Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
gäller för:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() SQL-databas i Microsoft Fabric
SQL-databas i Microsoft Fabric
SQL Server 2016 (13.x) introducerar driftanalys i realtid, möjligheten att köra både analys- och OLTP-arbetsbelastningar på samma databastabeller samtidigt. Förutom att köra analys i realtid kan du också eliminera behovet av ETL och ett informationslager.
Förklarad driftanalys i realtid
Traditionellt har företag haft separata system för drift (dvs. OLTP) och analysarbetsbelastningar. För sådana system flyttar ETL-jobb (Extract, Transform, and Load) regelbundet data från driftlagret till ett analysarkiv. Analysdata lagras vanligtvis i ett informationslager eller data mart som är dedikerade till att köra analysfrågor. Även om den här lösningen har varit standard har den följande tre viktiga utmaningar:
- Komplexitet. Implementering av ETL kan kräva betydande kodning, särskilt för att endast läsa in de ändrade raderna. Det kan vara komplext att identifiera vilka rader som har ändrats.
- Kostnad. Implementering av ETL kräver kostnaden för att köpa ytterligare maskin- och programvarulicenser.
- Datasvarstid. Implementering av ETL lägger till en tidsfördröjning för att köra analysen. Om ETL-jobbet till exempel körs i slutet av varje arbetsdag körs analysfrågorna på data som är minst en dag gamla. För många företag är den här fördröjningen oacceptabel eftersom verksamheten är beroende av att analysera data i realtid. Bedrägeriidentifiering kräver till exempel realtidsanalys av driftdata.
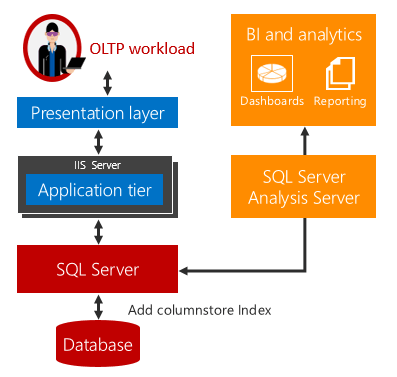
Driftanalys i realtid erbjuder en lösning på dessa utmaningar.
Det finns ingen tidsfördröjning när analys- och OLTP-arbetsbelastningar körs i samma underliggande tabell. För scenarier som kan använda realtidsanalys minskar kostnaderna och komplexiteten avsevärt genom att eliminera behovet av ETL och behovet av att köpa och underhålla ett separat informationslager.
Anmärkning
Driftanalyser i realtid är inriktade på scenariot för en enskild datakälla, till exempel ett ERP-program (Enterprise Resource Planning) där du kan köra både den operativa arbetsbelastningen och analysarbetsbelastningen. Detta ersätter inte behovet av ett separat informationslager när du behöver integrera data från flera källor innan du kör analysarbetsbelastningen eller när du behöver extrema analysprestanda med föraggregerade data, till exempel kuber.
Realtidsanalys använder ett uppdateringsbart icke-kopplat kolumnlagerindex i en radlagringstabell. Kolumnlagringsindexet underhåller en kopia av data, så OLTP- och analysarbetsbelastningarna körs mot separata kopior av data. Detta minimerar prestandapåverkan för båda arbetsbelastningarna som körs samtidigt. Databasmotorn underhåller automatiskt indexändringar så att OLTP-ändringar alltid up-todatum för analys. Med den här designen är det möjligt och praktiskt att köra analys i realtid på up-todatumdata. Detta fungerar för både diskbaserade och minnesoptimerade tabeller.
Kom igång-exempel
Så här kommer du igång med realtidsanalys:
Identifiera tabellerna i ditt driftschema som innehåller data som krävs för analys.
För varje tabell släpper du alla B-trädindex som främst är utformade för att påskynda befintlig analys av din OLTP-arbetsbelastning. Ersätt dem med ett enda icke-grupperat kolumnlagringsindex. Detta kan förbättra den övergripande prestandan för din OLTP-arbetsbelastning eftersom det finns färre index att underhålla.
--This example creates a nonclustered columnstore index on an existing OLTP table. --Create the table CREATE TABLE t_account ( accountkey int PRIMARY KEY, accountdescription nvarchar (50), accounttype nvarchar(50), unitsold int ); --Create the columnstore index with a filtered condition CREATE NONCLUSTERED COLUMNSTORE INDEX account_NCCI ON t_account (accountkey, accountdescription, unitsold) ;Kolumnlagringsindexet i en minnesoptimerad tabell gör det möjligt att använda analys genom att integrera minnesintern OLTP- och columnstore-tekniker för att leverera höga prestanda för både OLTP- och analysarbetsbelastningar. I en minnesoptimerad tabell måste kolumnlagringsindexet vara det klustrade indexet, vilket innebär att det måste inkludera alla kolumner.
-- This example creates a memory-optimized table with a columnstore index. CREATE TABLE t_account ( accountkey int NOT NULL PRIMARY KEY NONCLUSTERED, Accountdescription nvarchar (50), accounttype nvarchar(50), unitsold int, INDEX t_account_cci CLUSTERED COLUMNSTORE ) WITH (MEMORY_OPTIMIZED = ON );
Nu är du redo att köra driftanalyser i realtid utan att göra några ändringar i ditt program. Analysfrågor körs mot kolumnlagringsindexet och OLTP-åtgärder fortsätter att köras mot dina OLTP B-trädindex. OLTP-arbetsbelastningarna fortsätter att prestera, men medför vissa extra kostnader för att underhålla kolumnlagringsindexet. Se prestandaoptimeringarna i nästa avsnitt.
Blogginlägg
Läs följande blogginlägg om du vill veta mer om driftanalys i realtid. Det kan vara lättare att förstå avsnitten med prestandatips om du tittar på blogginläggen först.
Använda ett icke-klustrat kolumnlagringsindex för driftanalys i realtid
Ett enkelt exempel med ett icke-grupperat kolumnlagringsindex
Så underhåller SQL Server ett icke-klustrat kolumnbutiksindex i en transaktionsarbetsbelastning
Minimera effekten av icke-grupperat kolumnlagringsindexunderhåll med hjälp av ett filtrerat index
Minimera effekten av icke-grupperat columnstore-indexunderhåll med hjälp av komprimeringsfördröjning
Columnstore-index och sammanslagningsprincipen för radgrupper
Videoklipp
Videoserien Data Exposed innehåller mer information om några av funktionerna och övervägandena.
- Del 1: Så här aktiverar Azure SQL driftsanalys i realtid (HTAP)
- Del 2: Optimera befintliga databaser och program med driftanalys
- Del 3: Så här skapar du driftanalyser med Window Functions.
Prestandatips nr 1: Använd filtrerade index för att förbättra frågeprestanda
Körning av driftanalyser i realtid kan påverka prestanda för OLTP-arbetsbelastningen. Den här effekten bör vara minimal. Exempel A visar hur du använder filtrerade index för att minimera påverkan av icke-grupperade kolumnlagringsindex på transaktionsarbetsbelastningar samtidigt som analys levereras i realtid.
För att minimera kostnaderna för att underhålla ett icke-grupperat kolumnlagringsindex för en driftsarbetsbelastning kan du använda ett filtrerat villkor för att skapa ett icke-grupperat kolumnlagringsindex endast på varma eller långsamt föränderliga data. I ett orderhanteringsprogram kan du till exempel skapa ett icke-grupperat kolumnlagringsindex på de beställningar som redan har levererats. När beställningen har levererats ändras den sällan och kan därför betraktas som varma data. Med ett filtrerat index kräver data i ett icke-grupperat columnstore-index färre uppdateringar, vilket minskar påverkan på transaktionsarbetsbelastningen.
Analyssökningar har transparent åtkomst till både varm och het data vid behov för att tillhandahålla realtidsanalys. Om en betydande del av den operativa arbetsbelastningen rör "frekventa" data, kräver dessa åtgärder inte ytterligare underhåll av kolumnlagringsindexet. Bästa praxis är att ha ett grupperat rowstore-index på de kolumner som används i den filtrerade indexdefinitionen. Databasmotorn använder det klustrade indexet för att snabbt genomsöka de rader som inte uppfyllde det filtrerade villkoret. Utan det här klustrade indexet krävs en fullständig tabellgenomsökning av radlagringstabellen för att hitta dessa rader, vilket kan påverka prestandan för analysfrågor negativt. I avsaknad av klustrade index kan du skapa ett kompletterande filtrerat B-trädindex som inte är grupperat för att identifiera sådana rader, men det rekommenderas inte eftersom det är dyrt att komma åt ett stort antal rader via icke-grupperade B-trädindex.
Anmärkning
Ett filtrerat icke-grupperat kolumnlagringsindex stöds endast i diskbaserade tabeller. Det stöds inte i minnesoptimerade tabeller.
Exempel A: Få åtkomst till frekventa data från B-trädindex, varma data från kolumnlagringsindex
I det här exemplet används ett filtrerat villkor (accountkey > 0) för att fastställa vilka rader som ingår i kolumnlagringsindexet. Målet är att utforma det filtrerade villkoret och efterföljande frågor för att komma åt snabbt föränderliga "heta" data från B+-trädindexet och att komma åt stabila "varma" data från kolumnlagringsindexet.

Anmärkning
Frågeoptimeraren tar hänsyn till, men väljer inte alltid, kolumnlagringsindexet för frågeplanen. När frågeoptimeraren väljer det filtrerade kolumnlagringsindexet, kombinerar den på ett genomskinligt sätt rader både från kolumnlagringsindexet och de rader som inte uppfyller det filtrerade villkoret för att möjliggöra realtidsanalys. Detta skiljer sig från ett vanligt icke-grupperat filtrerat index som endast kan användas i frågor som begränsar sig till de rader som finns i indexet.
-- Use a filtered condition to separate hot data in a rowstore table
-- from "warm" data in a columnstore index.
-- create the table
CREATE TABLE orders (
AccountKey int not null,
CustomerName nvarchar (50),
OrderNumber bigint,
PurchasePrice decimal (9,2),
OrderStatus smallint not null,
OrderStatusDesc nvarchar (50)
);
-- OrderStatusDesc
-- 0 => 'Order Started'
-- 1 => 'Order Closed'
-- 2 => 'Order Paid'
-- 3 => 'Order Fulfillment Wait'
-- 4 => 'Order Shipped'
-- 5 => 'Order Received'
CREATE CLUSTERED INDEX orders_ci ON orders(OrderStatus);
--Create the columnstore index with a filtered condition
CREATE NONCLUSTERED COLUMNSTORE INDEX orders_ncci ON orders (accountkey, customername, purchaseprice, orderstatus)
WHERE OrderStatus = 5;
-- The following query returns the total purchase done by customers for items > $100 .00
-- This query will pick rows both from NCCI and from 'hot' rows that are not part of NCCI
SELECT TOP (5) CustomerName, SUM(PurchasePrice)
FROM orders
WHERE PurchasePrice > 100.0
GROUP BY CustomerName;
Analysfrågan körs med följande frågeplan. Du kan se att raderna som inte uppfyller det filtrerade villkoret nås via klustrat B-trädindex.

Mer information finns i Blogg: Filtrerat icke-grupperat columnstore-index.
Prestandatips nr 2: Avlasta analys till AlwaysOn läsbar sekundär
Även om du kan minimera underhållet av columnstore-indexet med hjälp av ett filtrerat kolumnlagringsindex, kan analysfrågorna fortfarande kräva betydande beräkningsresurser (CPU, I/O, minne) som påverkar prestandan för den operativa arbetsbelastningen. För de flesta verksamhetskritiska arbetsbelastningar rekommenderar vi att du använder AlwaysOn-konfigurationen. I den här konfigurationen kan du eliminera effekten av att köra analys genom att avlasta den till en läsbar sekundär.
Prestandatips nr 3: Minska indexfragmenteringen genom att behålla heta data i deltaradgrupper
Tabeller med columnstore-index kan bli betydligt fragmenterade (dvs. borttagna rader) om arbetsbelastningen uppdaterar/tar bort rader som har komprimerats. Ett fragmenterat kolumnlagringsindex leder till ineffektiv användning av minne/lagring. Förutom ineffektiv användning av resurser påverkar det även analysfrågans prestanda negativt på grund av extra I/O och behovet av att filtrera de borttagna raderna från resultatuppsättningen.
De borttagna raderna tas inte bort fysiskt förrän du kör indexdefragmentering med REORGANIZE kommandot eller återskapar kolumnlagringsindexet i hela tabellen eller de berörda partitionerna. Både index REORGANIZE och REBUILD är dyra åtgärder som tar bort resurser som annars skulle kunna användas för arbetsbelastningen. Om rader komprimeras för tidigt kan det dessutom behöva komprimeras flera gånger på grund av uppdateringar som leder till bortkastade komprimeringskostnader.
Du kan minimera indexfragmenteringen med hjälp av COMPRESSION_DELAY alternativet .
-- Create a sample table
CREATE TABLE t_colstor (
accountkey int not null,
accountdescription nvarchar (50) not null,
accounttype nvarchar(50),
accountCodeAlternatekey int
);
-- Creating nonclustered columnstore index with COMPRESSION_DELAY.
-- The columnstore index will keep the rows in closed delta rowgroup
-- for 100 minutes after it has been marked closed.
CREATE NONCLUSTERED COLUMNSTORE INDEX t_colstor_cci ON t_colstor
(accountkey, accountdescription, accounttype)
WITH (DATA_COMPRESSION = COLUMNSTORE, COMPRESSION_DELAY = 100);
Mer information finns i Blogg: Komprimeringsfördröjning.
Här är de rekommenderade metodtipsen:
Infoga/fråga arbetsbelastning: Om din arbetsbelastning främst infogar data och frågar efter dem är standardvärdet
COMPRESSION_DELAY0 det rekommenderade alternativet. De nyligen infogade raderna komprimeras när 1 miljon rader har infogats i en enda deltaradgrupp. Några exempel på sådana arbetsbelastningar är en traditionell DW-arbetsbelastning eller en select-stream-analys när du behöver analysera select-mönstret i ett webbprogram.OLTP-arbetsbelastning: Om arbetsbelastningen är DML-tung (d.v.s. en tung blandning av Uppdatering, Ta bort och Infoga) kan du se fragmentering av kolumnlagringsindex genom att undersöka DMV
sys.dm_db_column_store_row_group_physical_stats. Om du ser att > 10% rader har markerats som borttagna i nyligen komprimerade radgrupper kan du användaCOMPRESSION_DELAYalternativet för att lägga till tidsfördröjning när rader blir berättigade till komprimering. Till exempel, om den nyligen infogade för din arbetsbelastning förblir "het" (det vill säga uppdateras flera gånger) i ungefär 60 minuter, bör du sättaCOMPRESSION_DELAYtill 60.
Standardvärdet COMPRESSION_DELAY för alternativet bör fungera för de flesta kunder.
För avancerade användare rekommenderar vi att du kör följande fråga och samlar in % borttagna rader under de senaste sju dagarna.
SELECT row_group_id,
CAST(deleted_rows AS float)/CAST(total_rows AS float)*100 AS [% fragmented],
created_time
FROM sys.dm_db_column_store_row_group_physical_stats
WHERE object_id = OBJECT_ID('FactOnlineSales2')
AND state_desc = 'COMPRESSED'
AND deleted_rows > 0
AND created_time > DATEADD(day, -7, GETDATE())
ORDER BY created_time DESC;
Om antalet borttagna rader i komprimerade radgrupper > 20%% COMPRESSION_DELAY anger < du = (youngest_rowgroup_created_time - current_time). Den här metoden fungerar bäst med en stabil och relativt homogen arbetsbelastning.