Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Gäller för:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Analysplattformssystem (PDW)
Analysplattformssystem (PDW)![]() SQL-databas i Microsoft Fabric
SQL-databas i Microsoft Fabric
SQL Server använder kopplingar för att hämta data från flera tabeller baserat på logiska relationer mellan dem. Kopplingar är grundläggande för relationsdatabasåtgärder och gör att du kan kombinera data från två eller flera tabeller till en enda resultatuppsättning.
SQL Server implementerar både logiska kopplingsåtgärder (definieras av Transact-SQL syntax) och fysiska kopplingsåtgärder (de faktiska algoritmer som används för att köra kopplingarna). Genom att förstå båda aspekterna kan du skriva effektiva frågor och optimera databasprestanda.
Logiska kopplingsåtgärder omfattar:
- Inre kopplingar
- Vänster, höger och fullständig yttre kopplingar
- Korskopplingar
Fysiska kopplingsåtgärder omfattar:
- Kapslade loopar ansluter
- Sammanfoga kopplingar
- Hash-kopplingar
- Anpassningsbara kopplingar (gäller för: SQL Server 2017 (14.x) och senare versioner)
Den här artikeln beskriver hur kopplingar fungerar, när olika kopplingstyper ska användas och hur Frågeoptimeraren väljer den mest effektiva kopplingsalgoritmen baserat på faktorer som tabellstorlek, tillgängliga index och datadistribution.
Note
Mer information om kopplingssyntax finns i FROM-satsen plus JOIN, APPLY, PIVOT.
Gå med i grunderna
Genom att använda kopplingar kan du hämta data från två eller flera tabeller baserat på logiska relationer mellan tabellerna. Kopplingar anger hur SQL Server ska använda data från en tabell för att välja raderna i en annan tabell.
Ett kopplingsvillkor definierar hur två tabeller är relaterade i en fråga genom att:
- Ange kolumnen från varje tabell som ska användas för kopplingen. Ett typiskt kopplingsvillkor anger en sekundärnyckel från en tabell och dess associerade nyckel i den andra tabellen.
- Ange en logisk operator (till exempel = eller <>,) som ska användas för att jämföra värden från kolumnerna.
Kopplingar uttrycks logiskt med hjälp av följande Transact-SQL syntax:
[ INNER ] JOINLEFT [ OUTER ] JOINRIGHT [ OUTER ] JOINFULL [ OUTER ] JOINCROSS JOIN
Inre kopplingar kan anges i satserna FROM eller WHERE .
Yttre kopplingar och korskopplingar kan endast anges i FROM -satsen. Kopplingsvillkoren kombineras med WHERE-sökvillkoren och HAVING för att styra de rader som väljs från de bastabeller som refereras i FROM-satsen.
Genom att ange kopplingsvillkoren i FROM -satsen kan du skilja dem från andra sökvillkor som kan anges i en WHERE -sats och är den rekommenderade metoden för att ange kopplingar. En förenklad ISO-satskopplingssyntax FROM är:
FROM first_table < join_type > second_table [ ON ( join_condition ) ]
- Join_type anger vilken typ av koppling som utförs: en inre, yttre eller korskoppling. Förklaringar av de olika typerna av kopplingar finns i FROM-satsen.
- Join_condition definierar predikatet som ska utvärderas för varje par med kopplade rader.
Följande kod är ett exempel på en betingelse för sammanlänkning av satser FROM:
FROM Purchasing.ProductVendor INNER JOIN Purchasing.Vendor
ON ( ProductVendor.BusinessEntityID = Vendor.BusinessEntityID )
Följande kod är en enkel SELECT instruktion med hjälp av denna sammanslagning:
SELECT ProductID, Purchasing.Vendor.BusinessEntityID, Name
FROM Purchasing.ProductVendor INNER JOIN Purchasing.Vendor
ON (Purchasing.ProductVendor.BusinessEntityID = Purchasing.Vendor.BusinessEntityID)
WHERE StandardPrice > $10
AND Name LIKE N'F%';
GO
Instruktionen SELECT returnerar produkt- och leverantörsinformationen för alla kombinationer av delar som tillhandahålls av ett företag för vilka företagsnamnet börjar med bokstaven F och priset på produkten är mer än 10 USD.
När flera tabeller refereras till i en enda fråga måste alla kolumnreferenser vara entydiga. I föregående exempel har både tabellen ProductVendor och Vendor en kolumn med namnet BusinessEntityID. Alla kolumnnamn som dupliceras mellan två eller flera tabeller som refereras i frågan måste vara kvalificerade med tabellnamnet. Alla referenser till kolumnerna Vendor i exemplet är kvalificerade.
När ett kolumnnamn inte dupliceras i två eller flera tabeller som används i frågan behöver referenser till den inte kvalificeras med tabellnamnet. Detta visas i föregående exempel.
SELECT En sådan sats är ibland svår att förstå eftersom det inte finns något som anger tabellen som tillhandahöll varje kolumn. Frågans läsbarhet förbättras om alla kolumner är kvalificerade med sina tabellnamn. Läsbarheten förbättras ytterligare om tabellalias används, särskilt när själva tabellnamnen måste kvalificeras med databas- och ägarnamnen. Följande kod är samma exempel, förutom att tabellalias har tilldelats och kolumnerna har kvalificerats med tabellalias för att förbättra läsbarheten:
SELECT pv.ProductID, v.BusinessEntityID, v.Name
FROM Purchasing.ProductVendor AS pv
INNER JOIN Purchasing.Vendor AS v
ON (pv.BusinessEntityID = v.BusinessEntityID)
WHERE StandardPrice > $10
AND Name LIKE N'F%';
I föregående exempel angavs kopplingsvillkoren i FROM -satsen, vilket är den föredragna metoden. Följande fråga innehåller samma kopplingsvillkor som anges i WHERE -satsen:
SELECT pv.ProductID, v.BusinessEntityID, v.Name
FROM Purchasing.ProductVendor AS pv, Purchasing.Vendor AS v
WHERE pv.BusinessEntityID=v.BusinessEntityID
AND StandardPrice > $10
AND Name LIKE N'F%';
Listan SELECT för en koppling kan referera till alla kolumner i de anslutna tabellerna eller någon delmängd av kolumnerna. Listan SELECT krävs inte för att innehålla kolumner från varje tabell i kopplingen. I en koppling med tre tabeller kan till exempel endast en tabell användas för att överbrygga från en av de andra tabellerna till den tredje tabellen, och ingen av kolumnerna från den mellersta tabellen behöver refereras till i urvalslistan. Detta kallas även för en anti-semikoppling.
Även om kopplingsvillkor vanligtvis har likhetsjämförelser (=), kan andra jämförelse- eller relationsoperatorer anges, liksom andra predikat. Mer information finns i Jämförelseoperatorer och WHERE.
När SQL Server-processer ansluts väljer Frågeoptimeraren den mest effektiva metoden (av flera möjligheter) för bearbetning av kopplingen. Detta inkluderar att välja den mest effektiva typen av fysisk koppling, i vilken ordning tabellerna ska kopplas och även använda typer av logiska kopplingsåtgärder som inte kan uttryckas direkt med Transact-SQL syntax, till exempel halvkopplingar och anti-semikopplingar. Den fysiska körningen av olika kopplingar kan använda många olika optimeringar och kan därför inte förutsägas på ett tillförlitligt sätt. Mer information om semikopplingar och anti-semikopplingar finns i Operatorreferens för logisk och fysisk showplan.
Kolumner som används i ett kopplingsvillkor behöver inte ha samma namn eller vara samma datatyp. Men om datatyperna inte är identiska måste de vara kompatibla eller vara typer som SQL Server implicit kan konvertera. Om datatyperna inte kan konverteras implicit måste kopplingsvillkoret explicit konvertera datatypen med hjälp av CAST funktionen. Mer information om implicita och explicita konverteringar finns i Datatypskonvertering (databasmotor).
De flesta frågor som använder en koppling kan skrivas om med hjälp av en underfråga (en fråga kapslad i en annan fråga) och de flesta underfrågor kan skrivas om som kopplingar. Mer information om underfrågor finns i Underfrågor (SQL Server).
Note
Tabeller kan inte kopplas direkt i ntext-, text- eller bildkolumner. Tabeller kan dock sammanfogas indirekt på ntext-, text- eller bildkolumner med hjälp av SUBSTRING.
Utför till exempel SELECT * FROM t1 JOIN t2 ON SUBSTRING(t1.textcolumn, 1, 20) = SUBSTRING(t2.textcolumn, 1, 20) en inre koppling med två tabeller på de första 20 tecknen i varje textkolumn i tabeller t1 och t2.
Dessutom är en annan möjlighet att jämföra ntext- eller textkolumner från två tabeller att jämföra längden på kolumnerna med en WHERE sats, till exempel: WHERE DATALENGTH(p1.pr_info) = DATALENGTH(p2.pr_info)
Förstå kapslade loop-sammanslagningar
Om en kopplingsindata är liten (färre än 10 rader) och den andra indata är ganska stor och är indexerad på sina kopplingskolumner, är en indexerad kapslad loop-sammanfogning den snabbaste sammanfogningsoperationen eftersom de kräver minst I/O och minst jämförelser.
Den kapslade loopkopplingen, även kallad kapslad iteration, använder en kopplingsinmatning som den yttre indatatabellen (visas som de översta indata i den grafiska körningsplanen) och en som den inre (nedre) indatatabellen. Den yttre slingan bearbetar den yttre indatatabellen rad för rad. Den inre loopen, som körs för varje yttre rad, söker efter matchande rader i den inre indatatabellen.
I det enklaste fallet söker sökningen igenom en hel tabell eller ett helt index. Detta kallas för en naiv kapslad loopkoppling. Om sökningen utnyttjar ett index kallas det för en indexkapslad loopanslutning. Om indexet skapas som en del av frågeplanen (och förstörs när frågan har slutförts) kallas det för en tillfällig indexkapslad loopkoppling. Alla dessa varianter beaktas av Frågeoptimeraren.
En kapslad loopkoppling är särskilt effektiv om den yttre indatan är liten och den inre indatan är förindexerad och stor. I många små transaktioner, till exempel de som bara påverkar en liten uppsättning rader, är indexkapslade loopar överlägsna både sammanslagningskopplingar och hashkopplingar. I stora frågor är dock kapslade loopar ofta inte det optimala valet.
När attributet OPTIMIZED för en kapslad loopkopplingsoperator är inställd på True innebär det att optimerade kapslade loopar (eller Batch-sortering) används för att minimera I/O när den inre sidotabellen är stor, oavsett om den parallelliseras eller inte. Förekomsten av den här optimeringen i en viss plan kanske inte är särskilt uppenbar när du analyserar en exekveringsplan, med tanke på att sorteringen i sig är en dold åtgärd. Men genom att titta i plan-XML för attributet OPTIMIZED indikerar detta att de kapslade looparna kan försöka att omordna inmatningsraderna för att förbättra I/O-prestanda.
Sammanfoga kopplingar
Om de två kopplingsindata inte är små men sorteras i deras kopplingskolumn (till exempel om de hämtades genom genomsökning av sorterade index) är en sammanslagningskoppling den snabbaste kopplingsåtgärden. Om båda kopplingsindata är stora och de två indata är av liknande storlek, ger en sammanslagningskoppling med tidigare sortering och en hashkoppling liknande prestanda. Hashkopplingsåtgärderna är dock ofta mycket snabbare om de två indatastorlekarna skiljer sig avsevärt från varandra.
Kopplingskopplingen kräver att båda indata sorteras på sammanslagningskolumnerna, som definieras av likhetssatserna (ON) i kopplingspredikatet. Frågeoptimeraren söker vanligtvis igenom ett index, om det finns ett på rätt uppsättning kolumner, eller placerar en sorteringsoperator under sammanslagningskopplingen. I sällsynta fall kan det finnas flera likhetssatser, men sammanslagningskolumnerna hämtas endast från några av de tillgängliga likhetssatserna.
Eftersom varje indata sorteras hämtar operatorn Merge Join en rad från varje indata och jämför dem. För inre kopplingsåtgärder returneras till exempel raderna om de är lika. Om de inte är lika med tas raden med lägre värde bort och en annan rad hämtas från indata. Den här processen upprepas tills alla rader har bearbetats.
Sammanfogningsoperationen är antingen en vanlig operation eller en många-till-många-operation. En många-till-många-sammanfogning använder en tillfällig tabell för att lagra datarader. Om det finns duplicerade värden i varje indata måste en av dem spolas tillbaka till början av dubbletterna när varje dubblett från det andra indata hanteras.
Om det finns ett restpredikat utvärderar alla rader som uppfyller sammanslagningspredikatet restpredikatet och endast de rader som uppfyller det returneras.
Sammanfogningskopplingen i sig är mycket snabb, men det kan vara ett dyrt val om sorteringsoperationer krävs. Men om datavolymen är stor och önskade data kan hämtas i förväg från befintliga B-trädindex är sammanslagningskoppling ofta den snabbaste tillgängliga kopplingsalgoritmen.
Hash-kopplingar
Hash-kopplingar kan effektivt bearbeta stora, osorterade, icke-indexerade indata. De är användbara för mellanliggande resultat i komplexa frågor eftersom:
- Mellanliggande resultat indexeras inte (om de inte uttryckligen sparas på disken och sedan indexeras) och sorteras ofta inte på lämpligt sätt för nästa åtgärd i frågeplanen.
- Frågeoptimerare uppskattar endast mellanliggande resultatstorlekar. Eftersom uppskattningar kan vara mycket felaktiga för komplexa frågor måste algoritmer för att bearbeta mellanliggande resultat inte bara vara effektiva, utan måste också försämras korrekt om ett mellanliggande resultat visar sig vara mycket större än förväntat.
Hash-kopplingen tillåter minskningar av användningen av avnormalisering. Avormalisering används vanligtvis för att uppnå bättre prestanda genom att minska kopplingsåtgärderna, trots farorna med redundans, till exempel inkonsekventa uppdateringar. Hash-kopplingar minskar behovet av att avnormalisera. Hash-kopplingar tillåter vertikal partitionering (som representerar grupper av kolumner från en enskild tabell i separata filer eller index) för att bli ett genomförbart alternativ för fysisk databasdesign.
Hash-kopplingen har två indata: kompileringsindata och avsökningsindata . Frågeoptimeraren tilldelar dessa roller så att den mindre av de två indata är byggindata.
Hashkopplingar används för många typer av set-matching-åtgärder: inre koppling; vänster, höger och fullständig yttre koppling; vänster och höger halvkoppling; vägkorsning; union; och skillnad. Dessutom kan en variant av hash-kopplingen göra dubblettborttagning och gruppering, till exempel SUM(salary) GROUP BY department. Dessa ändringar använder endast en inmatning för både bygg- och avsökningsrollerna.
I följande avsnitt beskrivs olika typer av hashkopplingar: hashkoppling i minnet, grace-hash-koppling och rekursiv hashkoppling.
Minnesintern hashkoppling
Hash-kopplingen söker först igenom eller beräknar hela byggindata och skapar sedan en hash-tabell i minnet. Varje rad infogas i en hash-bucket beroende på hash-värdet som beräknas för hash-nyckeln. Om hela byggindata är mindre än det tillgängliga minnet kan alla rader infogas i hash-tabellen. Den här byggfasen följs av avsökningsfasen. Hela avsökningsindata genomsöks eller beräknas en rad i taget, och för varje avsökningsrad beräknas hashnyckelns värde, motsvarande hash-bucket genomsöks och matchningarna skapas.
Grace hash-koppling
Om byggindata inte får plats i minnet fortsätter en hashkoppling i flera steg. Detta kallas för en grace-hashkoppling. Varje steg har en byggfas och avsökningsfas. Till en början förbrukas och partitioneras alla indata för bygg- och avsökningar (med hjälp av en hash-funktion på hash-nycklarna) i flera filer. Genom att använda hash-funktionen på hash-nycklarna garanteras att två matchande poster måste finnas i samma filpar. Därför har uppgiften att koppla två stora indata reducerats till flera, men mindre, instanser av samma uppgifter. Hash-kopplingen tillämpas sedan på varje par partitionerade filer.
Rekursiv hash-koppling
Om byggindata är så stora att indata för en extern standardsammanslagning kräver flera sammanslagningsnivåer krävs flera partitioneringssteg och flera partitioneringsnivåer. Om bara vissa partitioner är stora används ytterligare partitioneringssteg endast för de specifika partitionerna. För att göra alla partitioneringssteg så snabba som möjligt används stora, asynkrona I/O-åtgärder så att en enda tråd kan hålla flera diskenheter upptagna.
Note
Om kompileringsindata bara är något större än det tillgängliga minnet kombineras element i minnesintern hashkoppling och grace-hashkoppling i ett enda steg, vilket skapar en hybridhashkoppling.
Det är inte alltid möjligt under optimeringen att avgöra vilken hashkoppling som används. Därför börjar SQL Server med en minnesintern hashkoppling och övergår gradvis till grace-hashkoppling och rekursiv hashkoppling, beroende på storleken på byggindata.
Om Frågeoptimeraren förväntar sig felaktigt vilken av de två indata som är mindre och därför borde ha varit byggindata, återställs rollerna för bygg och avsökning dynamiskt. Hash-kopplingen ser till att den använder den mindre spillfilen som byggindata. Den här tekniken kallas rollåtervändning. Rollåtervändning sker inuti hash-kopplingen efter minst ett spill till disken.
Note
Rollåtervändning sker oberoende av frågetips eller struktur. Rollåtervändning visas inte i frågeplanen. när det inträffar är det transparent för användaren.
Hash-räddningsaktion
Termen hash-räddningsaktion används ibland för att beskriva grace hash-kopplingar eller rekursiva hashkopplingar.
Note
Rekursiva hash-kopplingar eller hash-frånkopplingar orsakar försämrad prestanda på din server. Om du ser många Hash-varningshändelser i en spårning uppdaterar du statistiken för de kolumner som ansluts.
Mer information om hash-bailout finns i Hash Warning Event Class (Hash-varningshändelseklass).
Anpassningsbara kopplingar
Batch-läge Med anpassningsbara kopplingar kan du skjuta upp valet av en Hash-koppling eller Kapslade loop-koppling tills det första indatat har genomsökts. Operatorn Adaptive Join definierar ett tröskelvärde som används för att bestämma när en kapslad loopplan ska växlas. En frågeplan kan därför växla dynamiskt till en bättre sammankopplingsstrategi under exekveringen utan att behöva kompileras om.
Tip
Arbetsbelastningar med frekventa svängningar mellan små och stora genomsökningar av kopplingsindata drar mest nytta av den här funktionen.
Körningsbeslutet baseras på följande steg:
- Om radantalet för kompileringsindata är tillräckligt litet för att en kapslad loopanslutning ska vara mer optimal än en Hash-koppling växlar planen till en algoritm för kapslade loopar.
- Om indata för byggkoppling överskrider ett visst tröskelvärde för antal rader sker ingen växel och planen fortsätter med en Hash-koppling.
Följande fråga används för att illustrera ett exempel på adaptiv koppling:
SELECT [fo].[Order Key], [si].[Lead Time Days], [fo].[Quantity]
FROM [Fact].[Order] AS [fo]
INNER JOIN [Dimension].[Stock Item] AS [si]
ON [fo].[Stock Item Key] = [si].[Stock Item Key]
WHERE [fo].[Quantity] = 360;
Frågan returnerar 336 rader. När du aktiverar Live Query-statistik visas följande plan:

Observera följande i planen:
- En kolumnlagringsindexsökning som används för att tillhandahålla rader för hash-kopplingens uppbyggnadsfas.
- Den nya adaptiva kopplingsoperatorn. Den här operatorn definierar ett tröskelvärde som används för att bestämma när man ska växla till en Nested Loops-plan. I det här exemplet är tröskelvärdet 78 rader. Allt med >= 78 rader använder en Hash-koppling. Om det är mindre än tröskelvärdet används en kapslad loopkoppling.
- Eftersom frågan returnerar 336 rader överskred detta tröskelvärdet, så den andra grenen representerar avsökningsfasen för en standardåtgärd för Hash-koppling. Live Query Statistics visar rader som flödar genom operatorerna – i det här fallet "672 av 672".
- Och den sista grenen är en klustrad indexsökning som används i Nested Loops-sammanfogning om tröskelvärdet inte överskrids. Vi ser "0 av 336" rader visas (grenen är oanvänd).
Jämför nu planen med samma fråga, men när Quantity värdet bara har en rad i tabellen:
SELECT [fo].[Order Key], [si].[Lead Time Days], [fo].[Quantity]
FROM [Fact].[Order] AS [fo]
INNER JOIN [Dimension].[Stock Item] AS [si]
ON [fo].[Stock Item Key] = [si].[Stock Item Key]
WHERE [fo].[Quantity] = 361;
Frågan returnerar en rad. När du aktiverar livefrågestatistik visas följande plan:

Observera följande i planen:
- När en rad har returnerats har den klustrade indexsökningen nu rader som passerar genom den.
- Och eftersom fasen Hash Join inte fortsatte finns det inga rader som flödar genom den andra grenen.
Anmärkningar om adaptiva kopplingar
Anpassningsbara sammanslagningar kräver högre minnesanvändning än en ekvivalent plan för indexerad Nested Loops Join. Det ytterligare minnet begärs som om kapslade loopar var en Hash-koppling. Det finns också kostnader för byggfasen som en stop-and-go-åtgärd jämfört med en motsvarande koppling för nested Loops-strömning. Med den extra kostnaden kommer flexibilitet för scenarier där antalet rader varierar i byggindata.
Adaptiva kopplingar i batchläge fungerar för den första körningen av en -instruktion, och när de har kompilerats förblir efterföljande körningar anpassningsbara baserat på det kompilerade tröskelvärdet för adaptiv koppling och körningsrader som flödar genom byggfasen av de yttre indata.
Om en Adaptiv Join växlar till en kapslad loop-operation, använder den sig av raderna som redan har lästs in av byggfasen för Hash Join. Operatorn läser inte de yttre referensraderna igen.
Spåra anpassningsbar kopplingsaktivitet
Operatorn Adaptive Join har följande planoperatorattribut:
| Planattribut | Description |
|---|---|
| AdaptiveThresholdRows | Visar tröskelvärdet för att växla från en hash-koppling till kapslad loopkoppling. |
| EstimatedJoinType | Vilken kopplingstyp kommer troligen att vara. |
| ActualJoinType | I en faktisk plan visar vilken kopplingsalgoritm som slutligen valdes baserat på tröskelvärdet. |
Den uppskattade planen visar formen adaptiv kopplingsplan, tillsammans med ett definierat tröskelvärde för anpassningsbar koppling och uppskattad kopplingstyp.
Tip
Query Store registrerar och kan tvinga fram en adaptiv kopplingsplan i batchläge.
Anpassningsbara kopplingsberättigande instruktioner
Några villkor gör en logisk koppling berättigad till en adaptiv koppling i batchläge:
- Databasens kompatibilitetsnivå är 140 eller högre.
- Frågan är en
SELECTinstruktion (datamodifieringsinstruktioner är för närvarande inte tillgängliga). - Kopplingen är berättigad att köras både av en indexerad kapslad loopanslutning eller en fysisk Hash-kopplingsalgoritm.
- Hash-kopplingen använder Batch-läge, aktiverat genom förekomsten av ett kolumnlagringsindex i frågan totalt sett, en kolumnlagringsindexerad tabell som refereras direkt av kopplingen eller genom användning av Batch-läget i radarkivet.
- De genererade alternativa lösningarna för kapslade loopar och Hash-anslutning bör ha samma första barnnod (yttre referens).
Anpassningsbara tröskelvärdesrader
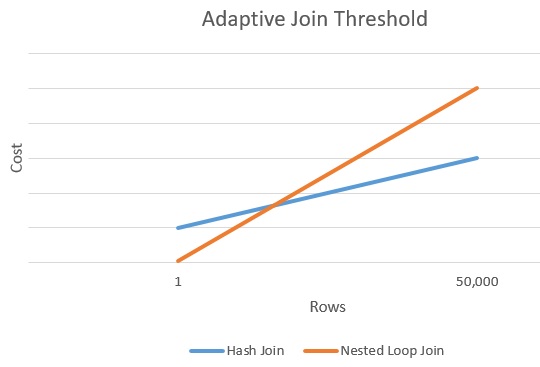
Följande diagram visar ett exempel på en skärningspunkt mellan kostnaden för en Hash-koppling jämfört med kostnaden för ett kapslade loopkopplingsalternativ. Vid den här skärningspunkten fastställs tröskelvärdet att i sin tur avgör den faktiska algoritmen som används för kopplingsåtgärden.
Inaktivera anpassningsbara kopplingar utan att ändra kompatibilitetsnivån
Anpassningsbara kopplingar kan inaktiveras i databas- eller instruktionsomfånget samtidigt som databaskompatibilitetsnivån 140 och högre bibehålls.
Om du vill inaktivera adaptiva kopplingar för alla frågor som kommer från databasen, kör följande i den tillämpliga databasens kontext:
-- SQL Server 2017
ALTER DATABASE SCOPED CONFIGURATION SET DISABLE_BATCH_MODE_ADAPTIVE_JOINS = ON;
-- Azure SQL Database, SQL Server 2019 and later versions
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ADAPTIVE_JOINS = OFF;
När den här inställningen är aktiverad visas den som aktiverad i sys.database_scoped_configurations.
Om du vill återaktivera anpassningsbara kopplingar för alla frågekörningar som kommer från databasen kör du följande i kontexten för den tillämpliga databasen:
-- SQL Server 2017
ALTER DATABASE SCOPED CONFIGURATION SET DISABLE_BATCH_MODE_ADAPTIVE_JOINS = OFF;
-- Azure SQL Database, SQL Server 2019 and later versions
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ADAPTIVE_JOINS = ON;
Anpassningsbara sammanfogningar kan också inaktiveras för en specifik fråga genom att ange DISABLE_BATCH_MODE_ADAPTIVE_JOINS som ett USE HINT-kommando. Till exempel:
SELECT s.CustomerID,
s.CustomerName,
sc.CustomerCategoryName
FROM Sales.Customers AS s
LEFT OUTER JOIN Sales.CustomerCategories AS sc
ON s.CustomerCategoryID = sc.CustomerCategoryID
OPTION (USE HINT('DISABLE_BATCH_MODE_ADAPTIVE_JOINS'));
Note
Ett USE HINT frågetips har företräde framför en databasomfattande konfigurations- eller spårningsflaggainställning.
Null-värden och kopplingar
När det finns null-värden i kolumnerna i tabellerna som kopplas matchar inte null-värdena varandra. Förekomsten av null-värden i en kolumn från en av tabellerna som kopplas kan endast returneras med hjälp av en yttre koppling (såvida inte WHERE satsen utesluter null-värden).
Här är två tabeller som var och en har NULL i kolumnen som ska delta i kopplingen:
table1 table2
a b c d
------- ------ ------- ------
1 one NULL two
NULL three 4 four
4 join4
En koppling som jämför värdena i kolumnen a mot kolumnen c får ingen matchning på de kolumner som har värden för NULL:
SELECT *
FROM table1 t1 JOIN table2 t2
ON t1.a = t2.c
ORDER BY t1.a;
GO
Endast en rad med värdet 4 i kolumner a och c returneras:
a b c d
----------- ------ ----------- ------
4 join4 4 four
(1 row(s) affected)
Null-värden som returneras från en bastabell är också svåra att skilja från de null-värden som returneras från en yttre koppling. Följande instruktion utför till exempel SELECT en vänster yttre koppling på dessa två tabeller:
SELECT *
FROM table1 t1 LEFT OUTER JOIN table2 t2
ON t1.a = t2.c
ORDER BY t1.a;
GO
Här är resultatet.
a b c d
----------- ------ ----------- ------
NULL three NULL NULL
1 one NULL NULL
4 join4 4 four
(3 row(s) affected)
Resultatet gör det inte enkelt att skilja en NULL i data från en NULL som representerar ett misslyckande att ansluta. När NULL värden finns i data som ansluts är det vanligtvis bättre att utelämna dem från resultaten med hjälp av en vanlig koppling.