Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Gäller för:![]() SQL Server 2016 (13.x)
SQL Server 2016 (13.x) ![]() SQL Server 2017 (14.x)
SQL Server 2017 (14.x) ![]() SQL Server 2019 (15.x) på Linux
SQL Server 2019 (15.x) på Linux
Python-integrering är tillgängligt i SQL Server 2017 och senare, när du inkluderar Python-alternativet i en Machine Learning Services-installation (In-Database).
Anmärkning
För närvarande gäller den här artikeln för SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) och SQL Server 2019 (endast 15.x) för Linux.
Om du vill utveckla och distribuera Python-lösningar för SQL Server installerar du Microsofts revoscalepy och andra Python-bibliotek som din utvecklingsarbetsstation. Revoscalepy-biblioteket, som också finns på den fjärranslutna SQL Server-instansen, samordnar databehandlingsbegäranden mellan båda systemen.
I den här artikeln får du lära dig hur du konfigurerar en Python-utvecklingsarbetsstation så att du kan interagera med en fjärransluten SQL Server som är aktiverad för maskininlärning och Python-integrering. När du har slutfört stegen i den här artikeln har du samma Python-bibliotek som de på SQL Server. Du vet också hur du skickar beräkningar från en lokal Python-session till en fjärransluten Python-session på SQL Server.
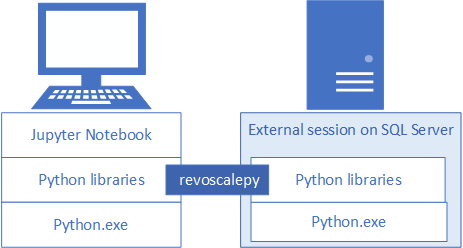
För att verifiera installationen kan du använda inbyggda Jupyter Notebooks enligt beskrivningen i den här artikeln, eller länka biblioteken till PyCharm eller någon annan IDE som du normalt använder.
Tips/Råd
En videodemonstration av dessa övningar finns i Köra R och Python via fjärranslutning i SQL Server från Jupyter Notebooks.
Vanliga verktyg
Oavsett om du är en Python-utvecklare som är nybörjare på SQL eller en SQL-utvecklare som är nybörjare på Python- och databasanalys behöver du både ett Python-utvecklingsverktyg och en T-SQL-frågeredigerare som SQL Server Management Studio (SSMS) för att kunna använda alla funktioner i databasanalys.
För Python-utveckling kan du använda Jupyter Notebooks, som ingår i Anaconda-distributionen som installeras av SQL Server. Den här artikeln beskriver hur du startar Jupyter Notebooks så att du kan köra Python-kod lokalt och via fjärranslutning på SQL Server.
SSMS är en separat nedladdning som är användbar för att skapa och köra lagrade procedurer på SQL Server, inklusive de som innehåller Python-kod. Nästan all Python-kod som du skriver i Jupyter Notebooks kan bäddas in i en lagrad procedur. Du kan gå igenom andra snabbstarter för att lära dig mer om SSMS och inbäddade Python.
1 – Installera Python-paket
Lokala arbetsstationer måste ha samma Python-paketversioner som de på SQL Server, inklusive bas-Anaconda 4.2.0 med Python 3.5.2-distribution och Microsoft-specifika paket.
Ett installationsskript lägger till tre Microsoft-specifika bibliotek i Python-klienten. Skriptet installeras:
- revoscalepy används för att definiera datakällobjekt och beräkningskontexten.
- microsoftml tillhandahåller maskininlärningsalgoritmer.
- azureml gäller för operationaliseringsuppgifter som är associerade med en fristående serverkontext och kan vara av begränsad användning för analys i databasen.
Ladda ned ett installationsskript. På följande GitHub-sida väljer du Ladda ned råfil.
Install-PyForMLS.ps1 installerar version 9.2.1 av Microsoft Python-paketen. Den här versionen motsvarar en SQL Server-standardinstans.
Install-PyForMLS.ps1 installerar version 9.3 av Microsoft Python-paketen.
Öppna ett PowerShell-fönster med utökade administratörsbehörigheter (högerklicka på Kör som administratör).
Gå till mappen där du laddade ned installationsprogrammet och kör skriptet. Lägg till kommandoradsargumentet
-InstallFolderför att ange en mappplats för biblioteken. Till exempel:cd {{download-directory}} .\Install-PyForMLS.ps1 -InstallFolder "C:\path-to-python-for-mls"
Om du utelämnar installationsmappen är %ProgramFiles%\Microsoft\PyForMLSstandardvärdet .
Installationen tar lite tid att slutföra. Du kan övervaka förloppet i PowerShell-fönstret. När installationen är klar har du en fullständig uppsättning paket.
Tips/Råd
Vi rekommenderar vanliga frågor och svar om Python för Windows för allmän information om hur du kör Python-program i Windows.
2 – Hitta körbara filer
I PowerShell listar du innehållet i installationsmappen för att bekräfta att Python.exe, skript och andra paket är installerade.
Ange
cd \för att gå till rotkatalogen, och ange sedan den sökväg du angav för-InstallFolderi föregående steg. Om du utelämnade den här parametern under installationen ärcd %ProgramFiles%\Microsoft\PyForMLSstandardvärdet .Ange
dir *.exeför att visa en lista över körbara filer. Du bör se python.exe, pythonw.exeoch uninstall-anaconda.exe.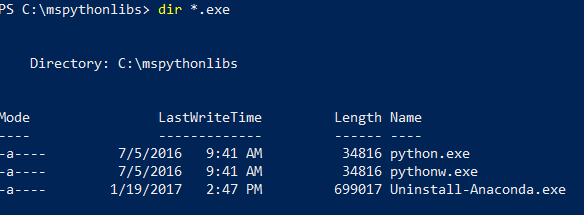
På system som har flera versioner av Python bör du komma ihåg att använda just den här Python.exe om du vill läsa in revoscalepy och andra Microsoft-paket.
Anmärkning
Installationsskriptet ändrar inte PATH-miljövariabeln på datorn, vilket innebär att den nya Python-tolken och modulerna som du nyss installerade inte är automatiskt tillgängliga för andra verktyg som du kanske har. Hjälp med att länka Python-tolken och -biblioteken till verktyg finns i Installera en IDE.
3 – Öppna Jupyter Notebooks
Anaconda innehåller Jupyter Notebooks. Som ett nästa steg skapar du en notebook-fil och kör lite Python-kod som innehåller de bibliotek som du precis har installerat.
I PowerShell-prompten, fortfarande i katalogen
%ProgramFiles%\Microsoft\PyForMLS, öppna Jupyter Notebooks från mappen Scripts..\Scripts\jupyter-notebookEn notebook-fil bör öppnas i standardwebbläsaren på
https://localhost:8889/tree.Ett annat sätt att starta är att dubbelklicka påjupyter-notebook.exe.
Välj Ny och välj sedan Python 3.
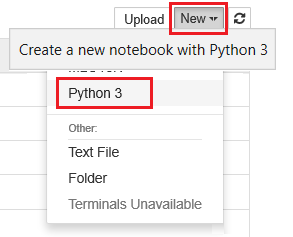
Ange
import revoscalepyoch kör kommandot för att läsa in ett av De Microsoft-specifika biblioteken.Ange och kör
print(revoscalepy.__version__)för att returnera versionsinformationen. Du bör se 9.2.1 eller 9.3.0. Du kan använda någon av dessa versioner med revoscalepy på servern.Ange en mer komplex serie med instruktioner. Det här exemplet genererar sammanfattningsstatistik med hjälp av rx_summary över en lokal datauppsättning. Andra funktioner hämtar platsen för exempeldata och skapar ett datakällaobjekt för en lokal .xdf-fil.
import os from revoscalepy import rx_summary from revoscalepy import RxXdfData from revoscalepy import RxOptions sample_data_path = RxOptions.get_option("sampleDataDir") print(sample_data_path) ds = RxXdfData(os.path.join(sample_data_path, "AirlineDemoSmall.xdf")) summary = rx_summary("ArrDelay+DayOfWeek", ds) print(summary)
Följande skärmbild visar indata och en del av utdata, trimmade för korthet.

4 – Hämta SQL-behörigheter
Om du vill ansluta till en instans av SQL Server för att köra skript och ladda upp data måste du ha en giltig inloggning på databasservern. Du kan använda antingen en SQL-inloggning eller integrerad Windows-autentisering. Vi rekommenderar vanligtvis att du använder windowsintegrerad autentisering, men att använda SQL-inloggningen är enklare för vissa scenarier, särskilt när skriptet innehåller anslutningssträngar till externa data.
Det konto som används för att köra kod måste minst ha behörighet att läsa från de databaser som du arbetar med, plus den särskilda behörigheten KÖR ALLA EXTERNA SKRIPT. De flesta utvecklare behöver också behörighet att skapa lagrade procedurer och att skriva data till tabeller som innehåller träningsdata eller poängsatta data.
Be databasadministratören att konfigurera följande behörigheter för ditt konto i databasen där du använder Python:
- KÖR ALLA EXTERNA SKRIPT för att köra Python på servern.
- db_datareader behörighet att köra de frågor som används för att träna modellen.
- db_datawriter för att skriva träningsdata eller poängsatta data.
- db_owner för att skapa objekt som lagrade procedurer, tabeller, funktioner. Du behöver också db_owner för att skapa exempel- och testdatabaser.
Om koden kräver paket som inte är installerade som standard med SQL Server kan du ordna med databasadministratören så att paketen är installerade med instansen. SQL Server är en skyddad miljö och det finns begränsningar för var paket kan installeras. Ad hoc-installation av paket som en del av koden rekommenderas inte, även om du har rättigheter. Tänk också noga på säkerhetskonsekvenserna innan du installerar nya paket i serverbiblioteket.
5 – Skapa testdata
Om du har behörighet att skapa en databas på fjärrservern kan du köra följande kod för att skapa den Iris-demodatabas som används för de återstående stegen i den här artikeln.
5-1 – Fjärrskapande av irissql-databasen
from mssql_python import connect
# creating a new db to load Iris sample in
new_db_name = "irissql"
connection_string = "Server=localhost;Database={0};Trusted_Connection=Yes;"
# you can also swap Trusted_Connection for UID={your username};PWD={your password}
conn = connect(connection_string.format("master"))
conn.setautocommit(True)
conn.cursor().execute("IF EXISTS(SELECT * FROM sys.databases WHERE [name] = '{0}') DROP DATABASE {0}".format(new_db_name))
conn.cursor().execute("CREATE DATABASE " + new_db_name)
conn.close()
print("Database created")
5–2 – Importera Iris-exempel från SkLearn
from sklearn import datasets
import pandas as pd
# SkLearn has the Iris sample dataset built in to the package
iris = datasets.load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
5–3 – Använd Revoscalepy-API:er för att skapa en tabell och läsa in Iris-data
from revoscalepy import RxSqlServerData, rx_data_step
# Example of using RX APIs to load data into SQL table. You can also do this with mssql-python
table_ref = RxSqlServerData(connection_string=connection_string.format(new_db_name), table="iris_data")
rx_data_step(input_data = df, output_file = table_ref, overwrite = True)
print("New Table Created: Iris")
print("Sklearn Iris sample loaded into Iris table")
6 – Testa fjärranslutning
Innan du provar nästa steg kontrollerar du att du har behörigheter för SQL Server-instansen och en anslutningssträng till Iris-exempeldatabasen. Om databasen inte finns och du har tillräcklig behörighet kan du skapa en databas med hjälp av dessa infogade instruktioner.
Ersätt anslutningssträngen med giltiga värden. Exempelkoden använder "Server=localhost;Database=irissql;Trusted_Connection=Yes;" men koden bör ange en fjärrserver, eventuellt med ett instansnamn, och ett alternativ för autentiseringsuppgifter som mappar till en databasinloggning.
6–1 Definiera en funktion
Följande kod definierar en funktion som du ska skicka till SQL Server i ett senare steg. När den körs använder den data och bibliotek (revoscalepy, pandas, matplotlib) på fjärrservern för att skapa punktdiagram för iris-datauppsättningen. Den returnerar byteströmmen för .png tillbaka till Jupyter Notebooks för återgivning i webbläsaren.
def send_this_func_to_sql():
from revoscalepy import RxSqlServerData, rx_import
from pandas.tools.plotting import scatter_matrix
import matplotlib.pyplot as plt
import io
# remember the scope of the variables in this func are within our SQL Server Python Runtime
connection_string = "Driver=SQL Server;Server=localhost;Database=irissql;Trusted_Connection=Yes;"
# specify a query and load into pandas dataframe df
sql_query = RxSqlServerData(connection_string=connection_string, sql_query = "select * from iris_data")
df = rx_import(sql_query)
scatter_matrix(df)
# return bytestream of image created by scatter_matrix
buf = io.BytesIO()
plt.savefig(buf, format="png")
buf.seek(0)
return buf.getvalue()
6–2 Skicka funktionen till SQL Server
I det här exemplet skapar du fjärrberäkningskontexten och skickar sedan körningen av funktionen till SQL Server med rx_exec. Funktionen rx_exec är användbar eftersom den accepterar en beräkningskontext som ett argument. Alla funktioner som du vill köra via fjärranslutning måste ha ett argument för beräkningskontext. Vissa funktioner, till exempel rx_lin_mod stöder det här argumentet direkt. För åtgärder som inte gör det kan du använda rx_exec för att leverera koden i en fjärrberäkningskontext.
I det här exemplet behövde inga rådata överföras från SQL Server till Jupyter Notebook. Alla beräkningar sker i Iris-databasen och endast avbildningsfilen returneras till klienten.
from IPython import display
import matplotlib.pyplot as plt
from revoscalepy import RxInSqlServer, rx_exec
# create a remote compute context with connection to SQL Server
sql_compute_context = RxInSqlServer(connection_string=connection_string.format(new_db_name))
# use rx_exec to send the function execution to SQL Server
image = rx_exec(send_this_func_to_sql, compute_context=sql_compute_context)[0]
# only an image was returned to my jupyter client. All data remained secure and was manipulated in my db.
display.Image(data=image)
Följande skärmbild visar inmatning och punktdiagram som utdata.

7 – Starta Python från verktyg
Eftersom utvecklare ofta arbetar med flera versioner av Python lägger inte installationen till Python i din PATH. Om du vill använda de Python-körbara filerna och biblioteken som har installerats vid installationen, länkar du din IDE till Python.exe på sökvägen som även tillhandahåller revoscalepy och microsoftml.
kommandorad
När du kör Python.exe från %ProgramFiles%\Microsoft\PyForMLS (eller vilken plats du har angett för installationen av Python-klientbiblioteket) har du åtkomst till den fullständiga Anaconda-distributionen plus Microsoft Python-modulerna, revoscalepy och microsoftml.
- Gå till
%ProgramFiles%\Microsoft\PyForMLSoch kör Python.exe. - Öppna interaktiv hjälp:
help(). - Skriv namnet på en modul i hjälpprompten:
help> revoscalepy. Hjälp returnerar namn, paketinnehåll, version och filplats. - Returnera version och paketinformation i hjälpprompten>:
revoscalepy. Tryck på Retur några gånger för att avsluta hjälpen. - Importera en modul:
import revoscalepy.
Jupyter-notebookar
Den här artikeln använder inbyggda Jupyter Notebooks för att demonstrera funktionsanrop till revoscalepy. Om du är nybörjare på det här verktyget visar följande skärmbild hur bitarna passar ihop och varför allt "bara fungerar".
Den överordnade mappen %ProgramFiles%\Microsoft\PyForMLS innehåller Anaconda plus Microsoft-paketen. Jupyter Notebooks ingår i Anaconda under mappen Skript och Python-körbara filer registreras automatiskt med Jupyter Notebooks. Paket som finns under webbplatspaket kan importeras till en notebook-fil, inklusive de tre Microsoft-paket som används för datavetenskap och maskininlärning.
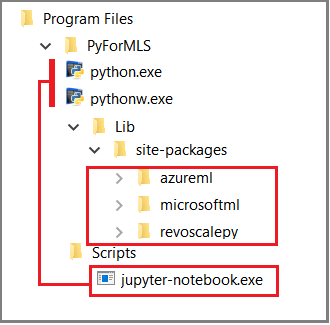
Om du använder en annan IDE måste du länka python-körbara filer och funktionsbibliotek till verktyget. Följande avsnitt innehåller instruktioner för vanliga verktyg.
Visual Studio
Om du har Python i Visual Studio använder du följande konfigurationsalternativ för att skapa en Python-miljö som innehåller Microsoft Python-paketen.
| Konfigurationsinställning | värde |
|---|---|
| Prefixsökväg | %ProgramFiles%\Microsoft\PyForMLS |
| Interpretersökväg | %ProgramFiles%\Microsoft\PyForMLS\python.exe |
| Fönstertolk | %ProgramFiles%\Microsoft\PyForMLS\pythonw.exe |
Hjälp med att konfigurera en Python-miljö finns i Hantera Python-miljöer i Visual Studio.
PyCharm
I PyCharm ställer du in tolken till den installerade körbara filen för Python.
I ett nytt projekt går du till Inställningar och väljer Lägg till lokal.
Ange
%ProgramFiles%\Microsoft\PyForMLS\.
Nu kan du importera modulerna revoscalepy, microsoftml eller azureml . Du kan också välja Verktyg>Python-konsolen för att öppna ett interaktivt fönster.