Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
gäller för:![]() SQL Server
SQL Server
En distribuerad tillgänglighetsgrupp (AG) är en särskild typ av tillgänglighetsgrupp som omfattar två separata tillgänglighetsgrupper. Distribuerade tillgänglighetsgrupper är tillgängliga från och med SQL Server 2016.
I den här artikeln beskrivs funktionen för distribuerad tillgänglighetsgrupp. Information om hur du konfigurerar en distribuerad tillgänglighetsgrupp finns i Konfigurera distribuerade tillgänglighetsgrupper.
Översikt
En distribuerad tillgänglighetsgrupp är en särskild typ av tillgänglighetsgrupp som omfattar två separata tillgänglighetsgrupper. De tillgänglighetsgrupper som deltar i en distribuerad tillgänglighetsgrupp behöver inte finnas på samma plats. De kan vara fysiska, virtuella, lokala, i det offentliga molnet eller var som helst som stöder en distribution av tillgänglighetsgrupper. Detta inkluderar domänövergripande och till och med mellan plattformar – till exempel mellan en tillgänglighetsgrupp som är värd på Linux och en som är värd på Windows. Så länge två tillgänglighetsgrupper kan kommunicera kan du konfigurera en distribuerad tillgänglighetsgrupp med dem.
En traditionell tillgänglighetsgrupp har resurser konfigurerade i ett Windows Server-redundanskluster (WSFC) eller i Linux, Pacemaker. En distribuerad tillgänglighetsgrupp konfigurerar ingenting i det underliggande klustret (WSFC eller Pacemaker). Allt om det underhålls i SQL Server. Information om hur du visar information för en distribuerad tillgänglighetsgrupp finns i Visa information om distribuerad tillgänglighetsgrupp.
En distribuerad tillgänglighetsgrupp kräver att de underliggande tillgänglighetsgrupperna har en lyssnare. I stället för att ange det underliggande servernamnet för en fristående instans (eller om det gäller en SQL Server-redundansklusterinstans [FCI], värdet som är associerat med nätverksnamnresursen) som du skulle göra med en traditionell tillgänglighetsgrupp, anger du den konfigurerade lyssnaren för den distribuerade tillgänglighetsgruppen med parametern ENDPOINT_URL när du skapar den. Även om varje underliggande tillgänglighetsgrupp i den distribuerade tillgänglighetsgruppen har en lyssnare har en distribuerad tillgänglighetsgrupp ingen lyssnare.
Följande bild visar en övergripande vy över en distribuerad tillgänglighetsgrupp som sträcker sig över två tillgänglighetsgrupper (ag 1 och ag 2), var och en konfigurerad på sin egen WSFC. Den distribuerade tillgänglighetsgruppen har totalt fyra repliker, med två i varje tillgänglighetsgrupp. Varje tillgänglighetsgrupp har stöd för upp till det maximala antalet repliker, så en distribuerad tillgänglighetsgrupp kan ha upp till 18 totalt antal repliker.
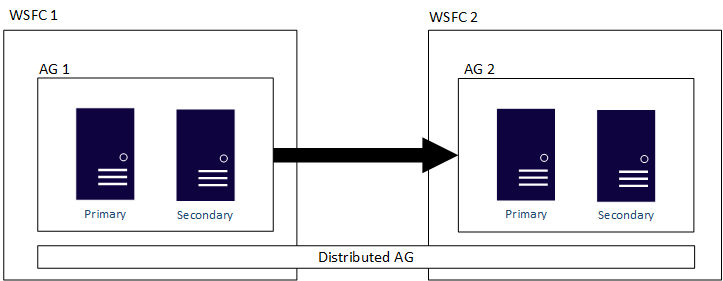
Du kan konfigurera dataflytten i distribuerade tillgänglighetsgrupper som synkrona eller asynkrona. Dataflytt skiljer sig dock något mellan distribuerade tillgänglighetsgrupper jämfört med en traditionell tillgänglighetsgrupp. Även om varje tillgänglighetsgrupp har en primär replik finns det bara en kopia av databaserna som deltar i en distribuerad tillgänglighetsgrupp som kan acceptera infogningar, uppdateringar och borttagningar. Som visas i följande figur, är AG 1 den primära tillgänglighetsgruppen. Den primära repliken skickar transaktioner både till de sekundära replikerna i tillgänglighetsgruppen 1 och till den primära repliken i tillgänglighetsgruppen 2. Den primära repliken av tillgänglighetsgruppen 2 kallas även en vidarebefordrare. En vidarebefordrare är en primär replik i en sekundär tillgänglighetsgrupp inom en distribuerad tillgänglighetsgrupp. Vidarebefordraren tar emot transaktioner från den primära repliken i den primära tillgänglighetsgruppen och vidarebefordrar dem till de sekundära replikerna i sin egen tillgänglighetsgrupp. Vidarebefordraren håller sedan de sekundära replikerna för AG 2 uppdaterade.
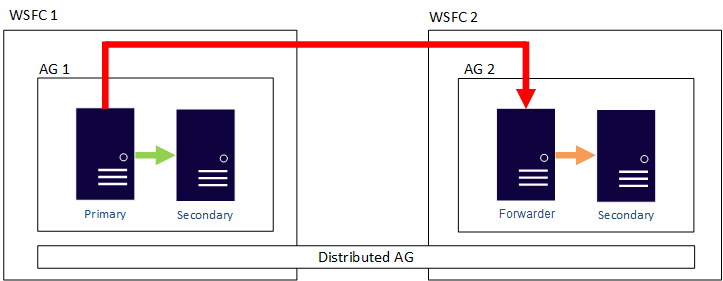
Det enda sättet att få den primära repliken av AG 2 att acceptera infogningar, uppdateringar och borttagningar är att manuellt växla över den distribuerade tillgänglighetsgruppen från AG 1. Eftersom tillgänglighetsgruppen 1 i föregående bild innehåller den skrivbara kopian av databasen, gör en redundansväxling tillgänglighetsgrupp 2 till den tillgänglighetsgrupp som kan hantera infogningar, uppdateringar och borttagningar. Information om hur du redundansväxlar en distribuerad tillgänglighetsgrupp till en annan finns i Redundansväxling till en sekundär tillgänglighetsgrupp.
Anmärkning
- Distribuerade tillgänglighetsgrupper i SQL Server 2016 stöder endast redundans från en tillgänglighetsgrupp till en annan med hjälp av alternativet
FORCE_FAILOVER_ALLOW_DATA_LOSS. - När du använder transaktionsreplikering med distribuerade tillgänglighetsgrupper kan vidarebefordrarrepliken inte konfigureras som utgivare.
SQL Server 2025-ändringar
SQL Server 2025 (17.x) introducerar följande ändringar:
Förbättring av synkroniseringen för distribuerade tillgänglighetsgrupper
SQL Server 2025 (17.x) introducerar en ändring av den interna synkroniseringsmekanismen för distribuerade tillgänglighetsgrupper för att förbättra synkroniseringsprestanda genom att minska nätverksmättnad när vidarebefordrarrepliken är i asynkront incheckningsläge. Den här ändringen är aktiverad som standard och kräver ingen konfiguration.
Anmärkning
Det rekommenderas inte att konfigurera din distribuerade tillgänglighetsgrupp med ett matchningsfel mellan tillgänglighetslägena för de två underliggande tillgänglighetsgrupperna och kan medföra synkroniseringsfördröjning. Båda tillgänglighetsgrupperna bör konfigureras med samma tillgänglighetsläge (synkront eller asynkront) för att säkerställa optimal prestanda och synkronisering.
Stöd för begränsad tillgänglighetsgrupp
SQL Server 2025 (17.x) introducerar stöd för en distribuerad innesluten tillgänglighetsgrupp. Om du tänker använda en innesluten tillgänglighetsgrupp som vidarebefordrare i en distribuerad tillgänglighetsgrupp måste du skapa den inneslutna AUTOSEEDING_SYSTEM_DATABASES tillgänglighetsgruppen med hjälp av satsen för WITH | CONTAINED alternativet skapa tillgänglighetsgruppskommandot .
Krav för version och utgåva
Distribuerade tillgänglighetsgrupper i SQL Server 2017 eller senare kan blanda större versioner av SQL Server i samma distribuerade tillgänglighetsgrupp. Den tillgänglighetsgruppen som har primär läs-/skrivåtkomst kan vara av samma version eller en lägre version än de andra grupperna som deltar i den distribuerade tillgänglighetsgruppen. De andra AG:erna kan ha samma version eller högre. Det här scenariot är avsett för uppgraderings- och migreringsscenarier. Om tillgänglighetsgruppen som innehåller den primära repliken för läsning/skrivning till exempel är SQL Server 2016, men du vill uppgradera/migrera till SQL Server 2017 eller senare, kan den andra tillgänglighetsgruppen som deltar i den distribuerade tillgänglighetsgruppen konfigureras med SQL Server 2017.
Eftersom funktionen distribuerade tillgänglighetsgrupper inte fanns i SQL Server 2012 eller 2014 kan tillgänglighetsgrupper som skapades med dessa versioner inte delta i distribuerade tillgänglighetsgrupper.
Anmärkning
Beroende på vilken version av SQL Server som används vid anslutning till Azure-tjänster (till exempel länken Hanterad instans) är det möjligt att konfigurera en distribuerad tillgänglighetsgrupp med Standard Edition eller en blandning av Standard- och Enterprise-utgåvor. Läs KB5016729 om du vill veta mer.
Eftersom det finns två separata tillgänglighetsgrupper skiljer sig processen för att installera ett Service Pack eller en kumulativ uppdatering på en replik som deltar i en distribuerad tillgänglighetsgrupp något från den för en traditionell tillgänglighetsgrupp:
Börja med att uppdatera replikerna för den andra tillgänglighetsgruppen i den distribuerade tillgänglighetsgruppen.
Uppdatera replikerna av den primära tillgänglighetsgruppen i den distribuerade tillgänglighetsgruppen.
Precis som med en standardtillgänglighetsgrupp växlar du över den primära tillgänglighetsgruppen till en av dess egna repliker (inte till den primära för den andra tillgänglighetsgruppen) och uppdaterar den. Om det inte finns någon annan replik än den primära, krävs en manuell failover till den andra tillgänglighetsgruppen.
Windows Server-versioner och distribuerade tillgänglighetsgrupper
En distribuerad tillgänglighetsgrupp omfattar flera tillgänglighetsgrupper, var och en på sin egen underliggande WSFC, och en distribuerad tillgänglighetsgrupp är en konstruktion enbart för SQL Server. Det innebär att de WSFC:er som rymmer de enskilda tillgänglighetsgrupperna kan ha olika huvudversioner av Windows Server. Huvudversionerna av SQL Server måste vara desamma, enligt beskrivningen i föregående avsnitt. Ungefär som den första figuren visar nästa figur AG 1 och AG 2 som deltar i en distribuerad tillgänglighetsgrupp, men var och en av WSFC:erna är en annan version av Windows Server.
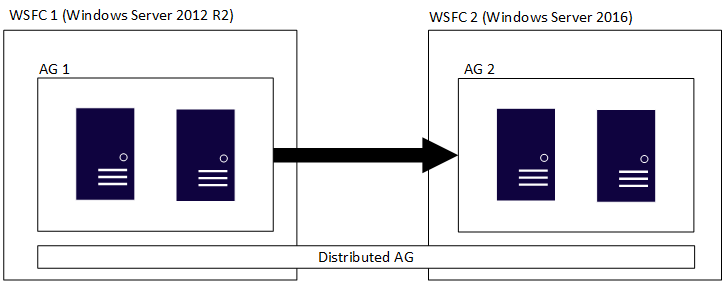
De enskilda WSFC:erna och deras motsvarande tillgänglighetsgrupper följer traditionella regler. De kan alltså anslutas till en domän eller inte vara anslutna till en domän (Windows Server 2016 eller senare). När två olika tillgänglighetsgrupper kombineras i en enda distribuerad tillgänglighetsgrupp finns det fyra scenarier:
- Båda WSFC:erna är anslutna till samma domän.
- Varje WSFC är ansluten till en annan domän.
- En WSFC är ansluten till en domän och en WSFC är inte ansluten till en domän.
- Ingen av WSFC:erna är anslutna till en domän.
När båda WSFC:erna är anslutna till samma domän (inte betrodda domäner) behöver du inte göra något särskilt när du skapar den distribuerade tillgänglighetsgruppen. För tillgänglighetsgrupper och WSFC:er som inte är anslutna till samma domän använder du certifikat för att få den distribuerade tillgänglighetsgruppen att fungera, mycket på det sätt som du kan skapa en tillgänglighetsgrupp för en domänoberoende tillgänglighetsgrupp. Om du vill se hur du konfigurerar certifikat för en distribuerad tillgänglighetsgrupp följer du steg 3–13 under Skapa en domänoberoende tillgänglighetsgrupp.
Med en distribuerad tillgänglighetsgrupp måste de primära replikerna i varje underliggande tillgänglighetsgrupp ha varandras certifikat. Om du redan har slutpunkter som inte använder certifikat konfigurerar du om dessa slutpunkter med hjälp av ALTER ENDPOINT för att återspegla användningen av certifikat.
Användningsscenarier
Här är de tre huvudsakliga användningsscenarierna för en distribuerad tillgänglighetsgrupp:
- Katastrofåterställning och enklare flerplatskonfigurationer
- Migrering till ny maskinvara eller konfigurationer, som kan innefatta användning av ny maskinvara eller ändring av underliggande operativsystem
- Öka antalet läsbara repliker utöver åtta i en enda tillgänglighetsgrupp genom att sträcka sig över flera tillgänglighetsgrupper
Haveriberedskap och scenarier med flera platser
En traditionell tillgänglighetsgrupp kräver att alla servrar ingår i samma WSFC, vilket kan göra det svårt att sträcka sig över flera datacenter. Följande bild visar hur en traditionell arkitektur för tillgänglighetsgrupper för flera platser ser ut, inklusive dataflödet. Det finns en primär replik som skickar transaktioner till alla sekundära repliker. Den här konfigurationen är mindre på vissa sätt än en distribuerad tillgänglighetsgrupp. Du måste till exempel implementera sådant som služba Active Directory (om tillämpligt) och vittnet för ett kvorum i WSFC. Du kan också behöva ta hänsyn till andra aspekter av en WSFC, till exempel att ändra nodröster.

Distribuerade tillgänglighetsgrupper erbjuder ett mer flexibelt distributionsscenario för tillgänglighetsgrupper som sträcker sig över flera datacenter. Du kan till och med använda distribuerade tillgänglighetsgrupper där funktioner som loggöverföring tidigare användes för scenarier som katastrofåterställning. Men till skillnad från loggleverans kan distribuerade tillgänglighetsgrupper inte ha fördröjd tillämpning av transaktioner. Det innebär att tillgänglighetsgrupper eller distribuerade tillgänglighetsgrupper inte kan hjälpa vid mänskliga fel där data uppdateras eller tas bort felaktigt.
Distribuerade tillgänglighetsgrupper är löst kopplade, vilket i det här fallet innebär att de inte kräver en enda WSFC och de underhålls av SQL Server. Eftersom WSFCs underhålls individuellt och synkroniseringen främst är asynkron mellan de två tillgänglighetsgrupperna är det enklare att konfigurera haveriberedskap på en annan plats. De primära replikerna i varje tillgänglighetsgrupp synkroniserar sina egna sekundära repliker.
- Endast manuell redundans stöds för en distribuerad tillgänglighetsgrupp. I en haveriberedskapssituation där du byter datacenter bör du inte konfigurera automatisk redundans (med sällsynta undantag).
- Du kommer förmodligen inte behöva ställa in vissa av de traditionella objekten eller parametrarna för WSFCs som sträcker sig över flera platser eller undernät, såsom CrossSubnetThreshold. Men du måste fortfarande ta hänsyn till nätverkslatens på en annan nivå för datatransporten. Skillnaden är att varje WSFC har sin egen tillgänglighet. klustret är inte en stor entitet med fyra noder. Du har två separata WSFCs med två noder enligt föregående bild.
- Vi rekommenderar asynkron dataförflyttning eftersom den här metoden skulle vara i haveriberedskapssyfte.
- Om du konfigurerar synkron dataförflyttning mellan den primära repliken och minst en sekundär replik av den andra tillgänglighetsgruppen, och du konfigurerar synkron förflyttning i den distribuerade tillgänglighetsgruppen, väntar en distribuerad tillgänglighetsgrupp tills alla synkrona kopior bekräftar att de har data. Om flera distribuerade tillgänglighetsgrupper kopplas samman (AG1 –> AG2 –> AG3) och är inställda på synkron väntar en distribuerad tillgänglighetsgrupp tills den sista repliken av den senaste tillgänglighetsgruppen har uppdaterats.
Migrera
Eftersom distribuerade tillgänglighetsgrupper stöder två helt olika konfigurationer av tillgänglighetsgrupper möjliggör de inte bara enklare haveriberedskap och scenarier med flera platser, utan även migreringsscenarier. Oavsett om du migrerar till ny maskinvara eller virtuella datorer (lokalt eller IaaS i det offentliga molnet) kan en migrering ske genom att konfigurera en distribuerad tillgänglighetsgrupp där du tidigare kanske har använt säkerhetskopiering, kopiering och återställning eller loggleverans.
Möjligheten att migrera är särskilt användbar i scenarier där du ändrar eller uppgraderar det underliggande operativsystemet medan du behåller samma SQL Server-version. Även om Windows Server 2016 tillåter en löpande uppgradering från Windows Server 2012 R2 på samma maskinvara, väljer de flesta användare att distribuera ny maskinvara eller virtuella datorer.
För att slutföra migreringen till den nya konfigurationen stoppar du all datatrafik till den ursprungliga tillgänglighetsgruppen i slutet av processen och ändrar den distribuerade tillgänglighetsgruppen till synkron dataflytt. Den här åtgärden säkerställer att den primära repliken för den andra tillgänglighetsgruppen är helt synkroniserad, så det skulle inte uppstå någon dataförlust. När du har verifierat synkroniseringen växlar du över den distribuerade tillgänglighetsgruppen till den sekundära tillgänglighetsgruppen. För mer information, se Växla över till en sekundär tillgänglighetsgrupp.
Efter migreringen, där den andra tillgänglighetsgruppen nu är den nya primära tillgänglighetsgruppen, kan du behöva utföra något av följande steg:
- Byt namn på lyssnaren i den sekundära tillgänglighetsgruppen (och eventuellt ta bort eller byt namn på den gamla i den ursprungliga primära tillgänglighetsgruppen) eller återskapa den med lyssnaren från den ursprungliga primära tillgänglighetsgruppen, så att program och användare kan komma åt den nya konfigurationen.
- Om det inte går att byta namn på eller återskapa kan du peka program och användare till lyssnaren i den andra tillgänglighetsgruppen.
Migrera till högre SQL Server-versioner
Under ett migreringsscenario är det möjligt att konfigurera en distribuerad AG för att migrera dina databaser till ett SQL Server-mål som är en senare version än källan, men det finns några begränsningar.
När du konfigurerar en distribuerad tillgänglighetsgrupp med ett SQL Server-migreringsmål med en version som är högre än källan, stöds inte autoseeding, därför måste seeding-läget ställas in på MANUAL. Om du inte inaktiverar AUTOMATISK SEEDING misslyckas migreringen och du får felmeddelandet 946 "Det går inte att öppna databasens DistributionAG-version xxx. "I felloggen: 'Uppgradera databasen till den senaste versionen.'" Du måste ställa in seeding-läget till MANUELL och manuellt utföra en fullständig säkerhetskopiering samt en säkerhetskopiering av transaktionsloggen för källdatabasen från den primära tillgänglighetsgruppen. Återställ den sedan manuellt, tillsammans med transaktionsloggen, till den sekundära AG (tillgänglighetsgruppen). För att lära dig mer, granska stegen för manuell seeding för att konfigurera din distribuerade AG samt skript för att säkerhetskopiera och återställa din databas från den primära AG till den sekundära AG.
Anta att den sekundära tillgänglighetsgruppen (AG2) är migreringsmålet och är en högre version än den primära tillgänglighetsgruppen (AG1), bör du överväga följande begränsningar:
- Du har inte läsåtkomst till någon av replikdatabaserna på den sekundära tillgänglighetsgruppen så länge den primära tillgänglighetsgruppen har en lägre version.
- Under den här tiden fortsätter uppdateringarna att flöda från den primära tillgänglighetsgruppen (AG1) till den sekundära tillgänglighetsgruppen (AG2), men statusen för den sekundära tillgänglighetsgruppen visas som Delvis felfri och databaser på sekundära repliker av den sekundära tillgänglighetsgruppen (AG2) visas som synkronisering/i återställning (även om tillgänglighetsgruppen är i synkroniseringsincheckning).
- När den distribuerade tillgänglighetsgruppen har omdirigerats till den nyare versionen (AG2) bör AG2 bli hälsosam.
- Under den här tiden är det inte möjligt att gå tillbaka till AG1, eftersom det är i en lägre version.
- Eftersom AG1 har en lägre version replikeras inte uppdateringar från AG2 efter redundansväxling till AG2 över till AG1.
- Härifrån väljer du om du vill inaktivera den ursprungliga (primära) tillgänglighetsgruppen eller om du vill uppgradera AG1 och underhålla den distribuerade tillgänglighetsgruppen.
- Om du väljer att inaktivera AG1, ska du ta bort den ursprungliga primära AG från den distribuerade AG, och processen är då avslutad.
- Om du väljer att underhålla den distribuerade tillgänglighetsgruppen uppgraderar du SQL Server-versionen för AG1 så att den matchar AG2. När AG1 har uppgraderats blir AG1 felfri, den distribuerade tillgänglighetsgruppen blir felfri, replikerna kommer ikapp för att synkroniseras och återställning efter fel blir möjlig.
Skala ut läsbara repliker
En enda distribuerad tillgänglighetsgrupp kan ha upp till 16 sekundära repliker efter behov. Det kan därför ha upp till 18 kopior för läsning, inklusive de två primära kopiorna för de olika tillgänglighetsgrupperna. Den här metoden innebär att fler än en webbplats kan ha nästan realtidsåtkomst för rapportering till olika program.
Distribuerade tillgänglighetsgrupper kan hjälpa dig att skala ut en skrivskyddad servergrupp mer än du kan med bara en enda tillgänglighetsgrupp. En distribuerad tillgänglighetsgrupp kan skala ut läsbara repliker på två sätt:
- Du kan använda den primära repliken för den andra tillgänglighetsgruppen i en distribuerad tillgänglighetsgrupp för att skapa en annan distribuerad tillgänglighetsgrupp, även om databasen inte finns i RECOVERY.
- Du kan också använda den primära repliken för den första tillgänglighetsgruppen för att skapa en annan distribuerad tillgänglighetsgrupp.
Med andra ord kan en primär replik delta i olika distribuerade tillgänglighetsgrupper. Följande bild visar ag 1 och ag 2 som båda deltar i distribuerad ag 1, medan AG 2 och AG 3 deltar i distribuerad ag 2. Den primära repliken (eller vidarebefordraren) för tillgänglighetsgruppen 2 är både en sekundär replik för distribuerad tillgänglighetsgrupp 1 och en primär replik av distribuerad tillgänglighetsgrupp 2.
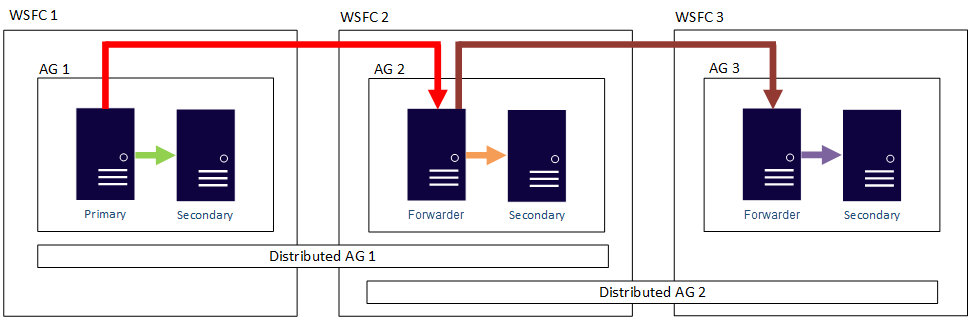
Följande bild visar tillgänglighetsgruppen 1 som primär replik för två olika distribuerade tillgänglighetsgrupper: Distribuerad tillgänglighetsgrupp 1 (bestående av ag 1 och ag2) och distribuerad tillgänglighetsgrupp 2 (bestående av ag 1 och ag 3).
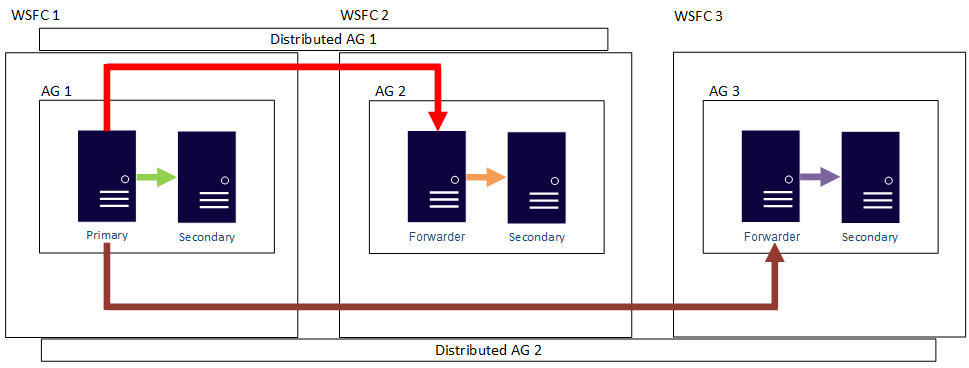
I båda föregående exempel kan det finnas upp till 27 repliker totalt i de tre tillgänglighetsgrupperna, vilka alla kan användas för endast läsning.
Skrivskyddad routning fungerar inte helt med distribuerade tillgänglighetsgrupper. Mer specifikt
- Read-Only Routing kan konfigureras och kommer att fungera för den primära gruppen i den distribuerade tillgänglighetsgruppen.
- Read-Only Routing kan konfigureras, men kommer inte att fungera i den sekundära tillgänglighetsgruppen inom den distribuerade tillgänglighetsgruppen. Alla frågor, om de använder lyssnaren för att ansluta till den sekundära tillgänglighetsgruppen, skickas till den primära repliken för den sekundära tillgänglighetsgruppen. Annars måste du konfigurera varje replik för att tillåta alla anslutningar som en sekundär replik och komma åt dem direkt. Skrivskyddad routning fungerar dock om den sekundära tillgänglighetsgruppen blir primär efter en redundansväxling. Det här beteendet kan ändras i en uppdatering av SQL Server 2016 eller i en framtida version av SQL Server.
Initiera sekundära tillgänglighetsgrupper
Distribuerade tillgänglighetsgrupper utformades med automatisk seeding som huvudmetod för att initiera den primära repliken i den andra tillgänglighetsgruppen. En fullständig databasåterställning på den primära repliken för den andra tillgänglighetsgruppen är möjlig om du gör följande:
- Återställ databassäkerhetskopian MED NORECOVERY.
- Om det behövs återställer du rätt säkerhetskopior av transaktionsloggen MED NORECOVERY.
- Skapa den andra tillgänglighetsgruppen utan att ange ett databasnamn och med SEEDING_MODE inställt på AUTOMATISK.
- Skapa den distribuerade tillgänglighetsgruppen med hjälp av automatisk frösättning.
När du lägger till den andra tillgänglighetsgruppens primära replik i den distribuerade tillgänglighetsgruppen, kontrolleras repliken mot den första tillgänglighetsgruppens primära databaser, och automatisk seeding synkroniserar databasen med källan. Det finns några varningar:
Utdata som visas på
sys.dm_hadr_automatic_seedingpå den primära replikan för den andra tillgänglighetsgruppen visar ettcurrent_stateav "FAILED" av följande orsak: "Seeding Check Message Timeout".Den aktuella SQL Server-felloggen på den primära repliken för den andra tillgänglighetsgruppen visar att automatisk seeding fungerade och att LSN:erna synkroniserades.
Utdata som visas i
sys.dm_hadr_automatic_seedingpå den primära repliken i den första tillgänglighetsgruppen kommer att visa ett nuvarande_tillstånd som COMPLETED.Automatisk seeding har också olika beteende med distribuerade tillgänglighetsgrupper. För att automatisk seeding ska börja på den andra repliken måste du utfärda kommandokommandot
ALTER AVAILABILITY GROUP [AGName] GRANT CREATE ANY DATABASEpå repliken. Även om det här villkoret fortfarande gäller för alla sekundärreplikerna som deltar i den underliggande tillgänglighetsgruppen, har den primära repliken för den andra tillgänglighetsgruppen redan de nödvändiga behörigheterna för att möjliggöra att automatisk seeding kan börja efter att den har lagts till i den distribuerade tillgänglighetsgruppen.
Anmärkning
- Den sekundära tillgänglighetsgruppen måste använda samma databasspeglingsslutpunkt. Annars stoppas replikeringen efter en lokal failover.
- De underliggande tillgänglighetsgrupperna bör vara i samma tillgänglighetsläge – antingen ska båda tillgänglighetsgrupperna vara i synkront incheckningsläge eller båda ska vara i asynkront incheckningsläge. Om du inte är säker på vilken du ska använda, ställ in båda på asynkront commit-läge tills du är redo att överflytta.
Övervaka hälsotillstånd
En distribuerad tillgänglighetsgrupp är en SQL Server-konstruktion och den visas inte i den underliggande WSFC:n. Följande kodexempel visar två olika WSFCs (CLUSTER_A och CLUSTER_B), var och en med sina egna tillgänglighetsgrupper. Här diskuteras endast ag1 i CLUSTER_A och ag2 i CLUSTER_B.
PS C:\> Get-ClusterGroup -Cluster CLUSTER_A
Name OwnerNode State
---- --------- -----
AG1 DENNIS Online
Available Storage GLEN Offline
Cluster Group JY Online
New_RoR DENNIS Online
Old_RoR DENNIS Online
SeedingAG DENNIS Online
PS C:\> Get-ClusterGroup -Cluster CLUSTER_B
Name OwnerNode State
---- --------- -----
AG2 TOMMY Online
Available Storage JC Offline
Cluster Group JC Online
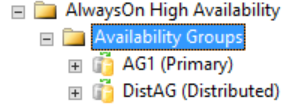
All detaljerad information om en distribuerad tillgänglighetsgrupp finns i SQL Server, särskilt i vyerna för dynamisk hantering av tillgänglighetsgrupper. För närvarande finns den enda information som visas i SQL Server Management Studio för en distribuerad tillgänglighetsgrupp på den primära repliken för tillgänglighetsgrupperna. Som du ser i följande bild, under mappen Tillgänglighetsgrupper, visar SQL Server Management Studio att det finns en distribuerad tillgänglighetsgrupp. Bilden visar AG1 som den primära repliken för en enskild tillgänglighetsgrupp som är lokal för just den instansen, inte för en distribuerad tillgänglighetsgrupp.
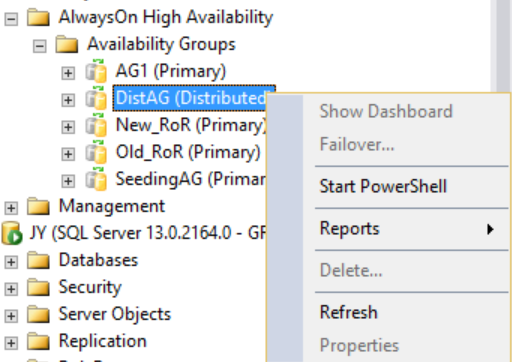
Men om du högerklickar på den distribuerade tillgänglighetsgruppen är inga alternativ tillgängliga (se följande bild) och de utökade mapparna Tillgänglighetsdatabaser, Tillgänglighetsgrupplyssnare och Tillgänglighetsrepliker är alla tomma. SQL Server Management Studio 16 visar det här resultatet, men det kan komma att ändras i en framtida version av SQL Server Management Studio.
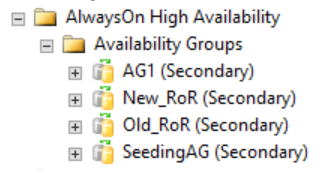
Som du ser i följande bild visar sekundära repliker ingenting i SQL Server Management Studio som är relaterade till den distribuerade tillgänglighetsgruppen. Dessa namn på tillgänglighetsgrupper motsvarar de roller som visades i föregående CLUSTER_A WSFC bild.
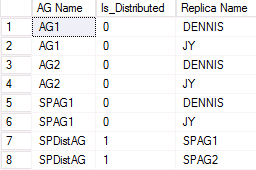
DMV för att lista alla tillgängliga replikanamn
Samma begrepp gäller när du använder dynamiska hanteringsvyer. Med hjälp av följande fråga kan du se alla tillgänglighetsgrupper (vanliga och distribuerade) och de noder som deltar i dem. Det här resultatet visas endast om du ställer frågor mot den primära repliken i någon av de WSFC:er som deltar i den distribuerade tillgänglighetsgruppen. Det finns en ny kolumn i vyn sys.availability_groups dynamisk hantering med namnet is_distributed, som är 1 när tillgänglighetsgruppen är en distribuerad tillgänglighetsgrupp. Så här ser du den här kolumnen:
-- shows replicas associated with availability groups
SELECT
ag.[name] AS [AG Name],
ag.Is_Distributed,
ar.replica_server_name AS [Replica Name]
FROM sys.availability_groups AS ag
INNER JOIN sys.availability_replicas AS ar
ON ag.group_id = ar.group_id;
GO
Ett exempel på utdata från den andra WSFC som deltar i en distribuerad tillgänglighetsgrupp visas i följande bild. SPAG1 består av två repliker: DENNIS och JY. Den distribuerade tillgänglighetsgruppen SPDistAG har dock namnen på de två deltagande tillgänglighetsgrupperna (SPAG1 och SPAG2) i stället för namnen på instanserna, som med en traditionell tillgänglighetsgrupp.
DMV för att lista distribuerad tillgänglighetsgruppshälsa
I SQL Server Management Studio är alla statusar som visas på instrumentpanelen och andra områden endast för lokal synkronisering inom den tillgänglighetsgruppen. För att visa hälsan hos en distribuerad tillgänglighetsgrupp använder du de dynamiska hanteringsvyerna. Följande exempelfråga utökar och förfinar föregående fråga:
-- shows sync status of distributed AG
SELECT
ag.[name] AS [AG Name],
ag.is_distributed,
ar.replica_server_name AS [Underlying AG],
ars.role_desc AS [Role],
ars.synchronization_health_desc AS [Sync Status]
FROM sys.availability_groups AS ag
INNER JOIN sys.availability_replicas AS ar
ON ag.group_id = ar.group_id
INNER JOIN sys.dm_hadr_availability_replica_states AS ars
ON ar.replica_id = ars.replica_id
WHERE ag.is_distributed = 1;
GO

DMV för att bedöma underliggande prestanda
Om du vill utöka den tidigare frågan ytterligare kan du även se underliggande prestanda via vyerna för dynamisk hantering genom att lägga till i sys.dm_hadr_database_replicas_states. Den dynamiska hanteringsvyn lagrar för närvarande endast information om den andra tillgänglighetsgruppen. Följande exempelfråga, som körs i den primära tillgänglighetsgruppen, genererar exempelutdata som visas nedan:
-- shows underlying performance of distributed AG
SELECT
ag.[name] AS [Distributed AG Name],
ar.replica_server_name AS [Underlying AG],
dbs.[name] AS [Database],
ars.role_desc AS [Role],
drs.synchronization_health_desc AS [Sync Status],
drs.log_send_queue_size,
drs.log_send_rate,
drs.redo_queue_size,
drs.redo_rate
FROM sys.databases AS dbs
INNER JOIN sys.dm_hadr_database_replica_states AS drs
ON dbs.database_id = drs.database_id
INNER JOIN sys.availability_groups AS ag
ON drs.group_id = ag.group_id
INNER JOIN sys.dm_hadr_availability_replica_states AS ars
ON ars.replica_id = drs.replica_id
INNER JOIN sys.availability_replicas AS ar
ON ar.replica_id = ars.replica_id
WHERE ag.is_distributed = 1;
GO

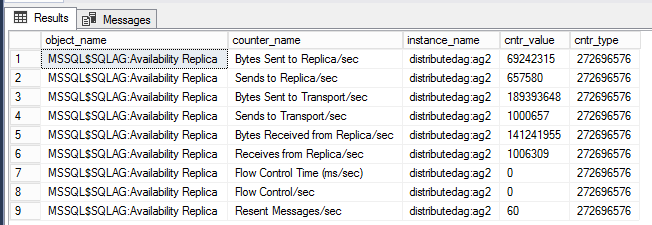
DMV för att granska prestandaindikatorer i distribuerade AG
Nedanstående fråga visar prestandaräknare som är associerade med den specifika distribuerade tillgänglighetsgruppen.
-- displays OS performance counters related to the distributed ag named 'distributedag'
SELECT * FROM sys.dm_os_performance_counters WHERE instance_name LIKE '%distributed%'
Anmärkning
LIKE Filtret ska ha namnet på den distribuerade tillgänglighetsgruppen. I det här exemplet är namnet på den distribuerade tillgänglighetsgruppen "distributedag".
LIKE Ändra modifieraren så att den återspeglar namnet på din distribuerade tillgänglighetsgrupp.
DMV för att visa hälsotillståndet för både tillgänglighetsgruppen och den distribuerade tillgänglighetsgruppen
Frågan nedan visar en mängd information om hälsotillståndet för både tillgänglighetsgruppen och den distribuerade tillgänglighetsgruppen. (Reproducerad med tillstånd från Tracy Boggiano.)
-- displays sync status, send rate, and redo rate of availability groups,
-- including distributed AG
SELECT ag.name AS [AG Name],
ag.is_distributed,
ar.replica_server_name AS [AG],
dbs.name AS [Database],
ars.role_desc,
drs.synchronization_health_desc,
drs.log_send_queue_size,
drs.log_send_rate,
drs.redo_queue_size,
drs.redo_rate,
drs.suspend_reason_desc,
drs.last_sent_time,
drs.last_received_time,
drs.last_hardened_time,
drs.last_redone_time,
drs.last_commit_time,
drs.secondary_lag_seconds
FROM sys.databases dbs
INNER JOIN sys.dm_hadr_database_replica_states drs
ON dbs.database_id = drs.database_id
INNER JOIN sys.availability_groups ag
ON drs.group_id = ag.group_id
INNER JOIN sys.dm_hadr_availability_replica_states ars
ON ars.replica_id = drs.replica_id
INNER JOIN sys.availability_replicas ar
ON ar.replica_id = ars.replica_id
--WHERE ag.is_distributed = 1
GO

DMV:er för att granska metadata för distribuerade tillgänglighetsgrupper
Frågorna nedan visar information om slutpunkts-URL:er som används av tillgänglighetsgrupperna, inklusive den distribuerade tillgänglighetsgruppen. (Reproducerad med tillstånd från David Barbarin.)
-- shows endpoint url and sync state for ag, and dag
SELECT
ag.name AS group_name,
ag.is_distributed,
ar.replica_server_name AS replica_name,
ar.endpoint_url,
ar.availability_mode_desc,
ar.failover_mode_desc,
ar.primary_role_allow_connections_desc AS allow_connections_primary,
ar.secondary_role_allow_connections_desc AS allow_connections_secondary,
ar.seeding_mode_desc AS seeding_mode
FROM sys.availability_replicas AS ar
JOIN sys.availability_groups AS ag
ON ar.group_id = ag.group_id;
GO

DMV visar aktuellt tillstånd för sådd
Nedanstående fråga visar information om det aktuella tillståndet för seeding. Detta är användbart för att felsöka synkroniseringsfel mellan repliker. (Reproducerad med tillstånd från David Barbarin.)
-- shows current_state of seeding
SELECT ag.name AS aag_name,
ar.replica_server_name,
d.name AS database_name,
has.current_state,
has.failure_state_desc AS failure_state,
has.error_code,
has.performed_seeding,
has.start_time,
has.completion_time,
has.number_of_attempts
FROM sys.dm_hadr_automatic_seeding AS has
INNER JOIN sys.availability_groups AS ag
ON ag.group_id = has.ag_id
INNER JOIN sys.availability_replicas AS ar
ON ar.replica_id = has.ag_remote_replica_id
INNER JOIN sys.databases AS d
ON d.group_database_id = has.ag_db_id;
GO
