Not
Åtkomst till denna sida kräver auktorisation. Du kan prova att logga in eller byta katalog.
Åtkomst till denna sida kräver auktorisation. Du kan prova att byta katalog.
Gäller för:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() SQL-databas i Microsoft Fabric
SQL-databas i Microsoft Fabric
Den här artikeln beskriver hur du ritar data med hjälp av Python-paketet pandas'.hist(). En SQL Server-databas är källan som används för att visualisera histogrammets dataintervall som har efterföljande, icke-överlappande värden.
Prerequisites
- SQL Server för Windows eller Linux
Azure SQL Managed Instance (en hanterad instans av SQL i Azure)
SQL Server Management Studio för att återställa exempeldatabasen till Azure SQL Managed Instance.
Azure Data Studio. Information om hur du installerar finns i Azure Data Studio.
Återställ DW-exempeldatabasen för att hämta exempeldata som används i den här artikeln.
Verifiera återställd databas
Du kan kontrollera att den återställde databasen finns genom att fråga tabellen Person.CountryRegion :
USE AdventureWorksDW;
SELECT * FROM Person.CountryRegion;
Installera Python-paket
Ladda ned och installera Azure Data Studio.
Installera följande Python-paket:
pyodbcpandassqlalchemymatplotlib
Så här installerar du följande paket:
- I din Azure Data Studio-anteckningsbok väljer du Hantera paket.
- I fönstret Hantera paket väljer du fliken Lägg till ny .
- För vart och ett av följande paket anger du paketnamnet, väljer Sök och väljer sedan Installera.
Rita histogram
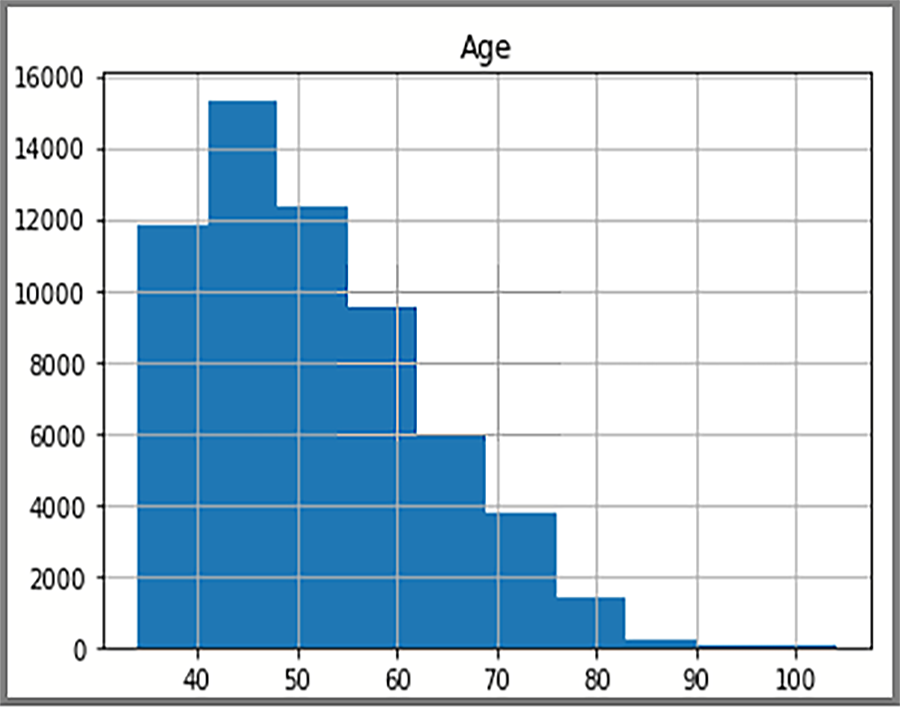
De distribuerade data som visas i histogrammet baseras på en SQL-fråga från AdventureWorksDW2025. Histogrammet visualiserar data och datavärdenas frekvens.
Redigera anslutningssträngvariablerna: server, database, usernameoch password för att ansluta till SQL Server-databasen.
Så här skapar du en ny notebook-fil:
I Azure Data Studio väljer du Arkiv, ny anteckningsbok.
I anteckningsboken väljer du kernel Python3 och klickar på +code.
Klistra in kod i notebook-filen. Välj Kör alla.
import pyodbc import pandas as pd import matplotlib import sqlalchemy from sqlalchemy import create_engine matplotlib.use('TkAgg', force=True) from matplotlib import pyplot as plt # Some other example server values are # server = 'localhost\sqlexpress' # for a named instance # server = 'myserver,port' # to specify an alternate port server = 'servername' database = 'AdventureWorksDW2022' username = 'yourusername' password = 'databasename' url = 'mssql+pyodbc://{user}:{passwd}@{host}:{port}/{db}?driver=SQL+Server'.format(user=username, passwd=password, host=server, port=port, db=database) engine = create_engine(url) sql = "SELECT DATEDIFF(year, c.BirthDate, GETDATE()) AS Age FROM [dbo].[FactInternetSales] s INNER JOIN dbo.DimCustomer c ON s.CustomerKey = c.CustomerKey" df = pd.read_sql(sql, engine) df.hist(bins=50) plt.show()
Visningen visar åldersfördelningen för kunder i FactInternetSales tabellen.