Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Den här artikeln innehåller detaljerad information om hur du identifierar och löser problem som rör spinlockkonkurrens i SQL Server-program på system med hög samtidighet.
Anmärkning
Rekommendationerna och metodtipsen som dokumenteras här baseras på verkliga erfarenheter under utvecklingen och distributionen av verkliga OLTP-system. Den publicerades ursprungligen av SQLCAT-teamet (Microsoft SQL Server Customer Advisory Team).
Bakgrund
Tidigare har vanliga Windows Server-datorer endast använt en eller två mikroprocessor-/CPU-chips, och processorer har utformats med endast en enda processor eller "kärna". Ökningar av datorbearbetningskapaciteten har uppnåtts med hjälp av snabbare processorer, vilket till stor del har möjliggjorts genom framsteg inom transistordensitet. Efter "Moores lag" har transistordensiteten eller antalet transistorer som kan placeras på en integrerad krets konsekvent fördubblats vartannat år sedan utvecklingen av den första allmänna processorn för ett enda chip 1971. Under de senaste åren har den traditionella metoden att öka datorbearbetningskapaciteten med snabbare processorer utökats genom att skapa datorer med flera processorer. När detta skrivs rymmer Intel Nehalem CPU-arkitekturen upp till åtta kärnor per CPU, som när den används i ett åtta socketsystem sedan kan fördubblas till 128 logiska processorer med hjälp av samtidig multitrådsteknik (SMT). På Intel-processorer kallas SMT Hyper-Threading. När antalet logiska processorer på x86-kompatibla datorer ökar ökar samtidighetsrelaterade problem när logiska processorer konkurrerar om resurser. Den här guiden beskriver hur du identifierar och löser specifika problem med resurskonkurrens som observeras när du kör SQL Server-program på system med hög samtidighet med vissa arbetsbelastningar.
I det här avsnittet analyserar vi de insikter SQLCAT-teamet fått genom att diagnostisera och lösa konflikter med spinlocks. Spinlock-konkurrens är en typ av samtidighetsproblem som observerats i verkliga kundarbetsbelastningar i storskaliga system.
Symptom och orsaker till spinlockkonflikt
I det här avsnittet beskrivs hur du diagnostiserar problem med spinlockkonkurring, vilket är skadligt för prestanda för OLTP-program på SQL Server. Spinlock-diagnos och felsökning bör betraktas som ett avancerat ämne som kräver kunskap om felsökningsverktyg och interna Windows-funktioner.
Spinlocks är enkla synkroniseringsprimitiver som används för att skydda åtkomsten till datastrukturer. Spinlocks är inte unika för SQL Server. Operativsystemet använder dem när åtkomst till en viss datastruktur bara behövs under en kort tid. När en tråd som försöker hämta en spinlock inte kan få åtkomst körs den i en loop som regelbundet kontrollerar om resursen är tillgänglig i stället för att omedelbart ge. Efter en viss tid kommer en tråd som väntar på en spinlock att avstå innan den kan få tillgång till resursen. Genom att yielda kan andra trådar som körs på samma processor exekveras. Det här beteendet kallas för en backoff och beskrivs mer ingående senare i den här artikeln.
SQL Server använder spinlocks för att skydda åtkomsten till vissa av sina interna datastrukturer. Spinlocks används i motorn för att serialisera åtkomst till vissa datastrukturer på ett liknande sätt som lås. Den största skillnaden mellan en spärr och en spinlock är att spinlocks snurrar (kör en loop) under en viss tidsperiod för att kontrollera tillgängligheten av en datastruktur, medan en tråd som försöker få åtkomst till en struktur som skyddas av en spärr omedelbart ger upp om resursen inte är tillgänglig. För att ge resultat krävs kontextväxling av en tråd från processorn så att en annan tråd kan köras. Det här är en relativt dyr åtgärd och för resurser som hålls under en kort tid är det mer effektivt att tillåta att en tråd körs i en loop som regelbundet söker efter resursens tillgänglighet.
Interna justeringar av databasmotorn som introducerades i SQL Server 2022 (16.x) gör spinlocks mer effektiva.
Symptome
I alla upptagna system med hög samtidighet är det normalt att se aktiv konkurrens om strukturer som används ofta och som skyddas av spinlocks. Den här användningen anses endast vara problematisk när konkurrens medför betydande processorkostnader. Spinlock-statistik exponeras av sys.dm_os_spinlock_stats DMV (Dynamic Management View) i SQL Server. Den här frågan ger till exempel följande utdata:
Anmärkning
Mer information om hur du tolkar den information som returneras av denna DMV beskrivs senare i den här artikeln.
SELECT *
FROM sys.dm_os_spinlock_stats
ORDER BY spins DESC;
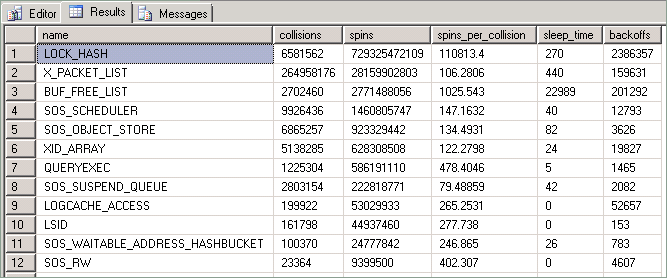
Statistiken som exponeras av den här frågan beskrivs på följande sätt:
| Kolumn | Beskrivning |
|---|---|
| Kollisioner | Det här värdet ökas varje gång en tråd blockeras från att komma åt en resurs som skyddas av en spinlock. |
| Spins | Det här värdet ökas för varje gång en tråd kör en loop i väntan på att en spinlock ska bli tillgänglig. Det här är ett mått på hur mycket arbete en tråd utför när den försöker hämta en resurs. |
| Spins_per_collision | Förhållandet mellan spinn per kollision. |
| Vilotid | Relaterat till back-off-händelser; inte relevant för tekniker som beskrivs i den här artikeln. |
| Tillbakatryck | Inträffar när en "snurrande" tråd som försöker komma åt en lagrad resurs har fastställt att den måste tillåta att andra trådar på samma CPU körs. |
I den här diskussionen är statistik av särskilt intresse antalet kollisioner, spinn och backoff-händelser som inträffar inom en viss period när systemet är hårt belastat. När en tråd försöker komma åt en resurs som skyddas av en spinlock uppstår en kollision. När en kollision inträffar ökas antalet kollisioner och tråden börjar snurra i en loop och kontrollerar regelbundet om resursen är tillgänglig. Varje gång tråden snurrar (loopar) ökas antalet spinn.
Spinn per kollision är ett mått på hur många spinn som inträffar medan en spinlock hålls av en tråd och anger hur många spinn som inträffar medan trådar håller i spinlocket. Till exempel innebär ett litet antal spinn per kollision och ett högt antal kollisioner att det sker en liten mängd spinn under en spinlock och att det finns många trådar som konkurrerar om den. En stor mängd spinn innebär att tiden som ägnas åt att spinna i spinlockkoden är relativt långlivad (det vill säga att koden går över ett stort antal poster i en hash-bucket). När konkurrensen ökar (vilket ökar antalet kollisioner) ökar också antalet spinn.
Backoffs kan tänkas på på ett liknande sätt som spinn. För att undvika överdrivet cpu-avfall fortsätter spinlocks inte att snurra på obestämd tid förrän de har åtkomst till en kvarhållen resurs. För att säkerställa att en spinlock inte använder CPU-resurser i för hög takt så pausar spinlocken eller slutar snurra och "sover". Spinlocks backar oavsett om de någonsin får ägarskap för målresursen. Detta görs för att tillåta att andra trådar schemaläggs på processorn i hopp om att detta gör att mer produktivt arbete kan ske. Standardbeteendet för motorn är att snurra under ett konstant tidsintervall först innan du utför en backoff. Försök att få en spinlock kräver att ett tillstånd för cachekonkurrens upprätthålls, vilket är en processorintensiv åtgärd i förhållande till CPU-kostnaden för spinning. Därför utförs försök att få en spinlock sparsamt och utförs inte varje gång en tråd snurrar. I SQL Server förbättrades vissa spinlocktyper (till exempel LOCK_HASH) genom att använda ett exponentiellt ökande intervall mellan försök att hämta spinlocket (upp till en viss gräns), vilket ofta minskar effekten på CPU-prestanda.
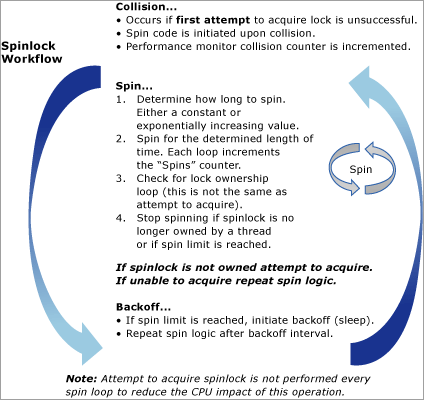
Följande diagram innehåller en konceptuell vy över spinlockalgoritmen:
Vanliga scenarier
Spinlock-konkurrens kan uppstå av valfritt antal orsaker som kan vara orelaterade till beslut om databasdesign. Eftersom spinlocks gate åtkomst till interna datastrukturer, framträder spinlockkonkurrens inte på samma sätt som buffertlåskonkurrens, som påverkas direkt av schemadesignval och dataåtkomstmönster.
Symptomet som främst förknippas med spinlockkonkurrens är hög CPU-förbrukning som ett resultat av det stora antalet spinn och många trådar som försöker skaffa samma spinlock. I allmänhet har detta observerats på system med 24 och fler CPU-kärnor, och oftast på system med mer än 32 CPU-kärnor. Som tidigare nämnts är viss konkurrens om spinlocks normalt för högkonkurrens-OLTP-system med betydande belastning, och det rapporteras ofta ett stort antal varv (miljarder/triljoner) från sys.dm_os_spinlock_stats DMV på system som har körts under lång tid. Återigen är det inte tillräckligt med information för att observera ett stort antal spinn för en viss spinlocktyp för att fastställa att det finns en negativ inverkan på arbetsbelastningens prestanda.
En kombination av flera av följande symtom kan tyda på spinlockkonkurration. Om alla dessa villkor är uppfyllda kan du undersöka eventuella problem med spinlockkonkurration ytterligare.
Ett stort antal spinn och backoffs observeras för en viss spinlocktyp.
Systemet har hög CPU-användning eller toppar i CPU-förbrukningen. I intensiva CPU-scenarier ser du höga signalväntetider på
SOS_SCHEDULER_YIELD(rapporteras av DMVsys.dm_os_wait_stats).Systemet har hög samtidighet.
Processoranvändningen och spinnen ökar oproportionerligt i förhållande till dataflödet.
Ett vanligt fenomen som är lätt att diagnostisera är en betydande skillnad i dataflöde och CPU-användning. Många OLTP-arbetsbelastningar har en relation mellan (dataflöde/antal användare i systemet) och CPU-förbrukning. Höga spinn som observeras i samband med en betydande skillnad i CPU-förbrukning och dataflöde kan vara en indikation på spinlockkonkurrens som introducerar CPU-omkostnader. En viktig sak att notera här är att det också är vanligt att se den här typen av skillnader i system när vissa frågor blir dyrare över tid. Till exempel kan frågor som utfärdas mot datauppsättningar som utför fler logiska läsningar över tid resultera i liknande symtom.
Viktigt!
Det är viktigt att utesluta andra vanliga orsaker till hög CPU när du felsöker dessa typer av problem.
Även om vart och ett av ovanstående villkor är sant är det fortfarande möjligt att grundorsaken för hög CPU-förbrukning ligger någon annanstans. Faktum är att i de allra flesta fall beror ökad CPU på andra orsaker än spinlockkonkurration.
Några av de vanligaste orsakerna till ökad CPU-förbrukning är:
- Frågor som blir dyrare över tid på grund av tillväxten av underliggande data, vilket resulterar i behovet av att utföra ytterligare logiska läsningar av minnesbaserade data.
- Ändringar i frågeplaner som resulterar i suboptimalt utförande.
Exempel
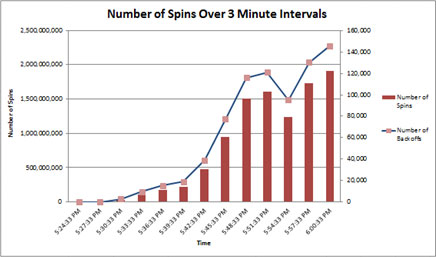
I följande exempel finns det en nästan linjär relation mellan CPU-förbrukning och dataflöde mätt med transaktioner per sekund. Det är normalt att se vissa skillnader här eftersom omkostnaderna uppstår när alla arbetsbelastningar ökar. Som illustreras här blir denna divergering betydande. Det finns också en kraftig minskning av dataflödet när CPU-förbrukningen når 100%.

När vi mäter antalet spinn med 3 minuters intervall kan vi se en mer exponentiell ökning av spinn än linjär, vilket indikerar att spinlockkonkurrens kan vara problematisk.
Som tidigare nämnts är spinlocks vanligast på system med hög samtidighet som är hårt belastade.
Några av de scenarier som är utsatta för det här problemet är:
Problem med namnmatchning som orsakas av att det inte går att fullständigt kvalificera namn på objekt. Mer information finns i Beskrivning av SQL Server-blockering som orsakas av kompileringslås. Det här specifika problemet beskrivs mer detaljerat i den här artikeln.
Konkurrens om lås-hash-bucketar i låshanteraren för arbetsbelastningar som ofta har åtkomst till samma lås (till exempel ett delat lås på en rad som ofta läses). Den här typen av konkurrens visas som en
LOCK_HASHtypspinlock. I ett visst fall upptäckte vi att det här problemet uppstod till följd av felaktigt modellerade åtkomstmönster i en testmiljö. I den här miljön kom fler än förväntat antal trådar ständigt åt exakt samma rad på grund av felaktigt konfigurerade testparametrar.Hög grad av DTC-transaktioner när det finns hög svarstid mellan MSDTC-transaktionskoordinatorerna. Det här specifika problemet dokumenteras i detalj i SQLCAT-blogginlägget Lösa DTC-relaterade väntetider och justera skalbarhet för DTC.
Diagnostisera spinlockkonkurrens
Det här avsnittet innehåller information om hur du diagnostiserar SQL Server-spinlockkonkurration. De primära verktygen som används för att diagnostisera spinlockkonflikt är:
| Verktyg | Använd |
|---|---|
| Prestandaövervakare | Leta efter höga CPU-förhållanden eller skillnader mellan dataflöde och CPU-förbrukning. |
| Spinlock-statistik | Fråga sys.dm_os_spinlock_stats DMV för att leta efter ett stort antal spinn och backoff-händelser under tidsperioder. |
| Väntestatistik | Från och med förhandsversionen av SQL Server 2025 (17.x) kan du fråga sys.dm_os_wait_stats och sys.dm_exec_session_wait_stats DMVs med hjälp av väntetypen SPINLOCK_EXT. Kräver spårningsflagga 8134. Mer information finns i SPINLOCK_EXT. |
| Utökade SQL Server-händelser | Används för att spåra anropsstackar för spinlocks som har ett högt antal spin. |
| Minnesdumpar | I vissa fall kan minnesdumpar skapas från SQL Server-processen och använda Windows-felsökningsverktygen. I allmänhet görs den här analysnivån när Microsofts supportteam är engagerade. |
Den allmänna tekniska processen för att diagnostisera SQL Server Spinlock-konkurrens är:
Steg 1: Fastställ om det finns konkurrens som kan vara relaterad till spinlock.
Steg 2: Samla in statistik från
sys.dm_os_spinlock_statsför att hitta den spinlocktyp som har mest konkurrens.Steg 3: Hämta felsökningssymboler för sqlservr.exe (sqlservr.pdb) och placera symbolerna i samma katalog som SQL Server-tjänsten .exe fil (sqlservr.exe) för SQL Server-instansen.\ För att kunna se anropsstackarna för backoff-händelserna måste du ha symboler för den specifika version av SQL Server som du kör. Symboler för SQL Server finns på Microsoft Symbol Server. Mer information om hur du laddar ned symboler från Microsoft Symbol Server finns i Felsökning med symboler.
Steg 4: Använd SQL Server Extended Events för att spåra backoff-händelser för spinlock-typerna av intresse. De händelser som ska avbildas är
spinlock_backoffochspinlock_backoff_warning.
Extended Events ger möjlighet att spåra backoff-händelser, och fånga anropsstacken för de operationer som oftast försöker få tillgång till spinlocket. Genom att analysera anropsstacken är det möjligt att avgöra vilken typ av åtgärd som bidrar till konkurrens för en viss spinlock.
Genomgång av diagnostik
Följande genomgång visar hur du använder dessa verktyg och tekniker för att diagnostisera ett problem med spinlockkonkurrens i en praktisk situation. Den här genomgången baseras på ett kundengagemang som kör ett benchmark-test för att simulera cirka 6 500 samtidiga användare på en 8 socket, 64 fysisk kärnserver med 1 TB minne.
Symptome
Periodiska toppar i CPU observerades, vilket drev cpu-användningen till nästan 100%. En skillnad mellan dataflöde och CPU-förbrukning observerades som ledde fram till problemet. När den stora CPU-toppen inträffade upprättades ett mönster för ett stort antal spinn under tider med hög CPU-användning med särskilda intervall.
Detta var ett extremt fall där det var sådan konkurrens att det skapade ett spinlock-konvojtillstånd. En konvoj inträffar när trådar inte längre kan fortskrida med att hantera arbetsbelastningen, utan istället använder alla bearbetningsresurser för att försöka få åtkomst till låset. Prestandaövervakarloggen illustrerar den här skillnaden mellan transaktionsloggens dataflöde och CPU-förbrukning och i slutändan den stora ökningen av CPU-användningen.
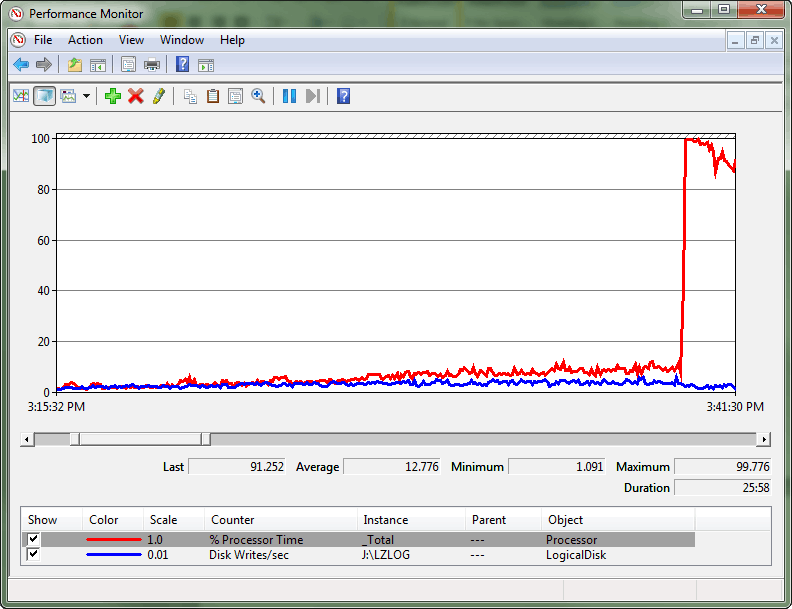
Efter att ha frågat sys.dm_os_spinlock_stats för att fastställa förekomsten av betydande konkurrens på SOS_CACHESTOREanvändes ett skript för utökade händelser för att mäta antalet backoff-händelser för spinlock-typerna av intresse.
| Namn | Kollisioner | Snurrar | Snurrar per kollision | Avståndstagande |
|---|---|---|---|---|
SOS_CACHESTORE |
14,752,117 | 942,869,471,526 | 63,914 | 67,900,620 |
SOS_SUSPEND_QUEUE |
69,267,367 | 473,760,338,765 | 6,840 | 2,167,281 |
LOCK_HASH |
5,765,761 | 260,885,816,584 | 45,247 | 3,739,208 |
MUTEX |
2,802,773 | 9,767,503,682 | 3,485 | 350,997 |
SOS_SCHEDULER |
1,207,007 | 3,692,845,572 | 3,060 | 109,746 |
Det enklaste sättet att kvantifiera effekten av spinn är att titta på antalet backoff-händelser som exponeras med sys.dm_os_spinlock_stats över samma 1-minutersintervall för spinlock-typerna med det högsta antalet spinn. Den här metoden är bäst att identifiera betydande konkurrens eftersom den anger när trådarna överskrider spinngränsen i väntan på att få tag på spinlocket. Följande skript illustrerar en avancerad teknik som använder utökade händelser för att mäta relaterade backoff-händelser och identifiera de specifika kodvägar där konkurrensen uppstår.
Mer information om utökade händelser i SQL Server finns i Översikt över utökade händelser.
Skript
/*
This script is provided "AS IS" with no warranties, and confers no rights.
This script will monitor for backoff events over a given period of time and
capture the code paths (callstacks) for those.
--Find the spinlock types
select map_value, map_key, name from sys.dm_xe_map_values
where name = 'spinlock_types'
order by map_value asc
--Example: Get the type value for any given spinlock type
select map_value, map_key, name from sys.dm_xe_map_values
where map_value IN ('SOS_CACHESTORE', 'LOCK_HASH', 'MUTEX')
Examples:
61LOCK_HASH
144 SOS_CACHESTORE
08MUTEX
*/
--create the even session that will capture the callstacks to a bucketizer
--more information is available in this reference: http://msdn.microsoft.com/en-us/library/bb630354.aspx
CREATE EVENT SESSION spin_lock_backoff ON SERVER
ADD EVENT sqlos.spinlock_backoff (
ACTION(package0.callstack) WHERE type = 61 --LOCK_HASH
OR TYPE = 144 --SOS_CACHESTORE
OR TYPE = 8 --MUTEX
) ADD TARGET package0.asynchronous_bucketizer (
SET filtering_event_name = 'sqlos.spinlock_backoff',
source_type = 1,
source = 'package0.callstack'
)
WITH (
MAX_MEMORY = 50 MB,
MEMORY_PARTITION_MODE = PER_NODE
);
--Ensure the session was created
SELECT * FROM sys.dm_xe_sessions
WHERE name = 'spin_lock_backoff';
--Run this section to measure the contention
ALTER EVENT SESSION spin_lock_backoff ON SERVER STATE = START;
--wait to measure the number of backoffs over a 1 minute period
WAITFOR DELAY '00:01:00';
--To view the data
--1. Ensure the sqlservr.pdb is in the same directory as the sqlservr.exe
--2. Enable this trace flag to turn on symbol resolution
DBCC TRACEON (3656, -1);
--Get the callstacks from the bucketizer target
SELECT event_session_address,
target_name,
execution_count,
cast(target_data AS XML)
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spin_lock_backoff';
--clean up the session
ALTER EVENT SESSION spin_lock_backoff ON SERVER STATE = STOP;
DROP EVENT SESSION spin_lock_backoff ON SERVER;
Genom att analysera utdata kan vi se anropsstaplarna för de vanligaste kodvägarna för rotationerna SOS_CACHESTORE. Skriptet kördes flera gånger under den period då processoranvändningen var hög för att kontrollera konsekvensen i de returnerade anropsstackarna. Anropsstackarna med det högsta antalet slots är gemensamma mellan de två utdata (35 668 och 8 506). Dessa anropsstackar har ett fackantal som är två storleksordningar större än den näst högsta posten. Det här villkoret anger en kodväg som är av intresse.
Anmärkning
Det är inte ovanligt att anropsstackar returneras av det föregående skriptet. När skriptet kördes i 1 minut observerade vi att anropsstackar med ett fackantal på > 1 000 var problematiska, men antalet > fack på 10 000 var mer sannolikt problematiskt eftersom det är ett högre antal platser.
Anmärkning
Formateringen av följande utdata har rensats i läsbarhetssyfte.
Utdata 1
<BucketizerTarget truncated="0" buckets="256">
<Slot count="35668" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep
SpinlockBase::Backoff
Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid
CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey
CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
NTGroupInfo::`vector deleting destructor'
</value>
</Slot>
<Slot count="752" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep
SpinlockBase::Backoff
Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
</value>
</Slot>
Resultat 2
<BucketizerTarget truncated="0" buckets="256">
<Slot count="8506" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep+c7 [ @ 0+0x0 SpinlockBase::Backoff Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
NTGroupInfo::`vector deleting destructor'
</value>
</Slot>
<Slot count="190" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep
SpinlockBase::Backoff
Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
</value>
</Slot>
I föregående exempel har de mest intressanta staplarna det högsta antalet fack (35 668 och 8 506), som faktiskt har ett antal fack som är större än 1 000.
Nu kan frågan vara "vad gör jag med den här informationen"? I allmänhet krävs djup kunskap om SQL Server-motorn för att använda anropsstackens information, så just nu flyttas felsökningsprocessen till ett grått område. I det här fallet kan vi genom att titta på anropsstackarna se att kodsökvägen där problemet uppstår är relaterad till säkerhets- och metadatasökningar (vilket framgår av följande stackramar CMEDCatalogOwner::GetProxyOwnerBySID & CMEDProxyDatabase::GetOwnerBySID).
Isolerat är det svårt att använda den här informationen för att lösa problemet, men det ger oss några idéer där du kan fokusera ytterligare felsökning för att isolera problemet ytterligare.
Eftersom det här problemet såg ut att vara relaterat till kodsökvägar som utför säkerhetsrelaterade kontroller bestämde vi oss för att köra ett test där programanvändaren som ansluter till databasen beviljades sysadmin behörigheter. Den här tekniken rekommenderas aldrig i en produktionsmiljö, men i vår testmiljö visade det sig vara ett användbart felsökningssteg. När sessionerna kördes med utökade privilegier (sysadmin) försvann cpu-toppar relaterade till konkurrens.
Alternativ och lösningar
Det är uppenbart att felsökning av spinlockkonkurration kan vara en icke-trivial uppgift. Det finns ingen "en gemensam bästa metod". Det första steget vid felsökning och lösning av eventuella prestandaproblem är att identifiera grundorsaken. Att använda de tekniker och verktyg som beskrivs i den här artikeln är det första steget i att utföra den analys som behövs för att förstå de spinlockrelaterade konkurrenspunkterna.
När nya versioner av SQL Server utvecklas fortsätter motorn att förbättra skalbarheten genom att implementera kod som är bättre optimerad för system med hög samtidighet. SQL Server har introducerat många optimeringar för system med hög samtidighet, varav en är exponentiell backoff för de vanligaste konkurrenspunkterna. Det finns förbättringar från och med SQL Server 2012 som specifikt förbättrade det här området genom att utnyttja exponentiella backoff-algoritmer för alla spinlocks i motorn.
När du utformar avancerade program som behöver extrem prestanda och skalning bör du överväga hur du ska hålla den kodsökväg som behövs i SQL Server så kort som möjligt. En kortare kodsökväg innebär att mindre arbete utförs av databasmotorn och undviker naturligtvis konkurrenspunkter. Många metodtips har en bieffekt av att minska mängden arbete som krävs av motorn och därmed resultera i optimering av arbetsbelastningsprestanda.
Ta några metodtips från tidigare i den här artikeln som exempel:
Fullständigt kvalificerade namn: Fullständigt kvalificerade namn på alla objekt eliminerar behovet för SQL Server att köra källkodsvägar som behövs för att lösa namn. Vi har observerat konfliktpunkter även på den
SOS_CACHESTOREspinlock-typ som uppstod när fullständigt kvalificerade namn inte används i anrop till lagrade procedurer. Om de här namnen inte är fullständigt kvalificerade resulterar det i behovet av att SQL Server söker efter standardschemat för användaren, vilket resulterar i en längre kodsökväg som krävs för att köra SQL.Parameteriserade frågor: Ett annat exempel är att använda parametriserade frågor och lagrade proceduranrop för att minska det arbete som krävs för att generera utförandeplaner. Detta resulterar återigen i en kortare körväg för koden vid exekvering.
LOCK_HASHKonkurrens: Konkurrens om låsningsstrukturen eller hash-bucket-kollisioner är oundviklig i vissa fall. Även om SQL Server-motorn partitionerar de flesta låsstrukturer, finns det fortfarande tillfällen då att ta ett lås leder till åtkomst av samma hash-bucket. Till exempel får ett program åtkomst till samma rad av många trådar samtidigt (det vill säga referensdata). Dessa typer av problem kan hanteras av tekniker som antingen skalar ut dessa referensdata i databasschemat eller använder optimistisk samtidighetskontroll och optimerad låsning när det är möjligt.
Den första försvarslinjen vid justering av SQL Server-arbetsbelastningar är alltid standardjusteringsmetoderna (till exempel indexering, frågeoptimering, I/O-optimering osv.). Dock, utöver den standardjustering som man skulle utföra, är det viktigt att använda metoder som minskar mängden kod som behövs för att utföra operationer. Även när bästa praxis följs finns det fortfarande en chans att spinlock-konflikt kan uppstå på belastade system med hög samtidighet. Användning av verktygen och teknikerna i den här artikeln kan hjälpa till att isolera eller utesluta dessa typer av problem och avgöra när det är nödvändigt att engagera rätt Microsoft-resurser för att hjälpa till.
Bilaga: Automatisera insamling av minnesdumpar
Följande skript för utökade händelser har visat sig vara mycket användbart för att automatisera insamlingen av minnesdumpar när spinlock-tvist blir betydande. I vissa fall krävs minnesdumpar för att utföra en fullständig diagnos av problemet eller begärs av Microsoft-teamen att utföra djupgående analys.
Följande SQL-skript kan användas för att automatisera processen med att samla in minnesdumpar för att analysera spinlockkonkurration:
/*
This script is provided "AS IS" with no warranties, and confers no rights.
Use: This procedure will monitor for spinlocks with a high number of backoff events
over a defined time period which would indicate that there is likely significant
spin lock contention.
Modify the variables noted below before running.
Requires:
xp_cmdshell to be enabled
sp_configure 'xp_cmd', 1
go
reconfigure
go
*********************************************************************************************************/
USE tempdb;
GO
IF object_id('sp_xevent_dump_on_backoffs') IS NOT NULL
DROP PROCEDURE sp_xevent_dump_on_backoffs;
GO
CREATE PROCEDURE sp_xevent_dump_on_backoffs (
@sqldumper_path NVARCHAR(max) = '"c:\Program Files\Microsoft SQL Server\100\Shared\SqlDumper.exe"',
@dump_threshold INT = 500, --capture mini dump when the slot count for the top bucket exceeds this
@total_delay_time_seconds INT = 60, --poll for 60 seconds
@PID INT = 0,
@output_path NVARCHAR(MAX) = 'c:\',
@dump_captured_flag INT = 0 OUTPUT
)
AS
/*
--Find the spinlock types
select map_value, map_key, name from sys.dm_xe_map_values
where name = 'spinlock_types'
order by map_value asc
--Example: Get the type value for any given spinlock type
select map_value, map_key, name from sys.dm_xe_map_values
where map_value IN ('SOS_CACHESTORE', 'LOCK_HASH', 'MUTEX')
*/
IF EXISTS (
SELECT *
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spinlock_backoff_with_dump'
)
DROP EVENT SESSION spinlock_backoff_with_dump
ON SERVER
CREATE EVENT SESSION spinlock_backoff_with_dump ON SERVER
ADD EVENT sqlos.spinlock_backoff (
ACTION(package0.callstack) WHERE type = 61 --LOCK_HASH
--or type = 144 --SOS_CACHESTORE
--or type = 8 --MUTEX
--or type = 53 --LOGCACHE_ACCESS
--or type = 41 --LOGFLUSHQ
--or type = 25 --SQL_MGR
--or type = 39 --XDESMGR
) ADD target package0.asynchronous_bucketizer (
SET filtering_event_name = 'sqlos.spinlock_backoff',
source_type = 1,
source = 'package0.callstack'
)
WITH (
MAX_MEMORY = 50 MB,
MEMORY_PARTITION_MODE = PER_NODE
)
ALTER EVENT SESSION spinlock_backoff_with_dump ON SERVER STATE = START;
DECLARE @instance_name NVARCHAR(MAX) = @@SERVICENAME;
DECLARE @loop_count INT = 1;
DECLARE @xml_result XML;
DECLARE @slot_count BIGINT;
DECLARE @xp_cmdshell NVARCHAR(MAX) = NULL;
--start polling for the backoffs
PRINT 'Polling for: ' + convert(VARCHAR(32), @total_delay_time_seconds) + ' seconds';
WHILE (@loop_count < CAST(@total_delay_time_seconds / 1 AS INT))
BEGIN
WAITFOR DELAY '00:00:01'
--get the xml from the bucketizer for the session
SELECT @xml_result = CAST(target_data AS XML)
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spinlock_backoff_with_dump';
--get the highest slot count from the bucketizer
SELECT @slot_count = @xml_result.value(N'(//Slot/@count)[1]', 'int');
--if the slot count is higher than the threshold in the one minute period
--dump the process and clean up session
IF (@slot_count > @dump_threshold)
BEGIN
PRINT 'exec xp_cmdshell ''' + @sqldumper_path + ' ' + convert(NVARCHAR(max), @PID) + ' 0 0x800 0 c:\ '''
SELECT @xp_cmdshell = 'exec xp_cmdshell ''' + @sqldumper_path + ' ' + convert(NVARCHAR(max), @PID) + ' 0 0x800 0 ' + @output_path + ' '''
EXEC sp_executesql @xp_cmdshell
PRINT 'loop count: ' + convert(VARCHAR(128), @loop_count)
PRINT 'slot count: ' + convert(VARCHAR(128), @slot_count)
SET @dump_captured_flag = 1
BREAK
END
--otherwise loop
SET @loop_count = @loop_count + 1
END;
--see what was collected then clean up
DBCC TRACEON (3656, -1);
SELECT event_session_address,
target_name,
execution_count,
cast(target_data AS XML)
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spinlock_backoff_with_dump';
ALTER EVENT SESSION spinlock_backoff_with_dump ON SERVER STATE = STOP;
DROP EVENT SESSION spinlock_backoff_with_dump ON SERVER;
GO
/* CAPTURE THE DUMPS
******************************************************************/
--Example: This will run continuously until a dump is created.
DECLARE @sqldumper_path NVARCHAR(MAX) = '"c:\Program Files\Microsoft SQL Server\100\Shared\SqlDumper.exe"';
DECLARE @dump_threshold INT = 300; --capture mini dump when the slot count for the top bucket exceeds this
DECLARE @total_delay_time_seconds INT = 60; --poll for 60 seconds
DECLARE @PID INT = 0;
DECLARE @flag TINYINT = 0;
DECLARE @dump_count TINYINT = 0;
DECLARE @max_dumps TINYINT = 3; --stop after collecting this many dumps
DECLARE @output_path NVARCHAR(max) = 'c:\'; --no spaces in the path please :)
--Get the process id for sql server
DECLARE @error_log TABLE (
LogDate DATETIME,
ProcessInfo VARCHAR(255),
TEXT VARCHAR(max)
);
INSERT INTO @error_log
EXEC ('xp_readerrorlog 0, 1, ''Server Process ID''');
SELECT @PID = convert(INT, (REPLACE(REPLACE(TEXT, 'Server Process ID is ', ''), '.', '')))
FROM @error_log
WHERE TEXT LIKE ('Server Process ID is%');
PRINT 'SQL Server PID: ' + convert(VARCHAR(6), @PID);
--Loop to monitor the spinlocks and capture dumps. while (@dump_count < @max_dumps)
BEGIN
EXEC sp_xevent_dump_on_backoffs @sqldumper_path = @sqldumper_path,
@dump_threshold = @dump_threshold,
@total_delay_time_seconds = @total_delay_time_seconds,
@PID = @PID,
@output_path = @output_path,
@dump_captured_flag = @flag OUTPUT
IF (@flag > 0)
SET @dump_count = @dump_count + 1
PRINT 'Dump Count: ' + convert(VARCHAR(2), @dump_count)
WAITFOR DELAY '00:00:02'
END;
Bilaga: Statistik för spinlock samlas in över tid
Följande skript kan användas för att titta på spinlockstatistik under en viss tidsperiod. Varje gång den körs returneras skillnaden mellan aktuella värden och tidigare värden som samlats in.
/* Snapshot the current spinlock stats and store so that this can be compared over a time period
Return the statistics between this point in time and the last collection point in time.
**This data is maintained in tempdb so the connection must persist between each execution**
**alternatively this could be modified to use a persisted table in tempdb. if that
is changed code should be included to clean up the table at some point.**
*/
USE tempdb;
GO
DECLARE @current_snap_time DATETIME;
DECLARE @previous_snap_time DATETIME;
SET @current_snap_time = GETDATE();
IF NOT EXISTS (
SELECT name
FROM tempdb.sys.sysobjects
WHERE name LIKE '#_spin_waits%'
)
CREATE TABLE #_spin_waits (
lock_name VARCHAR(128),
collisions BIGINT,
spins BIGINT,
sleep_time BIGINT,
backoffs BIGINT,
snap_time DATETIME
);
--capture the current stats
INSERT INTO #_spin_waits (
lock_name,
collisions,
spins,
sleep_time,
backoffs,
snap_time
)
SELECT name,
collisions,
spins,
sleep_time,
backoffs,
@current_snap_time
FROM sys.dm_os_spinlock_stats;
SELECT TOP 1 @previous_snap_time = snap_time
FROM #_spin_waits
WHERE snap_time < (
SELECT max(snap_time)
FROM #_spin_waits
)
ORDER BY snap_time DESC;
--get delta in the spin locks stats
SELECT TOP 10 spins_current.lock_name,
(spins_current.collisions - spins_previous.collisions) AS collisions,
(spins_current.spins - spins_previous.spins) AS spins,
(spins_current.sleep_time - spins_previous.sleep_time) AS sleep_time,
(spins_current.backoffs - spins_previous.backoffs) AS backoffs,
spins_previous.snap_time AS [start_time],
spins_current.snap_time AS [end_time],
DATEDIFF(ss, @previous_snap_time, @current_snap_time) AS [seconds_in_sample]
FROM #_spin_waits spins_current
INNER JOIN (
SELECT *
FROM #_spin_waits
WHERE snap_time = @previous_snap_time
) spins_previous
ON (spins_previous.lock_name = spins_current.lock_name)
WHERE spins_current.snap_time = @current_snap_time
AND spins_previous.snap_time = @previous_snap_time
AND spins_current.spins > 0
ORDER BY (spins_current.spins - spins_previous.spins) DESC;
--clean up table
DELETE
FROM #_spin_waits
WHERE snap_time = @previous_snap_time;