Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
gäller för:![]() SQL Server
SQL Server![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Varje SQL Server-databas har minst två operativsystemfiler: en datafil och en loggfil. Datafiler innehåller data och objekt som tabeller, index, lagrade procedurer och vyer. Loggfiler innehåller den information som krävs för att återställa alla transaktioner i databasen. Datafiler kan grupperas tillsammans i filgrupper i allokerings- och administrationssyfte.
Databasfiler
SQL Server-databaser har tre typer av filer, enligt följande tabell.
| File | Description |
|---|---|
| primär | Innehåller startinformation för databasen och pekar på de andra filerna i databasen. Varje databas har en primär datafil. Det rekommenderade filnamnstillägget för primära datafiler är .mdf. |
| Sekundär | Valfria användardefinierade datafiler. Data kan spridas över flera diskar genom att placera varje fil på en annan diskenhet. Det rekommenderade filnamnstillägget för sekundära datafiler är .ndf. |
| Transaktionsloggen | Loggen innehåller information som används för att återställa databasen. Det måste finnas minst en loggfil för varje databas. Det rekommenderade filnamnstillägget för transaktionsloggar är .ldf. |
En enkel databas med namnet Sales har till exempel en primär fil som innehåller alla data och objekt och en loggfil som innehåller transaktionslogginformationen. En mer komplex databas med namnet Orders kan skapas som innehåller en primär fil och fem sekundära filer. Data och objekt i databasen är spridda över alla sex filerna och de fyra loggfilerna innehåller transaktionslogginformationen.
Som standard placeras data- och transaktionsloggarna på samma enhet och sökväg för att hantera system med en enda disk. Det här valet kanske inte är optimalt för produktionsmiljöer. Vi rekommenderar att du placerar data och loggfiler på separata diskar.
Namn på logiska och fysiska filer
SQL Server-filer har två filnamnstyper:
logical_file_name: Namnet som används för att referera till den fysiska filen i alla Transact-SQL-instruktioner. Det logiska filnamnet måste följa reglerna för SQL Server-identifierare och måste vara unikt bland logiska filnamn i databasen.os_file_name: Namnet på den fysiska filen, inklusive katalogsökvägen. Den måste följa reglerna för operativsystemets filnamn.
Mer information om argumenten NAME och FILENAME finns i ALTER DATABASE-fil- och filgruppsalternativ.
När flera instanser av SQL Server körs på en enda dator får varje instans en annan standardkatalog för att lagra filerna för de databaser som skapats i instansen. Mer information finns i Filplatser för standardinstanser och namngivna instanser av SQL Server.
Stöd för filsystem
SQL Server-data och loggfiler kan placeras på antingen FAT- eller NTFS-filsystem. I Windows-system rekommenderar Microsoft att du använder NTFS-filsystemet eftersom säkerhetsaspekterna i NTFS.
Läs-/skrivdatafilgrupper och loggfiler stöds inte i ett NTFS-komprimerat filsystem. Endast skrivskyddade databaser och skrivskyddade sekundära filgrupper får placeras i ett NTFS-komprimerat filsystem. Använd datakomprimering i stället för filsystemkomprimering för att spara utrymme.
Datafilsidor
Sidor i en SQL Server-datafil numreras sekventiellt, från och med noll (0) för den första sidan i filen. Varje fil i en databas har ett unikt fil-ID-nummer. För att unikt identifiera en sida i en databas krävs både fil-ID och sidnummer. I följande exempel visas sidnumren i en databas som har en primär datafil på 4 MB och en sekundär datafil på 1 MB.
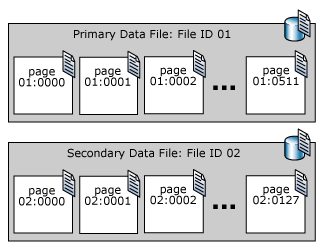
En sidhuvudsida är den första sidan som innehåller information om filens attribut. Flera av de andra sidorna i början av filen innehåller också systeminformation, till exempel allokeringskartor. En av systemsidorna som lagras i både den primära datafilen och den första loggfilen är en startsida för databasen som innehåller information om databasens attribut.
Filstorlek
SQL Server-filer kan växa automatiskt från den ursprungligen angivna storleken. När du definierar en fil kan du ange en specifik tillväxtökning. Varje gång filen fylls ökar den storleken med tillväxtökningen. Om det finns flera filer i en filgrupp kommer de inte att växa automatiskt förrän alla filer är fulla.
Mer information om sidor och sidtyper finns i arkitekturguiden För sidor och omfattningar.
Varje fil kan också ha en maximal storlek angiven. Om en maximal storlek inte har angetts kan filen fortsätta att växa tills den har använt allt tillgängligt utrymme på disken. Den här funktionen är särskilt användbar när SQL Server används som en databas inbäddad i ett program där användaren inte har praktisk åtkomst till en systemadministratör. Användaren kan låta filerna växa automatiskt efter behov för att minska den administrativa belastningen med att övervaka ledigt utrymme i databasen och manuellt allokera ytterligare utrymme.
Mer information om filhantering av transaktionsloggar finns i Hantera storleken på transaktionsloggfilen.
Ögonblicksbildsfiler för databas
Vilken typ av fil som används av en databasögonblicksbild för att lagra sina kopieringsdata beror på om ögonblicksbilden skapas av en användare eller används internt:
En ögonblicksbild av databasen som skapas av en användare lagrar sina data i en eller flera glesa filer. Teknik för glesa filer är en funktion i NTFS-filsystemet. Först innehåller en gles fil inga användardata och diskutrymmet för användardata har inte allokerats till den glesa filen. Allmän information om användningen av glesa filer i databasögonblicksbilder och hur databasögonblicksbilder växer finns i Visa storleken på den glesa filen för en databasögonblicksbild.
Databasögonblicksbilder används internt av vissa DBCC-kommandon. Dessa kommandon inkluderar
DBCC CHECKDB,DBCC CHECKTABLE,DBCC CHECKALLOCochDBCC CHECKFILEGROUP. En intern databasögonblicksbild använder sparsamma alternativa dataströmmar av de ursprungliga databasfilerna. Precis som glesa filer är alternativa dataströmmar en funktion i NTFS-filsystemet. Med hjälp av glesa alternativa dataströmmar kan flera dataallokeringar associeras med en enda fil eller mapp utan att påverka filstorleken eller volymstatistiken.
Filegroups
- Den primära filgruppen innehåller den primära datafilen och eventuella sekundära filer som inte placeras i andra filgrupper.
- Användardefinierade filgrupper kan skapas för att gruppera datafiler för administration, dataallokering och placering.
Till exempel: Data1.ndf, Data2.ndfoch Data3.ndf, kan skapas på tre diskenheter respektive tilldelas till filgruppen fgroup1. En tabell kan sedan skapas specifikt för filgruppen fgroup1. Frågor om data från tabellen sprids över de tre diskarna. det förbättrar prestandan. Samma prestandaförbättring kan uppnås genom att använda en enda fil som skapats på en RAID-randuppsättning (redundant matris med oberoende diskar). Med filer och filgrupper kan du dock enkelt lägga till nya filer till nya diskar.
Alla datafiler lagras i de filgrupper som anges i följande tabell.
| Filegroup | Description |
|---|---|
| primär | Den filgrupp som innehåller den primära filen. Alla systemtabeller ingår i den primära filgruppen. |
| Minnesoptimerade data | En minnesoptimerad filgrupp baseras på FILESTREAM-filgrupp |
| Filestream | Ostrukturerade data som lagras i filsystemkataloger. |
| Användardefinierad | Alla filgrupper som skapas av användaren när användaren först skapar eller senare ändrar databasen. |
Standardfilgrupp (primär)
När objekt skapas i databasen utan att ange vilken filgrupp de tillhör, tilldelas de till standardfilgruppen. När som helst anges exakt en filgrupp som standardfilgrupp. Filerna i standardfilgruppen måste vara tillräckligt stora för att innehålla nya objekt som inte allokerats till andra filgrupper.
Filgruppen PRIMARY är standardfilgruppen om den inte ändras med hjälp av -instruktionen ALTER DATABASE . Allokering för systemobjekt och tabeller finns kvar i PRIMARY filgruppen, inte den nya standardfilgruppen.
Minnesoptimerad datafilgrupp
Mer information om minnesoptimerade filgrupper finns i Den minnesoptimerade filgruppen.
FILESTREAM-filgrupp
Mer information om FILESTREAM-filgrupper finns i FILESTREAM och Skapa en FILESTREAM-Enabled-databas.
Fil- och filgruppsexempel
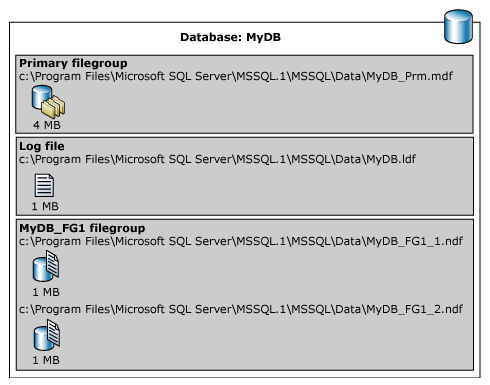
I följande exempel skapas en databas på en instans av SQL Server. Databasen har en primär datafil, en användardefinierad filgrupp och en loggfil. Den primära datafilen finns i den primära filgruppen och den användardefinierade filgruppen har två sekundära datafiler. En ALTER DATABASE instruktion gör den användardefinierade filgruppen till standard. En tabell skapas sedan som anger den användardefinierade filgruppen. (I det här exemplet används en allmän sökväg C:\Program Files\Microsoft SQL Server\MSSQL.1 för att undvika att ange en version av SQL Server.)
USE master;
GO
-- Create the database with the default data
-- filegroup, FILESTREAM filegroup and a log file. Specify the
-- growth increment and the max size for the
-- primary data file.
CREATE DATABASE MyDB
ON
PRIMARY (
NAME = 'MyDB_Primary',
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_Prm.mdf',
SIZE = 4 MB,
MAXSIZE = 10 MB,
FILEGROWTH = 1 MB
),
FILEGROUP MyDB_FG1 (
NAME = 'MyDB_FG1_Dat1',
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_FG1_1.ndf',
SIZE = 1 MB,
MAXSIZE = 10 MB, FILEGROWTH = 1 MB
), (
NAME = 'MyDB_FG1_Dat2',
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_FG1_2.ndf',
SIZE = 1 MB,
MAXSIZE = 10 MB,
FILEGROWTH = 1 MB
),
FILEGROUP FileStreamGroup1 CONTAINS FILESTREAM (
NAME = 'MyDB_FG_FS',
FILENAME = 'C:\Data\filestream1'
)
LOG ON (
NAME = 'MyDB_log',
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB.ldf',
SIZE = 1 MB,
MAXSIZE = 10 MB,
FILEGROWTH = 1 MB
);
ALTER DATABASE MyDB
MODIFY FILEGROUP MyDB_FG1 DEFAULT;
-- Create a table in the user-defined filegroup.
USE MyDB;
GO
CREATE TABLE MyTable
(
cola INT PRIMARY KEY,
colb CHAR (8)
) ON MyDB_FG1;
GO
-- Create a table in the FILESTREAM filegroup
CREATE TABLE MyFSTable
(
cola INT PRIMARY KEY,
colb VARBINARY (MAX) FILESTREAM NULL
);
Följande bild sammanfattar resultatet av föregående exempel (förutom FILESTREAM-data).
Fil- och filgruppsfyllningsstrategi
Filgrupper använder en proportionell fyllningsstrategi för alla filer i varje filgrupp. När data skrivs till filgruppen skriver SQL Server Database Engine en mängd proportionellt till det lediga utrymmet i filen till varje fil i filgruppen, i stället för att skriva alla data till den första filen tills den är full. Den skriver sedan till nästa fil. Om filen f1 till exempel har 100 MB ledigt och filen f2 har 200 MB ledigt ges en omfattning från filen f1, två omfattningar från filen f2och så vidare. På så sätt blir båda filerna fulla ungefär samtidigt och enkel striping uppnås.
Till exempel består en filgrupp av tre filer, som alla är inställda på att växa automatiskt. När utrymmet i alla filer i filgruppen är slut expanderas endast den första filen. När den första filen är full och inga fler data kan skrivas till filgruppen expanderas den andra filen. När den andra filen är full och inga fler data kan skrivas till filgruppen expanderas den tredje filen. Om den tredje filen blir full och inga fler data kan skrivas till filgruppen expanderas den första filen igen och så vidare.
Regler för att utforma filer och filgrupper
Följande regler gäller för filer och filgrupper:
En fil eller filgrupp kan inte användas av fler än en databas. För exempel, filerna
sales.mdfochsales.ndf, som innehåller data och objekt från försäljningsdatabasen, kan inte användas av någon annan databas.En fil kan bara vara medlem i en filgrupp.
Transaktionsloggfiler ingår aldrig i några filgrupper.
Recommendations
Rekommendationer när du arbetar med filer och filgrupper:
De flesta databaser fungerar bra med en enda datafil och en enda transaktionsloggfil.
Om du använder flera datafiler skapar du en andra filgrupp för den ytterligare filen och gör den filgruppen till standardfilgrupp. På så sätt innehåller den primära filen endast systemtabeller och -objekt.
För att maximera prestandan skapar du filer eller filgrupper på olika tillgängliga diskar som möjligt. Placera objekt som konkurrerar mycket om utrymme i olika filgrupper.
Använd filgrupper för att aktivera placering av objekt på specifika fysiska diskar.
Placera olika tabeller som används i samma kopplingsfrågor i olika filgrupper. Det här steget förbättrar prestandan på grund av parallell disk-I/O-sökning efter anslutna data.
Placera tabeller med hög åtkomst och de icke-grupperade index som tillhör dessa tabeller i olika filgrupper. Om du använder olika filgrupper förbättras prestandan på grund av parallell I/O om filerna finns på olika fysiska diskar.
Placera inte transaktionsloggfilerna på samma fysiska disk som har de andra filerna och filgrupperna.
Om du behöver utöka en volym eller partition där databasfiler finns med verktyg som diskpart bör du säkerhetskopiera alla system- och användardatabaser och stoppa SQL Server-tjänsterna först. När diskvolymerna har utökats bör du också överväga att köra DBCC CHECKDB-kommandot för att säkerställa den fysiska integriteten för alla databaser som finns på volymen.
Mer information om rekommendationer för filhantering av transaktionsloggar finns i Hantera storleken på transaktionsloggfilen.