Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
| Mayana Pereira | Scott Christiansen |
|---|---|
| CELA-datavetenskap | Kundsäkerhet och förtroende |
| Microsoft | Microsoft |
Abstrakt – Att identifiera rapporter om säkerhetsfel (SBR) är ett viktigt steg i livscykeln för programvaruutveckling. I övervakade maskininlärningsbaserade metoder är det vanligt att anta att hela felrapporter är tillgängliga för träning och att deras etiketter är brusfria. Såvitt vi vet är detta den första studien som visar att korrekt etikettförutsägelse är möjlig för SBR även när endast titeln är tillgänglig och i närvaro av etikettbrus.
indexvillkor – Maskininlärning, felmärkning, brus, rapport om säkerhetsfel, buggdatabaser
Jag. INTRODUKTION
Att identifiera säkerhetsproblem bland rapporterade buggar är ett trängande behov bland programvaruutvecklingsteamen, eftersom sådana problem kräver snabbare korrigeringar för att uppfylla efterlevnadskraven och säkerställa integriteten för programvara och kunddata.
Maskininlärning och verktyg för artificiell intelligens lovar att göra programvaruutvecklingen snabbare, smidig och korrekt. Flera forskare har tillämpat maskininlärning på problemet med att identifiera säkerhetsbuggar [2], [7], [8], [18]. Tidigare publicerade studier har antagit att hela felrapporten är tillgänglig för träning och bedömning av en maskininlärningsmodell. Detta är inte nödvändigtvis fallet. Det finns situationer där hela felrapporten inte kan göras tillgänglig. Buggrapporten kan till exempel innehålla lösenord, personligt identifierande information (PII) eller andra typer av känsliga data – ett ärende som vi för närvarande står inför hos Microsoft. Det är därför viktigt att fastställa hur bra identifiering av säkerhetsfel kan utföras med mindre information, till exempel när endast felrapportens rubrik är tillgänglig.
Dessutom innehåller buggdatabaser ofta felmärkta poster [7]: felrapporter som inte är säkerhetsrelaterade och vice versa. Det finns flera orsaker till förekomsten av felmärkning, allt från utvecklingsteamets brist på expertis inom säkerhet, till att vissa problem är suddiga. Till exempel kan det hända att icke-säkerhetsrelaterade buggar utnyttjas på ett indirekt sätt som leder till säkerhetsmässiga konsekvenser. Detta är ett allvarligt problem eftersom felmärkningen av SBRs resulterar i att säkerhetsexperter måste granska buggdatabasen manuellt i en dyr och tidskrävande ansträngning. Att förstå hur brus påverkar olika klassificerare och hur robusta (eller bräckliga) olika maskininlärningstekniker är i närvaro av datamängder som är förorenade med olika typer av brus är ett problem som måste åtgärdas för att automatiskt klassificera programvarutekniken.
Preliminärt arbete hävdar att bugglagringsplatser i sig är bullriga och att bruset kan ha en negativ effekt på prestandamaskininlärningsklassificerarna [7]. Det saknas dock systematiska och kvantitativa studier av hur olika nivåer och typer av brus påverkar prestandan hos olika övervakade maskininlärningsalgoritmer för problemet med att identifiera rapporter om säkerhetsfel .
I den här studien visar vi att klassificeringen av felrapporter kan utföras även när enbart titeln är tillgänglig för träning och bedömning. Såvitt vi vet är detta det allra första arbetet att göra det. Dessutom tillhandahåller vi den första systematiska studien av effekten av brus i klassificering av buggrapporter. Vi gör en jämförande studie av robusthet i tre maskininlärningstekniker (logistisk regression, naiva Bayes och AdaBoost) mot klassoberoende brus.
Även om det finns vissa analysmodeller som fångar den allmänna påverkan av brus för några enkla klassificerare [5], [6], ger dessa resultat inte snäva gränser för brusets effekt på precisionen och är endast giltiga för en viss maskininlärningsteknik. En korrekt analys av effekten av brus i maskininlärningsmodeller utförs vanligtvis genom att köra beräkningsexperiment. Sådana analyser har gjorts för flera scenarier som sträcker sig från programvarumätningsdata [4], till klassificering av satellitbilder [13] och medicinska data [12]. Men dessa resultat kan inte översättas till vårt specifika problem på grund av dess stora beroende av datamängdernas natur och det underliggande klassificeringsproblemet. Såvitt vi vet finns det inga publicerade resultat om problemet med effekten av brusande datamängder på klassificering av säkerhetsfelrapporter i synnerhet.
VÅRA FORSKNINGSBIDRAG:
Vi tränar klassificerare för identifiering av rapporter om säkerhetsfel (SBR) baserat enbart på rapporternas titel. Så vitt vi vet är detta den första gången det görs. Tidigare arbeten använde antingen den fullständiga felrapporten eller förbättrade felrapporten med ytterligare kompletterande funktioner. Klassificering av buggar som enbart baseras på panelen är särskilt relevant när de fullständiga felrapporterna inte kan göras tillgängliga på grund av sekretessproblem. Till exempel är det ökända fallet med buggrapporter som innehåller lösenord och andra känsliga data.
Vi ger också den första systematiska studien av etiketten brustolerans för olika maskininlärningsmodeller och tekniker som används för automatisk klassificering av SBRs. Vi gör en jämförande studie av robusthet i tre distinkta maskininlärningstekniker (logistisk regression, naiva Bayes och AdaBoost) mot klassberoende och klassoberoende brus.
Resten av dokumentet presenteras på följande sätt: I avsnitt II presenterar vi några av de tidigare verken i litteraturen. I avsnitt III beskriver vi datauppsättningen och hur data bearbetas i förväg. Metoden beskrivs i avsnitt IV och resultaten av våra experiment som analyserats i avsnitt V. Slutligen presenteras våra slutsatser och framtida arbeten i VI.
II. FÖREGÅENDE ARBETEN
MASKININLÄRNINGSTILLÄMPNINGAR FÖR BUGGARKIV.
Det finns en omfattande litteratur i att tillämpa textutvinning, bearbetning av naturligt språk och maskininlärning på bugglagringsplatser i ett försök att automatisera besvärliga uppgifter som identifiering av säkerhetsfel [2], [7], [8], [18], identifiering av buggdubblett [3], buggtriage [1], [11], för att nämna några program. Helst kan äktenskapet mellan maskininlärning (ML) och bearbetning av naturligt språk potentiellt minska det manuella arbete som krävs för att kurera buggdatabaser, förkorta den tid som krävs för att utföra dessa uppgifter och öka resultatens tillförlitlighet.
I [7] föreslår författarna en modell för naturligt språk för att automatisera klassificeringen av SBR baserat på beskrivningen av buggen. Författarna extraherar ett ordförråd från alla buggbeskrivningar i träningsdatauppsättningen och kurerar den manuellt i tre listor med ord: relevanta ord, stoppord (vanliga ord som verkar irrelevanta för klassificering) och synonymer. De jämför prestandan för en säkerhetsbuggklassificerare som tränats på data som bedömts av säkerhetstekniker, och en klassificerare tränad på data som märkts av generella buggrapportörer. Även om deras modell är klart effektivare när den tränas på data som granskas av säkerhetstekniker, baseras den föreslagna modellen på en manuellt härledd vokabulär, vilket gör den beroende av mänsklig kuration. Dessutom finns det ingen analys av hur olika brusnivåer påverkar deras modell, hur olika klassificerare reagerar på brus och om brus i någon av klasserna påverkar prestandan på olika sätt.
Zou et. al [18] använder sig av flera typer av information som finns i en buggrapport som omfattar icke-textfält i en buggrapport (metafunktioner, t.ex. tid, allvarlighetsgrad och prioritet) och textinnehållet i en buggrapport (textfunktioner, dvs. texten i sammanfattningsfält). Baserat på dessa funktioner skapar de en modell för att automatiskt identifiera SBR:erna via bearbetning av naturligt språk och maskininlärningstekniker. I [8] utför författarna en liknande analys, men dessutom jämför de prestandan hos övervakade och oövervakade maskininlärningstekniker och studerar hur mycket data som behövs för att träna sina modeller.
I [2] utforskar författarna också olika maskininlärningstekniker för att klassificera buggar som SBRs eller NSBRs (Non-Security Bug Report) baserat på deras beskrivningar. De föreslår en pipeline för databehandling och modellträning baserat på TFIDF. De jämför den föreslagna pipelinen med en modell baserad på "bag-of-words" och naive Bayes. Wijayasekara et al. [16] använde också textutvinningstekniker för att skapa egenskapsvektorn för varje buginberetning baserat på vanliga ord för att identifiera dolda påverkansbuggar (HIB). Yang et al. [17] påstod sig identifiera buggrapporter med hög påverkan (t.ex. SBA) med hjälp av Term Frequency (TF) och naiva Bayes. I [9] föreslår författarna en modell för att förutsäga allvarlighetsgraden för en bugg.
ETIKETTFEL
Problemet med att hantera datamängder med etikettbrus har studerats i stor utsträckning. Frenay och Verleysen föreslår en etikettbrustaxonomi i [6], för att skilja mellan olika typer av bullriga etiketter. Författarna föreslår tre olika typer av brus: etikettbrus som inträffar oberoende av den sanna klassen och värdena för instansfunktionerna; etikettbrus som endast beror på den sanna etiketten; och etikettbrus där sannolikheten för felmärkning också beror på funktionsvärdena. I vårt arbete studerar vi de två första typerna av brus. Ur ett teoretiskt perspektiv minskar etikettbruset vanligtvis en modells prestanda [10], förutom i vissa specifika fall [14]. I allmänhet förlitar sig robusta metoder på undvikande av överanpassning för att hantera etikettbrus [15]. Undersökningen av bruseffekter i klassificeringen har gjorts tidigare inom många områden såsom klassificering av satellitbilder [13], klassificering av programvarukvalitet [4] och klassificering av medicinsk domän [12]. Såvitt vi vet finns det inga publicerade verk som studerar den exakta kvantifieringen av effekterna av bullriga etiketter i problemet med SBRs-klassificering. I det här scenariot har den exakta relationen mellan brusnivåer, brustyper och prestandaförsämring inte upprättats. Dessutom är det värt att förstå hur olika klassificerare beter sig i närvaro av brus. Mer allmänt känner vi inte till något arbete som systematiskt studerar effekten av brusiga datauppsättningar på prestandan hos olika maskininlärningsalgoritmer i samband med programfelrapporter.
III. BESKRIVNING AV DATAUPPSÄTTNING
Vår datauppsättning består av 1 073 149 feltitlar, varav 552 073 motsvarar SBR och 521 076 motsvarar NSBR. Data samlades in från olika team i Microsoft under åren 2015, 2016, 2017 och 2018. Alla etiketter hämtades av signaturbaserade felverifieringssystem eller märkta av människa. Buggtitlar i vår datauppsättning är mycket korta texter som innehåller cirka 10 ord, med en översikt över problemet.
A. Dataförbearbetning Vi parsar varje felrubrik med dess tomma blanksteg, vilket resulterar i en lista med token. Vi bearbetar varje lista med token enligt följande:
Ta bort alla tokens som är filsökvägar
Dela upp token där följande symboler finns: { , (, ), -, }, {, [, ], }
Ta bort stoppord , token som endast består av numeriska tecken och token som visas mindre än 5 gånger i hela corpus.
IV. METODIK
Träningsprocessen för våra maskininlärningsmodeller består av två huvudsakliga steg: kodning av data i funktionsvektorer och utbildning av övervakade maskininlärningsklassificerare.
A. Funktionsvektorer och maskininlärningstekniker
Den första delen handlar om att koda data i funktionsvektorer med hjälp av algoritmen term frequencyinverse document frequency (TF-IDF), som används i [2]. TF-IDF är en informationshämtningsteknik som väger en termfrekvens (TF) och dess omvända dokumentfrekvens (IDF). Varje ord eller term har sina respektive TF- och IDF-poäng. Algoritmen TF-IDF tilldelar ordet betydelse baserat på hur många gånger det visas i dokumentet, och ännu viktigare är att den kontrollerar hur relevant nyckelordet är i hela samlingen med rubriker i datauppsättningen. Vi tränade och jämförde tre klassificeringstekniker: naiva Bayes (NB), förstärkta beslutsträd (AdaBoost) och logistisk regression (LR). Vi har valt dessa tekniker eftersom de har visat sig fungera bra för den relaterade uppgiften att identifiera rapporter om säkerhetsfel baserat på hela rapporten i litteraturen. Dessa resultat bekräftades i en preliminär analys där dessa tre klassificerare överträffade stödvektormaskiner och slumpmässiga skogar. I våra experiment använder vi scikit-learn-biblioteket för kodning och modellträning.
B. Typer av brus
Bruset som studeras i det här arbetet avser brus i klassetiketten i träningsdatan. I närvaro av sådant brus påverkas därför inlärningsprocessen och den resulterande modellen av felmärkta exempel. Vi analyserar effekten av olika brusnivåer som tillämpas på klassinformationen. Typer av etikettbrus har diskuterats tidigare i litteraturen med hjälp av olika terminologi. I vårt arbete analyserar vi effekterna av två olika etikettbrus i våra klassificerare: klassoberoende etikettbrus, som introduceras genom att välja instanser slumpmässigt och vända etiketten; och klassberoende brus, där klasser har olika sannolikhet att vara bullriga.
a) klassoberoende brus: Klassoberoende brus refererar till bruset som inträffar oberoende av instansernas sanna klass. I den här typen av brus är sannolikheten för felmärkning pbr densamma för alla instanser i datauppsättningen. Vi introducerar klassoberoende brus i våra datauppsättningar genom att vända varje etikett i vår datauppsättning slumpmässigt med sannolikhet pbr.
b) klassberoende störning: Klassberoende störning hänvisar till störningen som beror på den sanna klassen hos instanserna. I den här typen av brus är sannolikheten för felmärkning i klass-SBR psbr och sannolikheten för felmärkning i klass NSBR är pnsbr. Vi introducerar klassberoende brus i vår datauppsättning genom att ändra varje post i datauppsättningen där den sanna etiketten är SBR med sannolikhet psbr. På motsvarande sätt byter vi klassetiketten för NSBR-instanser med sannolikheten pnsbr.
c) Brus av en klass: Brus av en klass är ett särskilt fall av klassberoende brus, där pnsbr = 0 och psbr> 0. Observera att för klassoberoende brus har vi psbr = pnsbr = pbr.
C. Brusgenerering
Våra experiment undersöker effekten av olika brustyper och nivåer i utbildningen av SBR-klassificerare. I våra experiment anger vi 25% av datauppsättningen som testdata, 10% som validering och 65% som träningsdata.
Vi lägger till brus i datauppsättningarna för träning och validering för olika nivåer av pbr, psbr och pnsbr . Vi gör inga ändringar i testdatauppsättningen. De olika brusnivåerna som används är P = {0,05 × i|0 < i < 10}.
I klassoberoende brusexperiment gör vi följande för pbr ∈ P:
Generera brus för tränings- och valideringsdatauppsättningar.
Träna logistisk regression, naiva Bayes- och AdaBoost-modeller med hjälp av träningsdatauppsättning (med brus); * Finjustera modeller med hjälp av valideringsdatauppsättningen (med brus);
Testa modeller med hjälp av testdatauppsättning (brusfri).
I klassberoende brusexperiment gör vi följande för psbr ∈ P och pnsbr ∈ P för alla kombinationer av psbr och pnsbr:
Generera brus för tränings- och valideringsdatauppsättningar.
Träna logistisk regression, naiva Bayes- och AdaBoost-modeller med hjälp av träningsdatauppsättning (med brus);
Finjustera modeller med hjälp av valideringsdatauppsättningen (med brus);
Testa modeller med hjälp av testdatauppsättning (brusfri).
V. EXPERIMENTELLA RESULTAT
I det här avsnittet analyserar du resultaten av experiment som utförts enligt den metod som beskrivs i avsnitt IV.
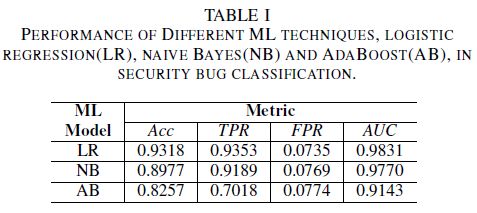
a) Modellprestanda utan brus i träningsdatauppsättningen: Ett av bidragen i det här dokumentet är förslaget till en maskininlärningsmodell för att identifiera säkerhetsbuggar genom att endast använda buggens titel som data för beslutsfattande. Detta möjliggör träning av maskininlärningsmodeller även när utvecklingsteam inte vill dela felrapporter i sin helhet på grund av förekomsten av känsliga data. Vi jämför prestanda för tre maskininlärningsmodeller när de tränas med endast buggtitlar.
Den logistiska regressionsmodellen är den bäst presterande klassificeraren. Det är klassificeraren med det högsta AUC-värdet, 0,9826, som återkallar 0,9353 för ett FPR-värde på 0,0735. Den naiva Bayes-klassificeraren uppvisar något lägre prestanda än den logistiska regressionsklassificeraren, med en AUC på 0,9779 och en återkallelse på 0,9189 för en FPR på 0,0769. AdaBoost-klassificeraren har sämre prestanda jämfört med de två tidigare nämnda klassificerarna. Det uppnår en AUC på 0,9143 och en återkallningsgrad av 0,7018 för en 0,0774 FPR. Området under ROC-kurvan (AUC) är ett bra mått för att jämföra prestanda för flera modeller, eftersom det sammanfattas i ett enda värde TPR jämfört med FPR-relationen. I den efterföljande analysen begränsar vi vår jämförande analys till AUC-värden.
A. Klassbrus: enkelklass
Man kan föreställa sig ett scenario där alla buggar tilldelas klassen NSBR som standard, och en bugg endast tilldelas klass-SBR om det finns en säkerhetsexpert som granskar fellagringsplatsen. Det här scenariot representeras i en experimentell inställning med en enda klass, där vi antar att pnsbr = 0 och 0 < psbr< 0,5.
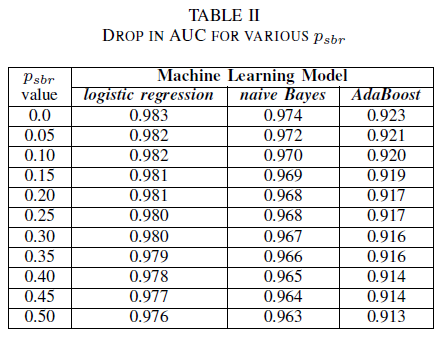
Från tabell II ser vi en mycket liten inverkan i AUC för alla tre klassificerare. AUC-ROC från en modell som tränats på psbr = 0 jämfört med en AUC-ROC av en modell där psbr = 0,25 skiljer sig med 0,003 för logistisk regression, 0,006 för naiva Bayes och 0,006 för AdaBoost. När det gäller psbr = 0,50 skiljer sig AUC som mäts för var och en av modellerna från modellen som tränats med psbr = 0 x 0,007 för logistisk regression, 0,011 för naiva Bayes och 0,010 för AdaBoost. Logistisk regressionsklassificerare som tränats i närvaro av enklassbrus presenterar den minsta variationen i dess AUC-mått, dvs. ett mer robust beteende jämfört med våra naiva Bayes- och AdaBoost-klassificerare.
B. Klassbrus: klassoberoende
Vi jämför prestandan för våra tre klassificerare i det fall där träningsuppsättningen är påverkad av ett klassoberoende brus. Vi mäter AUC för varje modell som tränats med olika nivåer av pbr i träningsdatan.
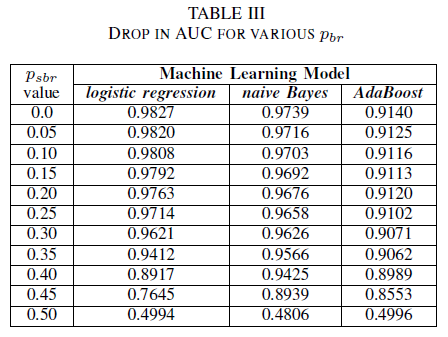
I tabell III ser vi en minskning av AUC-ROC för varje brusökning i experimentet. Den AUC-ROC som mäts från en modell som tränats på brusfria data jämfört med en AUC-ROC av modellen som tränats med klassoberoende brus med pbr = 0,25 skiljer sig med 0,011 för logistisk regression, 0,008 för naiva Bayes och 0,0038 för AdaBoost. Vi observerar att etikettbrus inte påverkar AUC för naiva Bayes- och AdaBoost-klassificerare avsevärt när brusnivåerna är lägre än 40%. Å andra sidan påverkas den logistiska regressionsklassificeraren i AUC-måttet vid märkningsbrusnivåer över 30%.
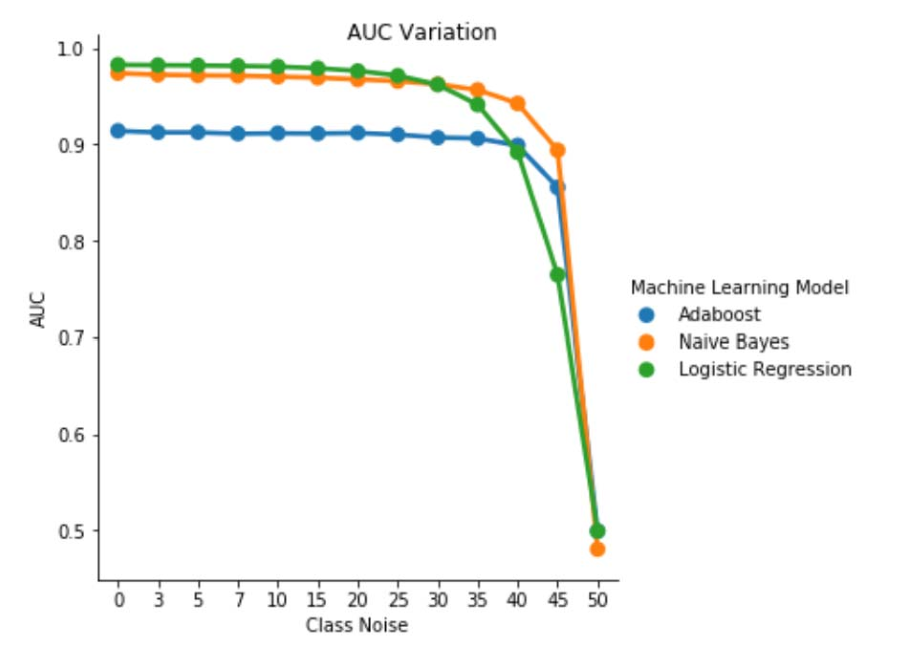
Bild 1. Variation av AUC-ROC i klassoberoende brus. För en brusnivå pbr =0,5 fungerar klassificeraren som en slumpmässig klassificerare, d.v.s. AUC≈0.5. Men vi kan observera att för lägre brusnivåer (pbr ≤0.30) ger den logistiska regressionsläraren en bättre prestanda jämfört med de andra två modellerna. Men för 0,35≤ pbr ≤0,45 naiv Bayes learner presenterar bättre AUCROC-mått.
C. Klassbrus: klassberoende
I den sista uppsättningen experiment överväger vi ett scenario där olika klasser innehåller olika brusnivåer, d.v.s. psbr ≠ pnsbr. Vi ökar systematiskt psbr och pnsbr med 0,05 var för sig i träningsdatan och observerar de tre klassificerarnas beteendeförändring.
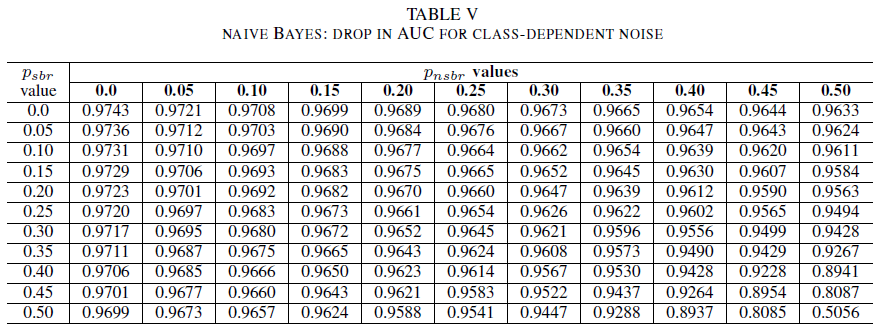
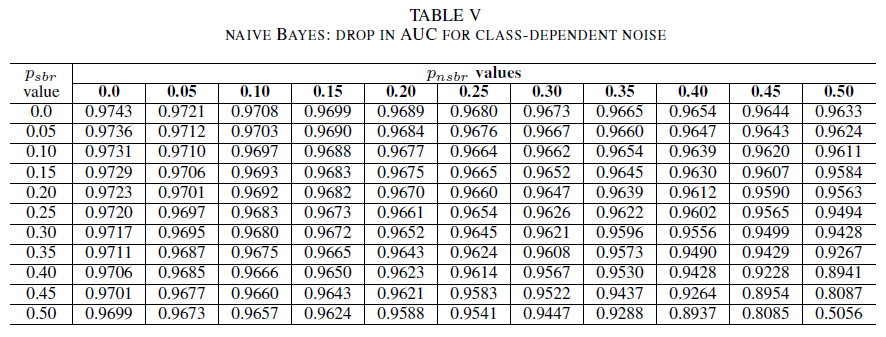
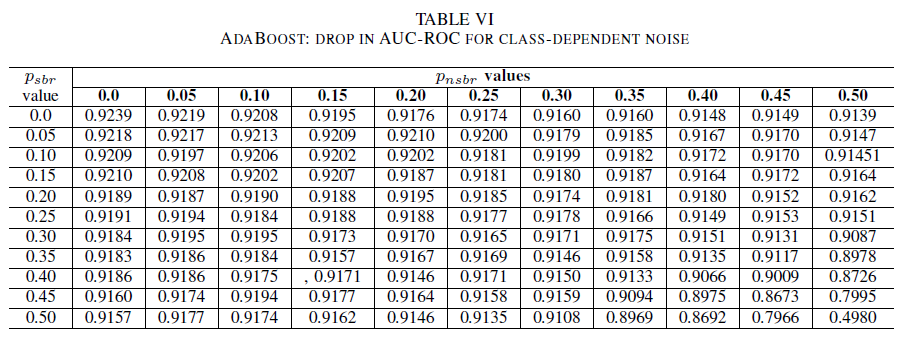
TabellerNA IV, V, VI visar variationen av AUC eftersom bruset ökar i olika nivåer i varje klass för logistisk regression i tabell IV, för naiva Bayes i tabell V och för AdaBoost i tabell VI. För alla klassificerare märker vi en påverkan på AUC-måttet när båda klasserna innehåller brusnivå över 30%. naive Bayes beterar sig mer robust. Effekten på AUC är mycket liten även när etikettens 50% i den positiva klassen vänds, förutsatt att den negativa klassen innehåller 30% brusetiketter eller mindre. I det här fallet är minskningen i AUC 0,03. AdaBoost presenterade det mest robusta beteendet för alla tre klassificerare. En betydande förändring i AUC sker endast för brusnivåer som är större än 45% i båda klasserna. I så fall börjar vi observera ett AUC-förfall större än 0,02.
D. Om förekomsten av residualbrus i den ursprungliga datauppsättningen
Vår datauppsättning har märkts av signaturbaserade automatiserade system och av mänskliga experter. Dessutom har alla buggrapporter granskats ytterligare och stängts av mänskliga experter. Vi förväntar oss att mängden brus i vår datamängd är minimal och inte statistiskt signifikant, men förekomsten av residualbrus ogiltigförklarar inte våra slutsatser. Som ett exempel förutsätter vi att den ursprungliga datamängden är skadad av ett klassoberoende brus som är lika med 0 < p < 1/2 oberoende och identiskt distribuerad (i.i.d) för varje postering.
Om vi utöver det ursprungliga bruset lägger till ett klassoberoende brus med sannolikhet pbr i.i.d, blir det resulterande bruset per post p∗ = p(1 − pbr )+(1 − p)pbr . För 0 < p,pbr< 1/2 har vi att det faktiska bruset per etikett p∗ är strikt större än bruset vi artificiellt lägger till i datauppsättningen pbr . Därför skulle prestanda för våra klassificerare vara ännu bättre om de tränades med en helt brusfri datauppsättning (p = 0) i första hand. Sammanfattningsvis innebär förekomsten av residualbrus i den faktiska datamängden att motståndskraften mot brus från våra klassificerare är bättre än de resultat som presenteras här. Om residualbruset i vår datamängd var statistiskt relevant skulle AUC för våra klassificerare dessutom bli 0,5 (en slumpmässig gissning) för en brusnivå som är strikt mindre än 0,5. Vi observerar inte sådant beteende i våra resultat.
VI. SLUTSATSER OCH FRAMTIDA ARBETEN
Vårt bidrag i detta dokument är dubbelt.
För det första har vi visat möjligheten att klassificera säkerhetsrapporter enbart baserat på felrapportens rubrik. Detta är särskilt relevant i scenarier där hela felrapporten inte är tillgänglig på grund av sekretessbegränsningar. I vårt fall innehöll buggrapporterna till exempel privat information som lösenord och kryptografiska nycklar och var inte tillgängliga för träning av klassificerarna. Vårt resultat visar att SBR-identifiering kan utföras med hög noggrannhet även när endast rapportrubriker är tillgängliga. Vår klassificeringsmodell som använder en kombination av TF-IDF och logistisk regression utförs på en AUC på 0,9831.
För det andra analyserade vi effekten av felmärkta tränings- och valideringsdata. Vi jämförde tre välkända maskininlärningsklassificeringstekniker (naiva Bayes, logistisk regression och AdaBoost) med avseende på deras robusthet mot olika brustyper och brusnivåer. Alla tre klassificerarna är robusta för brus av en klass. Brus i träningsdata har ingen betydande effekt på den resulterande klassificeraren. Minskningen av AUC är mycket liten ( 0,01) för en brusnivå på 50%. För brus som finns i båda klasserna och är klassoberoende presenterar naiva Bayes- och AdaBoost-modeller endast betydande variationer i AUC när de tränas med en datauppsättning med brusnivåer som är större än 40%.
Slutligen påverkar klassberoende brus AUC avsevärt endast när det finns mer än 35% brus i båda klasserna. AdaBoost visade mest robusthet. Effekten på AUC är mycket liten även om den positiva klassen har 50% av sina brusiga etiketter, förutsatt att den negativa klassen innehåller 45% brusiga etiketter eller färre. I det här fallet är minskningen i AUC mindre än 0,03. Såvitt vi vet är detta den första systematiska studien om effekten av bullriga datamängder för identifiering av säkerhetsfelrapporter.
FRAMTIDA ARBETEN
I den här artikeln har vi påbörjat en systematisk studie av effekterna av brus i prestanda hos maskininlärningsklassificerare för identifiering av säkerhetsbuggar. Det finns flera intressanta fortsättningar på det här arbetet, bland annat att undersöka effekten av bullriga datamängder för att fastställa allvarlighetsgraden för en säkerhetsbugg. Förstå effekten av klassobalans på de tränade modellernas motståndskraft mot buller. förstå effekten av brus som introduceras på ett fientligt sätt i datauppsättningen.
REFERENSER
[1] John Anvik, Lyndon Hiew och Gail C Murphy. Vem ska åtgärda felet? I handlingarna från den 28:e internationella konferensen om mjukvaruteknik, sidorna 361–370. ACM, 2006.
[2] Diksha Behl, Sahil Handa och Anuja Arora. Ett verktyg för buggutvinning för att identifiera och analysera säkerhetsbuggar med hjälp av naiva bayes och tf-idf. I Optimization, Reliability, and Information Technology (ICROIT), 2014 internationella konferensen om, sidor 294–299. IEEE, 2014.
[3] Nicolas Bettenburg, Rahul Premraj, Thomas Zimmermann och Sunghun Kim. Egentligen, anses duplicerade felrapporter vara skadliga? I Software maintenance, 2008. ICSM 2008. IEEE internationella konferensen om, sidor 337–345. IEEE, 2008.
[4] Andres Folleco, Taghi M Khoshgoftaar, Jason Van Hulse och Lofton Bullard. Identifiera elever som är robusta för data av låg kvalitet. I Återanvändning och integrering av information, 2008. IRI 2008. IEEE International Conference on, sidor 190–195. IEEE, 2008.
[5] Benoˆıt Frenay.' Osäkerhet och etikettbrus i maskininlärning. Avhandling, Katolska universitetet i Louvain, Louvain-la-Neuve, Belgien, 2013.
[6] Benoˆıt Frenay och Michel Verleysen. Klassificering i närvaro av etikettbrus: en undersökning. IEEE-transaktioner i neurala nätverk och inlärningssystem, 25(5):845–869, 2014.
[7] Michael Gegick, Pete Rotella och Tao Xie. Identifiering av rapporter om säkerhetsfel via textutvinning: En industriell fallstudie. I Mining software repositories (MSR), 2010 7th IEEE working conference på, pages 11–20. IEEE, 2010.
[8] Katerina Goseva-Popstojanova och Jacob Tyo. Identifiering av säkerhetsrelaterade felrapporter via textutvinning med hjälp av övervakad och oövervakad klassificering. I 2018 IEEE International Conference on Software Quality, Reliability and Security (QRS), sidorna 344–355, 2018.
[9] Ahmed Lamkanfi, Serge Demeyer, Emanuel Giger och Bart Goethals. Förutsäga allvarlighetsgraden för en rapporterad bugg. Vid Mining Software Repositories (MSR), 2010 7:e IEEE Working Conference on, sidor 1–10. IEEE, 2010.
[10] Naresh Manwani och PS Sastry. Brustolerans under riskminimering. IEEE Transactions on Cybernetics, 43(3):1146–1151, 2013.
[11] G Murphy och D Cubranic. Automatisk prioritering och kategorisering av fel med hjälp av textkategorisering. I Proceedings från den sextonde internationella konferensen om mjukvaruteknik & och kunskapsteknik. Citeseer, 2004.
[12] Mykola Pechenizkiy, Alexey Tsymbal, Seppo Puuronen och Oleksandr Pechenizkiy. Klassbrus och övervakad inlärning i medicinska domäner: Effekten av extrahering av funktioner. I null, sidorna 708–713. IEEE, 2006.
[13] Charlotte Pelletier, Silvia Valero, Jordi Inglada, Nicolas Champion, Claire Marais Sicre och Gerard Dedieu. Effekten av brus i träningsklassetiketter på klassificeringsprestanda för kartläggning av markanvändning med satellitbildtidsserier. Fjärranalys, 9(2):173, 2017.
[14] PS Sastry, GD Nagendra och Naresh Manwani. Ett team av kontinuerliga inlärningsautomater för brustolerant inlärning av halvutrymmen. IEEE Transaktioner på System, Man och Cybernetik, Del B (Cybernetik), 40(1):19–28, 2010.
[15] Choh-Man Teng. En jämförelse av brushanteringstekniker. I FLAIRS Conference, sidorna 269–273, 2001.
[16] Dumidu Wijayasekara, Milos Manic och Miles McQueen. Sårbarhetsidentifiering och klassificering via feldatabaser för textutvinning. I Industrial Electronics Society, IECON 2014 - den 40:e årliga konferensen av IEEE, sidorna 3612–3618. IEEE, 2014.
[17] Xinli Yang, David Lo, Qiao Huang, Xin Xia och Jianling Sun. Automatiserad identifiering av buggrapporter med hög påverkan som utnyttjar obalanserade inlärningsstrategier. I Computer Software and Applications Conference (COMPSAC), 2016 IEEE 40th Annual, volym 1, sidor 227–232. IEEE, 2016.
[18] Deqing Zou, Zhijun Deng, Zhen Li och Hai Jin. Identifiera automatiskt rapporter om säkerhetsfel via analys av funktioner för flera typer. I Australasiatiska konferensen om informationssäkerhet och integritet, sidorna 619–633. Springer, 2018.