1 för att referera till Azure Data Lake Storage Gen1 och termen Gen2 för att referera till Azure Data Lake Storage Gen2.
Anteckning
Azure Data Lake Storage Gen1 har nu dragits tillbaka. Se pensionsmeddelandet här. Data Lake Storage Gen1-resurser är inte längre tillgängliga.
Azure Data Lake Storage Gen2 bygger på Azure Blob Storage och tillhandahåller en uppsättning funktioner som är dedikerade till stordataanalys. Data Lake Storage Gen2 kombinerar funktioner från Azure Data Lake Storage Gen1, till exempel filsystemssemantik, katalog- och filnivåsäkerhet och skalning med låg kostnad, nivåindelad lagring, hög tillgänglighet/haveriberedskap från Azure Blob Storage.
Anteckning
Eftersom Gen1 och Gen2 är olika tjänster finns det ingen möjlighet till direktuppgradering. Information om hur du förenklar migreringen till Gen2 med hjälp av Azure Portal finns i Migrera Azure Data Lake Storage från Gen1 till Gen2 med hjälp av Azure Portal.
Rekommenderad strategi
För att migrera från Gen1 till Gen2 rekommenderar vi följande metod.
Steg 1: Utvärdera beredskap
Steg 2: Förbered migreringen
Steg 3: Migrera data och programarbetsbelastningar
Steg 4: Övergång från Gen1 till Gen2
Steg 1: Utvärdera beredskap
Lär dig mer om Data Lake Storage Gen2-erbjudandet, dess fördelar, kostnader och allmän arkitektur.
Jämför funktionerna i Gen1 med funktionerna i Gen2.
Granska en lista över kända problem för att bedöma eventuella funktionsluckor.
Gen2 stöder bloblagringsfunktioner som diagnostikloggning, åtkomstnivåer och livscykelhanteringsprinciper för Blob Storage. Om du är intresserad av att använda någon av dessa funktioner kan du läsa den aktuella supportnivån.
Granska det aktuella tillståndet för Azures ekosystemstöd för att säkerställa att Gen2 stöder alla tjänster som dina lösningar är beroende av.
Steg 2: Förbered migreringen
Identifiera de datauppsättningar som du ska migrera.
Ta tillfället i akt att rensa datauppsättningar som du inte längre använder. Om du inte planerar att migrera alla dina data samtidigt, använd den här möjligheten för att identifiera logiska grupper av data som du kan migrera i faser.
Utför en åldrande analys (eller liknande) på ditt Gen1-konto för att identifiera vilka filer eller mappar som finns kvar i lagret under en längre tid eller kanske håller på att bli föråldrade.
Fastställa vilken inverkan en migrering kommer att ha på ditt företag.
Tänk till exempel på om du har råd med några stilleståndstider medan migreringen sker. Dessa överväganden kan hjälpa dig att identifiera ett lämpligt migreringsmönster och välja de lämpligaste verktygen.
Skapa en migreringsplan.
Vi rekommenderar dessa migreringsmönster. Du kan välja något av dessa mönster, kombinera dem eller utforma ett eget eget mönster.
Steg 3: Migrera data, arbetsbelastningar och program
Migrera data, arbetsbelastningar och program med det mönster som du föredrar. Vi rekommenderar att du validerar scenarier stegvis.
Skapa ett lagringskonto och aktivera funktionen för hierarkiskt namnområde.
Migrera dina data.
Konfigurera tjänster i dina arbetsbelastningar så att de pekar på din Gen2-slutpunkt.
För HDInsight-kluster kan du lägga till konfigurationsinställningar för lagringskontot i filen %HADOOP_HOME%/conf/core-site.xml. Om du planerar att migrera externa Hive-tabeller från Gen1 till Gen2 måste du lägga till lagringskontoinställningar i filen %HIVE_CONF_DIR%/hive-site.xml.
Du kan ändra inställningarna för varje fil med hjälp av Apache Ambari. Information om hur du hittar inställningar för lagringskonton finns i Hadoop Azure Support: ABFS – Azure Data Lake Storage Gen2. I det här exemplet används inställningen
fs.azure.account.keyför att aktivera auktorisering av delad nyckel:<property> <name>fs.azure.account.key.abfswales1.dfs.core.windows.net</name> <value>your-key-goes-here</value> </property>Länkar till artiklar som hjälper dig att konfigurera HDInsight, Azure Databricks och andra Azure-tjänster att använda Gen2 finns i Azure-tjänster som stöder Azure Data Lake Storage Gen2.
Uppdatera program så att de använder Gen2-API:er. Se följande guider:
Uppdatera skript för att använda PowerShell-cmdletar för Data Lake Storage Gen2 och Azure CLI-kommandon.
Sök efter URI-referenser som innehåller strängen
adl://i kodfiler eller i Databricks Notebooks, Apache Hive HQL-filer eller någon annan fil som används som en del av dina arbetsbelastningar. Ersätt dessa referenser med den Gen2-formaterade URI: n för ditt nya lagringskonto. Till exempel: Gen1-URI:n:adl://mydatalakestore.azuredatalakestore.net/mydirectory/myfilekan bliabfss://myfilesystem@mydatalakestore.dfs.core.windows.net/mydirectory/myfile.Konfigurera säkerheten för ditt konto så att den omfattar Azure-roller, säkerhet på fil- och mappnivå samt Azure Storage-brandväggar och virtuella nätverk.
Steg 4: Övergång från Gen1 till Gen2
När du är säker på att dina program och arbetsbelastningar är stabila på Gen2 kan du börja använda Gen2 för att uppfylla dina affärsscenarier. Stäng av eventuella återstående pipelines som körs på Gen1 och avveckla ditt Gen1-konto.
Gen1- och Gen2-funktioner
I den här tabellen jämförs funktionerna i Gen1 med gen2-funktionerna.
Mönster för Gen1 till Gen2
Välj ett migreringsmönster och ändra sedan det mönstret efter behov.
| Migreringsmönster | Detaljer |
|---|---|
| Lift and Shift | Det enklaste mönstret. Perfekt om dina datapipelines har råd med stilleståndstid. |
| Inkrementell kopia | Liknar lyft och skift, men med mindre stilleståndstid. Perfekt för stora mängder data som tar längre tid att kopiera. |
| Dubbel rörledning | Perfekt för pipelines som inte har råd med stilleståndstid. |
| Dubbelriktad synkronisering | Liknar dubbel pipeline, men med en mer stegvis metod som passar för mer komplicerade pipelines. |
Låt oss ta en närmare titt på varje mönster.
Lift- och skiftmönster
Det här är det enklaste mönstret.
Stoppa alla skrivningar till Gen1.
Flytta data från Gen1 till Gen2. Vi rekommenderar Azure Data Factory eller med hjälp av Azure Portal. ACL:er kopieras tillsammans med datan.
Rikta insamlingsoperationer och arbetsflöden till Gen2.
Inaktivera Gen1.
Kolla in vår exempelkod för lift and shift-mönstret i vårt Lift and Shift-migreringsexempel.
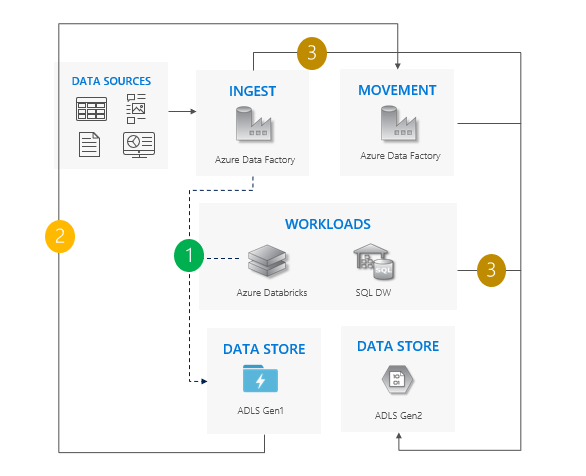
Överväganden för att använda lift- och skiftmönstret
Övergång från Gen1 till Gen2 för alla arbetsbelastningar samtidigt.
Förvänta dig avbrott under migreringen och övergångsperioden.
Perfekt för pipelines som kan tolerera stilleståndstid och där alla appar kan uppgraderas samtidigt.
Tips
Överväg att använda Azure Portal för att förkorta stilleståndstiden och minska antalet steg som krävs för att slutföra migreringen.
Inkrementellt kopieringsmönster
Börja flytta data från Gen1 till Gen2. Vi rekommenderar Azure Data Factory. ACL:er kopieras tillsammans med datan.
Kopiera inkrementellt nya data från Gen1.
När alla data har kopierats stoppar du alla skrivningar till Gen1 och pekar arbetsbelastningar på Gen2.
Inaktivera Gen1.
Kolla in vår exempelkod för det inkrementella kopieringsmönstret i vårt exempel på inkrementell kopieringsmigrering.
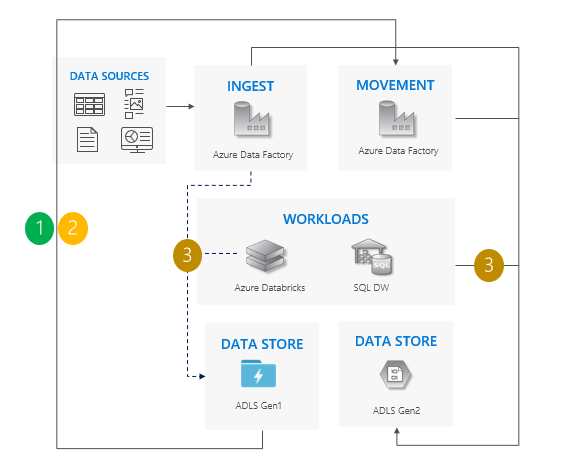
Överväganden för att använda det inkrementella kopieringsmönstret:
Övergång från Gen1 till Gen2 för alla arbetslaster samtidigt.
Förvänta dig driftstopp endast under övergångsperioden.
Perfekt för pipelines där alla applikationer uppgraderas samtidigt, men datakopieringen kräver mer tid.
Mönster för dubbel pipeline
Flytta data från Gen1 till Gen2. Vi rekommenderar Azure Data Factory. ACL:er kopierar med data.
Mata in nya data till både Gen1 och Gen2.
Rikta arbetsuppgifter till Gen2.
Stoppa alla skrivningar till Gen1 och inaktivera sedan Gen1.
Kolla in vår exempelkod för det dubbla pipelinemönstret i vårt dual pipeline-migreringsexempel.
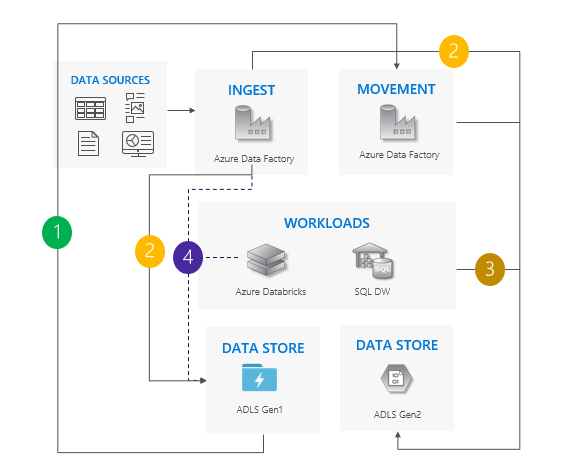
Överväganden för att använda det dubbla pipelinemönstret:
Gen1- och Gen2-pipelines körs sida vid sida.
Stöder noll stilleståndstid.
Perfekt i situationer där dina arbetsbelastningar och program inte har råd med driftstopp och du kan mata in i båda lagringskontona.
Mönster för dubbelriktad synkronisering
Konfigurera dubbelriktad replikering mellan Gen1 och Gen2. Vi rekommenderar WanDisco. Den erbjuder en reparationsfunktion för befintliga data.
När alla flyttningar är klara stoppar du alla skrivningar till Gen1 och inaktiverar dubbelriktad replikering.
Inaktivera Gen1.
Kolla in vår exempelkod för det dubbelriktade synkroniseringsmönstret i vårt migreringsexempel för dubbelriktad synkronisering.
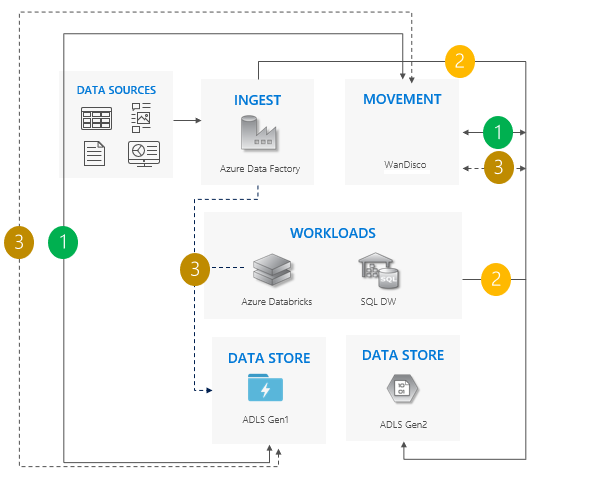
Överväganden för att använda mönstret för dubbelriktad synkronisering:
Perfekt för komplexa scenarier som omfattar ett stort antal pipelines och beroenden där en stegvis metod kan vara mer meningsfull.
Migreringsinsatsen är omfattande, men den ger stöd för Gen1 och Gen2 sida vid sida.
Nästa steg
- Lär dig mer om de olika delarna i att konfigurera säkerhet för ett lagringskonto. Mer information finns i Säkerhetsguide för Azure Storage.
- Optimera prestandan för Data Lake Store. Se Optimera Azure Data Lake Storage Gen2 för prestanda
- Granska metodtipsen för att hantera din Data Lake Store. Se Metodtips för att använda Azure Data Lake Storage Gen2