Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Gäller för:![]() SQL Server 2016 (13.x) och senare versioner
SQL Server 2016 (13.x) och senare versioner ![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() SQL-databas i Microsoft Fabric
SQL-databas i Microsoft Fabric
Med datavirtualisering kan du köra Transact-SQL frågor (T-SQL) över externa data utan att läsa in dem i databasen. PolyBase är databasmotorfunktionen som implementerar datavirtualisering i SQL Server och Azure SQL. Du definierar en extern datakälla, ett valfritt filformat och en extern tabell; därefter frågar du den externa tabellen med SELECT precis som vilken annan tabell som helst.
Den här guiden hjälper dig:
- Förstå vilka PolyBase-funktioner din SQL-plattform och version stöder.
- Välj mellan
OPENROWSET, externa tabeller ochBULK INSERTför att fråga eller mata in data. - Följ stegvisa länkar för vanliga scenarier.
- Granska prestanda, felsökning och metodtips för produktionsarbetsbelastningar.
Vanliga användningsfall
I följande tabell beskrivs möjliga användningsscenarier.
| Scenario | Använd |
|---|---|
| Ad-hoc utforskning av filer | OPENROWSET(BULK ...) |
| Återanvändbara filfrågor för BI/rapportering | Externa tabeller över filer |
| Frågor mellan databaser (SQL Server, Oracle, Teradata, MongoDB, ODBC) | PolyBase-anslutningar med externa tabeller |
| Exportera frågeresultat till filer |
CREATE EXTERNAL TABLE AS SELECT (CETAS) |
| Massinmatning i tabeller |
BULK INSERT eller OPENROWSET(BULK ...) med INSERT ... SELECT |
Vilka funktioner är tillgängliga var?
I följande tabell visas vilka grundläggande polybase- och datavirtualiseringsfunktioner som är tillgängliga på varje SQL-plattform. Använd den här tabellen för att avgöra vad du kan göra på din plattform innan du använder de detaljerade guiderna.
| Feature | SQL Server 2019 | SQL Server 2022 | SQL Server 2025 | Azure SQL Database | Hanterad instans i Azure SQL | SQL-databas i Microsoft Fabric |
|---|---|---|---|---|---|---|
| externa tabeller | Ja | Ja | Ja | Ja | Ja | Ja |
| OPENROWSET (BULK) | Ja 1 | Ja | Ja | Ja | Ja | Ja |
| CETAS (export) | No | Ja | Ja | No | Ja | No |
| CSV/avgränsade filer | Ja 2 | Ja | Ja | Ja | Ja | Ja |
| Parquet-filer | No | Ja | Ja | Ja | Ja | Ja |
| Delta Lake tabeller | No | Ja | Ja | No | No | No |
| Ansluta till en annan SQL Server | Ja | Ja | Ja | No | No | No |
| Ansluta till Azure SQL Database eller Azure SQL Managed Instance | Ja 3 | Ja 3 | Ja 3 | No | No | No |
| Ansluta till Oracle/Teradata/MongoDB | Ja | Ja | Ja | No | No | No |
| Ansluta till Azure Blob Storage | Ja | Ja | Ja | Ja | Ja | No |
| Ansluta till ADLS Gen2 | No | Ja | Ja | Ja | Ja | No |
| Ansluta till S3-kompatibel lagring | No | Ja | Ja | No | No | No |
| Ansluta till OneLake (Fabric) | No | No | No | No | No | Ja |
| Pushdown-beräkning | Ja | Ja | Ja | No | No | No |
| hanterad identitetsautentisering | No | No | Ja 4 | Ja | Ja | No |
1 SQL Server 2019 (15.x) stöder OPENROWSET(BULK...) lokala sökvägar och nätverksfilsökvägar. I SQL Server 2022 (16.x) och senare versioner stöder OPENROWSET(BULK...) även läsning från molnlagring med FORMAT = 'PARQUET', FORMAT = DELTAoch FORMAT = 'CSV'.
2 CSV-stöd i SQL Server 2019 (15.x) krävde Hadoop. I SQL Server 2022 (16.x) och senare versioner stöds CSV internt utan Hadoop.
3 Använder SQL Server-anslutningsappen (sqlserver://). Databasens begränsade autentiseringsuppgifter riktar sig mot Azure SQL-slutpunkten, samma steg som att ansluta till en annan SQL Server.
4 Managed Identity-autentisering stöds för anslutning till Azure Blob Storage (ABS) och ADLS Gen2. Det kräver Azure Arc-aktiverad SQL Server eller SQL Server på en virtuell Azure-dator för lokal SQL Server. Den är internt tillgänglig i Azure SQL Database och Azure SQL Managed Instance.
Anmärkning
Från och med SQL Server 2025 (17.x) är sökning i datafiler (CSV, Parquet och Delta) på Azure Blob Storage, ADLS Gen2 eller i S3-kompatibel lagring en inbyggd motorfunktion och kräver inte längre installation eller körning av PolyBase-tjänster. RDBMS-anslutningsappar (SQL Server, Oracle, Teradata, MongoDB, ODBC) kräver fortfarande att PolyBase-tjänster installeras och körs. SQL Server 2025 (17.x) lägger också till Linux-stöd för dessa anslutningsappar, som tidigare endast var tillgängliga i Windows.
Hämta data externt
Innan du väljer ett specifikt scenario bör du förstå de tre sätten att fråga externa data:
| Tillvägagångssätt | Syntax | Använd när | Authentication | PolyBase krävs |
|---|---|---|---|---|
| OLE DB-ad hoc-frågor | OPENROWSET(provider, connection, query) |
Du vill ha en snabb engångsfråga utan beständiga objekt eller behöver Microsoft Entra-ID-autentisering | SQL-autentisering, Windows-autentisering, Microsoft Entra ID (MSOLEDBSQL) | No |
| Skapa ad hoc-frågor | OPENROWSET(BULK ...) |
Du vill utforska fildata snabbt eller testa scheman innan du skapar en tabell | SAS-token, åtkomstnyckel, hanterad identitet, Microsoft Entra-ID | Ja för Azure SQL Database och Azure SQL Managed Instance Nej för SQL Server-instanser |
| Beständiga dataanslutningar |
CREATE EXTERNAL TABLE med sqlserver://, oracle://, teradata://, osv. |
Du behöver återkommande åtkomst, styrning och kontroll, statistik och pushdown-beräkning för produktion. | Endast SQL-autentisering | Ja |
PolyBase-tjänster krävs för molnfilåtkomst i SQL Server 2019 (15.x) och SQL Server 2022 (16.x). SQL Server 2025 (17.x) och senare versioner har inbyggt stöd för CSV, Parquet och Delta utan PolyBase.
Beslutsguide
| Scenario | Recommendation |
|---|---|
| Jag behöver Microsoft Entra-ID-autentisering för fjärr-SQL eller vill undvika PolyBase-tjänster | Använd OPENROWSET(MSOLEDBSQL, ...) (ad hoc, inga beständiga objekt) |
| Jag behöver beständiga tabeller, statistik eller pushdown-beräkningar för fjärrdatabaser | Använd CREATE EXTERNAL TABLE med PolyBase-anslutningsappar (sqlserver://, oracle://, teradata://, mongodb://, odbc://).
OPENROWSET stöder inte kontakter |
| Jag utforskar en ny fil eller testar ett schema | Använd OPENROWSET(BULK ...) (snabb iteration, inga beständiga objekt) |
| Jag matar in fildata i en tabell med transformeringar | Använd INSERT ... SELECT från OPENROWSET(BULK ...) |
| Jag behöver styrning eller delad åtkomst för många användare eller program | Använd CREATE EXTERNAL TABLE så att behörigheter och metadata centraliseras |
| Jag arbetar i SQL Database i Fabric | Använd OPENROWSET(BULK ...) för ad hoc OneLake-frågor eller externa tabeller för återanvändbar åtkomst. För extern lagring använder du OneLake-genvägar |
Välj ditt scenario
Nu när du förstår de tre metoderna använder du någon av följande guider för att implementera ditt specifika användningsfall.
Frågefiler (Parquet, CSV eller Delta)
Om dina data finns i Parquet-, CSV- eller Delta-filer på Azure Blob Storage, ADLS Gen2, S3-kompatibel lagring eller OneLake följer du någon av följande guider:
| Scenario | Rekommenderad vägledning | Plattformar |
|---|---|---|
| Snabb ad hoc-fråga i en Parquet- eller CSV-fil | Använd OPENROWSET. Ingen extern tabell behövs |
SQL Server 2022 (16.x) och senare versioner, Azure SQL Database, Azure SQL Managed Instance, SQL Database i Fabric |
| Upprepade frågor om Parquet-filer med ett beständigt schema | Skapa en extern tabell över Parquet | SQL Server 2022 (16.x) och senare versioner, Azure SQL Database, Azure SQL Managed Instance, SQL Database i Fabric |
| Fråga CSV-filer med en extern tabell | Skapa en extern tabell med ett filformat för avgränsad text | SQL Server 2019 (15.x) och senare versioner, Azure SQL Database, Azure SQL Managed Instance, SQL Database in Fabric |
| Fråga Delta Lake-tabeller | Skapa en extern tabell med FILE_FORMAT = DeltaLakeFileFormat |
SQL Server 2022 (16.x) och senare versioner |
| Exportera frågeresultat till Parquet- eller CSV-filer (CETAS) | Använd CREATE EXTERNAL TABLE AS SELECT |
SQL Server 2022 (16.x) och senare versioner, Azure SQL Managed Instance |
Du kan också följa någon av de här stegvisa självstudierna:
| Handledning | Beskrivning |
|---|---|
| Kom igång med PolyBase i SQL Server 2022 | Omfattar OPENROWSET med Parquet och CSV, externa tabeller och mappnavigering. |
| Virtualisera en Parquet-fil i ett objektlagringssystem kompatibelt med S3 med PolyBase | Självstudie för SQL Server 2022 (16.x) och senare versioner. |
| Virtualisera CSV-fil med PolyBase | Handledning för SQL Server 2022 (16.x) och senare versioner. |
| Virtualisera deltatabell med PolyBase | Självstudie för SQL Server 2022 (16.x) och senare versioner. |
| Datavirtualisering med Azure SQL Database (förhandsversion) | Azure SQL Database-guide för Parquet och CSV. |
| Datavirtualisering med Azure SQL Managed Instance | Azure SQL Managed Instance-guide för Parquet, CSV och CETAS. |
| Datavirtualisering i SQL-databas i Fabric | SQL-databas i Fabric-guide för OneLake-filer. |
Ansluta till en annan SQL Server-instans, Azure SQL Database eller SQL Managed Instance
I SQL Server 2019 (15.x) och senare versioner kan PolyBase köra frågor mot tabeller i en annan SQL Server-instans, Azure SQL Database eller Azure SQL Managed Instance, utan att använda länkade servrar.
Viktigt!
Anslutningsappen sqlserver:// stöds inte i SQL-databasen i Fabric. PolyBase RDBMS-anslutningsappar använder SQL-autentisering via CREATE DATABASE SCOPED CREDENTIAL och stöder inte Microsoft Entra ID, Managed Identity eller autentisering för tjänstens huvudanvändare. Eftersom SQL-databasen i Fabric kräver Microsoft Entra-autentisering kan du inte ansluta till den med hjälp av PolyBase.
| Steg | Vad du ska göra |
|---|---|
| 1. Installera PolyBase | Installera PolyBase i Windows eller installera PolyBase på Linux |
| 2. Skapa en autentiseringsuppgift |
CREATE DATABASE SCOPED CREDENTIAL med målinloggningen |
| 3. Skapa en extern datakälla | CREATE EXTERNAL DATA SOURCE ... WITH (LOCATION = 'sqlserver://<server>') |
| 4. Skapa en extern tabell | CREATE EXTERNAL TABLE ... WITH (LOCATION = '<db>.<schema>.<table>') |
| 5. Sökfråga | SELECT * FROM <external_table> |
Tips/Råd
SQL Server-anslutningsappen (sqlserver://) fungerar också för Azure SQL Database och Azure SQL Managed Instance. Använd samma steg och ange LOCATION till Azure SQL-slutpunkten (till exempel sqlserver://myserver.database.windows.net).
En detaljerad guide finns i Konfigurera PolyBase för åtkomst till externa data i SQL Server.
Ansluta till Oracle, Teradata eller MongoDB
SQL Server 2019 (15.x) och de senare versionerna kan göra frågor mot Oracle, Teradata, MongoDB och Cosmos DB via PolyBase ODBC-kontakter.
| Datakälla | Guide | Requirements |
|---|---|---|
| Oracle | Konfigurera PolyBase för åtkomst till externa data i Oracle | SQL Server 2019 (15.x) och senare versioner, Oracle-klientdrivrutiner |
| Teradata | Konfigurera PolyBase för åtkomst till externa data i Teradata | SQL Server 2019 (15.x) och senare versioner, Teradata ODBC-drivrutin |
| MongoDB/Cosmos DB | Konfigurera PolyBase för åtkomst till externa data i MongoDB | SQL Server 2019 (15.x) och senare versioner, MongoDB ODBC-drivrutin |
| Valfri ODBC-källa | Konfigurera PolyBase för åtkomst till externa data med allmänna ODBC-typer | SQL Server 2019 (15.x) och senare versioner (Windows) (Linux börjar med SQL Server 2025 (17.x)) |
Ansluta till Azure Blob Storage eller ADLS Gen2
| SQL-plattform | Autentiseringsalternativ | Guide |
|---|---|---|
| SQL Server 2022 (16.x) och senare versioner | SAS-token, åtkomstnyckel, hanterad identitet (från och med SQL Server 2025 (17.x)) | Konfigurera PolyBase för åtkomst till externa data i Azure Blob Storage |
| SQL Server 2019 (15.x) | Åtkomstnyckel (via Hadoop-anslutningsprogram) | Konfigurera PolyBase för åtkomst till externa data i Azure Blob Storage |
| Azure SQL Database | SAS-token, hanterad identitet, Microsoft Entra vidarebefordran | Datavirtualisering med Azure SQL Database (förhandsversion) |
| Hanterad instans i Azure SQL | SAS-token, hanterad identitet | Datavirtualisering med Azure SQL Managed Instance |
I SQL Server 2022 (16.x) ändrades URI-prefixen. När du migrerar från SQL Server 2019 (15.x) eller tidigare versioner:
-
Azure Blob Storage: Ändra
wasb[s]://tillabs:// -
ADLS Gen2: Ändra
abfs[s]://tilladls://
Mer information finns i Konfigurera PolyBase för åtkomst till externa data i Azure Blob Storage.
Ansluta till S3-kompatibel objektlagring
SQL Server 2022 (16.x) och senare versioner stöder S3-kompatibel lagring, till exempel Amazon S3, MinIO och Ceph.
Mer information finns i Konfigurera PolyBase för åtkomst till externa data i S3-kompatibel objektlagring.
Exportera data med CREATE EXTERNAL TABLE AS SELECT (CETAS)
CETAS exporterar frågeresultat till externa filer (Parquet eller CSV) i Azure Blob Storage, ADLS Gen2 eller S3-kompatibel lagring.
| SQL-plattform | Supported | Exportformat | Notes |
|---|---|---|---|
| SQL Server 2022 (16.x) och senare versioner | Ja | Parquet, CSV | Kräver serverkonfiguration: tillåt polybase-export |
| Hanterad instans i Azure SQL | Ja | Parquet, CSV | Inaktiverad som standard |
| Azure SQL Database | No | Ingen | Ej tillgänglig |
| SQL-databas i Fabric | No | Ingen | Ej tillgänglig |
För Transact-SQL-referensen, se SKAPA EXTERN TABELL SOM SELECT (CETAS).
Snabbstartsexempel
Exempel 1: Ad hoc-fråga på en Parquet-fil (OPENROWSET)
Ingen extern tabell behövs. Fungerar på SQL Server 2022 (16.x) och senare versioner, Azure SQL Database, Azure SQL Managed Instance och SQL Database i Fabric.
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet',
FORMAT = 'PARQUET'
) AS [result];
Exempel 2: Extern tabell över CSV i Azure Blob Storage
Det här exemplet fungerar på alla SQL-plattformar som stöder PolyBase.
Steg 1: Skapa en databashuvudnyckel (DMK). Det här steget krävs eftersom autentiseringsuppgifterna lagrar en SAS-tokenhemlighet. Du kan dock det här steget om du använder Hanterad identitet eller Microsoft Entra-autentisering.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<strong_password>';Steg 2: Skapa en autentiseringsuppgift med en SAS-token. Utelämna inledande
?.CREATE DATABASE SCOPED CREDENTIAL MyStorageCred WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = '<your_SAS_token>'; -- omit the leading '?'Steg 3: Skapa en extern datakälla.
CREATE EXTERNAL DATA SOURCE MyAzureStorage WITH ( LOCATION = 'abs://mycontainer@mystorageaccount.blob.core.windows.net', CREDENTIAL = MyStorageCred );Steg 4: Skapa ett filformat för CSV:en.
CREATE EXTERNAL FILE FORMAT CsvFormat WITH ( FORMAT_TYPE = DELIMITEDTEXT, FORMAT_OPTIONS ( FIELD_TERMINATOR = ',', STRING_DELIMITER = '"', FIRST_ROW = 2 ) );Steg 5: Skapa den externa tabellen.
CREATE EXTERNAL TABLE dbo.SalesExternal ( OrderId INT, OrderDate DATE, Amount DECIMAL (18, 2), Customer NVARCHAR (100) ) WITH ( DATA_SOURCE = MyAzureStorage, LOCATION = '/data/sales/', FILE_FORMAT = CsvFormat );Steg 6: Fråga den externa tabellen.
SELECT * FROM dbo.SalesExternal WHERE OrderDate >= '2025-01-01';
Exempel 3: Fråga en tabell i en annan SQL Server
Det här exemplet fungerar på SQL Server 2019 (15.x) och senare versioner.
Steg 1: Skapa en huvudnyckel för databasen (krävs eftersom autentiseringsuppgifterna lagrar ett lösenord).
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<strong_password>';Steg 2: Skapa en autentiseringsuppgift för sql server-fjärrinstansen.
CREATE DATABASE SCOPED CREDENTIAL RemoteSqlCred WITH IDENTITY = 'remote_user', SECRET = '<password>';Steg 3: Skapa den externa datakällan.
CREATE EXTERNAL DATA SOURCE RemoteSqlServer WITH ( LOCATION = 'sqlserver://remote-server.contoso.com', PUSHDOWN = ON, CREDENTIAL = RemoteSqlCred );Steg 4: Skapa den externa tabellen (tredelade namn i
LOCATION).CREATE EXTERNAL TABLE dbo.RemoteCustomers ( CustomerId INT, CustomerName NVARCHAR (200) COLLATE SQL_Latin1_General_CP1_CI_AS ) WITH ( DATA_SOURCE = RemoteSqlServer, LOCATION = 'SalesDB.dbo.Customers' );Steg 5: Fråga mellan servrar.
SELECT c.CustomerName, s.Amount FROM dbo.RemoteCustomers AS c INNER JOIN dbo.LocalSales AS s ON c.CustomerId = s.CustomerId;
Exempel 4: Exportera resultat till Parquet med CETAS
Fungerar på SQL Server 2022 (16.x) och senare versioner, Azure SQL Managed Instance.
Steg 1: Aktivera CETAS (endast SQL Server).
EXECUTE sp_configure 'allow polybase export', 1; RECONFIGURE;Steg 2: Skapa autentiseringsuppgifter och datakälla (återanvänd från tidigare exempel).
Steg 3: Skapa ett filformat för Parquet-export.
CREATE EXTERNAL FILE FORMAT ParquetFormat WITH ( FORMAT_TYPE = PARQUET );Steg 4: Exportera frågeresultat.
CREATE EXTERNAL TABLE dbo.Sales2025Export WITH ( DATA_SOURCE = MyAzureStorage, LOCATION = '/exports/sales_2025.parquet', FILE_FORMAT = ParquetFormat ) AS SELECT * FROM Sales.Orders WHERE OrderDate >= '2025-01-01';
T-SQL-byggblock för PolyBase
Innan du implementerar ett scenario bör du förstå de centrala T-SQL-objekt som PolyBase använder och hur de passar ihop:
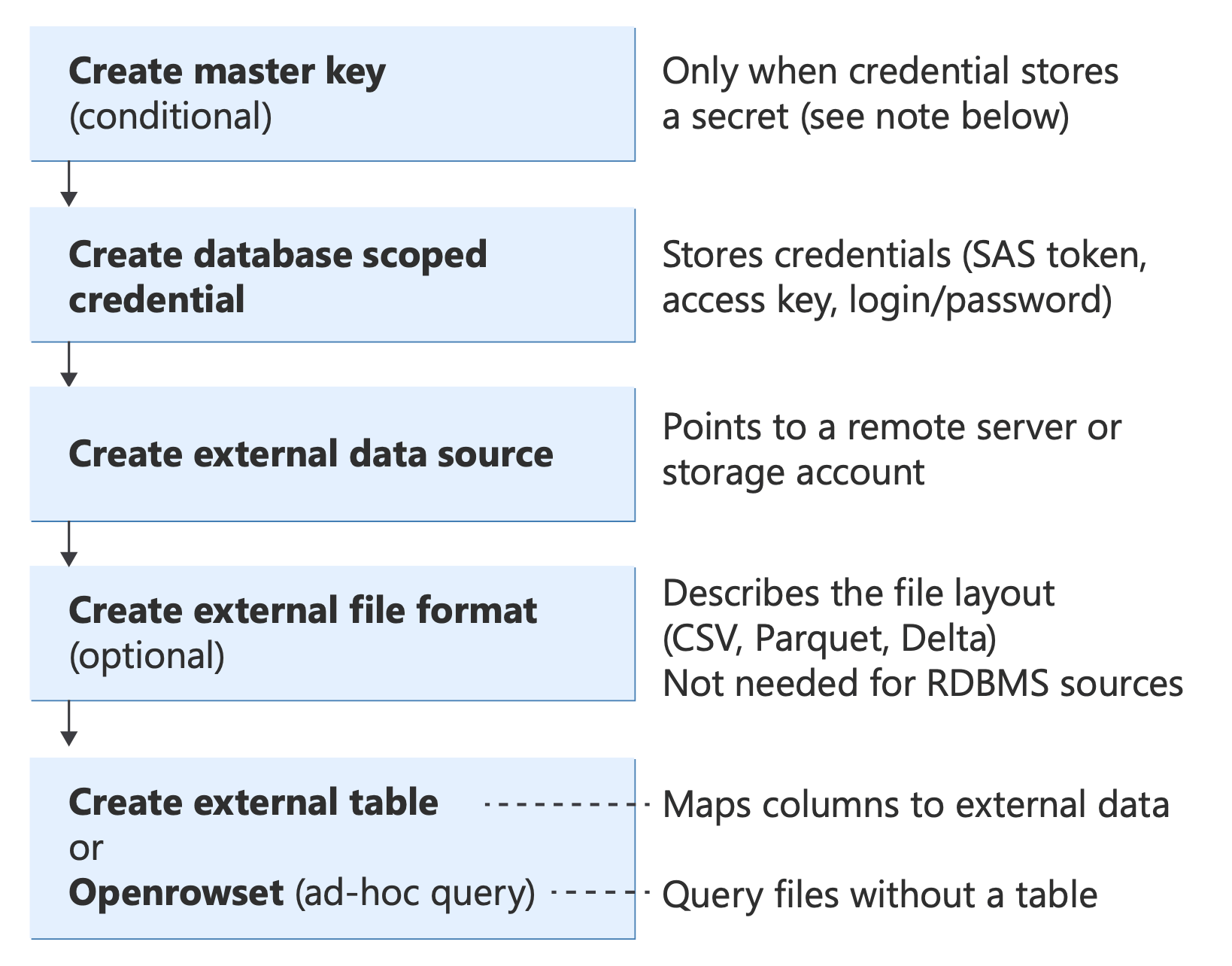
Diagram som visar PolyBase T-SQL-objekt och deras relationer, från autentisering (databashuvudnyckel, autentiseringsuppgifter) via datakällor och filformat till frågemetoder (extern tabell, OPENROWSET, BULK INSERT, CETAS).
Information om dessa T-SQL-instruktioner finns i:
- SKAPA EN EXTERN DATAKÄLLA
- CREATE EXTERNAL FILE FORMAT (Skapa ett externt filformat)
- SKAPA EXTERNTABELL
- OPENROWSET
- SKAPA EXTERN TABELL MED SELECT (CETAS)
En fullständig Transact-SQL referens för alla objekt finns i PolyBase Transact-SQL referens.
Viktigt!
Kontrollera datatypens mappning för ditt externa filformat. När du skapar ett externt filformat eller frågefiler med , OPENROWSETmappar PolyBase automatiskt källdatatyper (Parquet, CSV, Delta, Oracle, Teradata, MongoDB) till SQL Server-datatyper. Icke-matchande typer kan leda till osynlig trunkering, precisionsförlust eller frågefel. Till exempel mappar en Parquet DECIMAL(38,18) till DECIMAL(18,0). Granska mappningstabellerna innan du definierar externa tabellkolumner eller en WITH sats. Fullständig referens finns i Typmappning med PolyBase.
När krävs CREATE MASTER KEY?
En databashuvudnyckel (DMK) skapas med hjälp av CREATE MASTER KEY syntax. DMK krypterar hemligheterna som lagras i databasomfångsbegränsade autentiseringsuppgifter. Det krävs bara när autentiseringsuppgifterna innehåller ett hemligt värde, det vill ex när det lagrar ett lösenord, en token eller en åtkomstnyckel.
DMK krävs (autentiseringsuppgifter lagrar en hemlighet):
Autentiseringstyp IDENTITYvärdeHar hemlighet DMK SAS-token 'SHARED ACCESS SIGNATURE'Ja Obligatoriskt S3-åtkomstnyckel 'S3 ACCESS KEY'Ja Obligatoriskt SQL-inloggning/grundläggande autentisering '<username>'Ja Obligatoriskt Åtkomstnyckel för lagringskonto '<storage_account_name>'Ja Obligatoriskt DMK krävs inte (ingen hemlighet lagras):
Autentiseringstyp IDENTITYvärdeHar hemlighet DMK Hanterad identitet 'Managed Identity'No Krävs inte Microsoft Entra ID 'User Identity'eller'Managed Identity'No Krävs inte
Tips/Råd
Om det inte finns någon hemlighet i ditt CREATE DATABASE SCOPED CREDENTIAL uttryck, behöver du ingen DMK. Hanterad identitet och Microsoft Entra ID-autentisering delegerar förtroende till plattformen. Databasen lagrar inte lösenord eller token.
Exempel:
I den här exempelfrågan krävs DMK (Autentiseringsuppgifter lagrar en SAS-token).
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<strong_password>';
CREATE DATABASE SCOPED CREDENTIAL SasCred
WITH IDENTITY = 'SHARED ACCESS SIGNATURE',
SECRET = '<your_SAS_token>';
I den här exempelfrågan krävs inte DMK (hanterad identitet, ingen hemlighet).
CREATE DATABASE SCOPED CREDENTIAL ManagedIdentityCred
WITH IDENTITY = 'Managed Identity';
I den här exempelfrågan krävs inte DMK (pass-through via Microsoft Entra, ingen hemlig nyckel).
CREATE DATABASE SCOPED CREDENTIAL EntraIdCred
WITH IDENTITY = 'User Identity';
Fjärrdataåtkomst med OPENROWSET och externa tabeller
SQL Server erbjuder tre olika metoder för att fråga fjärrdata. Du kan välja rätt metod när du förstår skillnaderna i syntax, autentisering och arkitektur.
| Tillvägagångssätt | Syntax | Ansluter till | Authentication | PolyBase-tjänster | Plattformar |
|---|---|---|---|---|---|
| OLE DB-frågor | OPENROWSET(provider, connection, query) |
Alla OLE DB-källor via MSOLEDBSQL, SQLOLEDB eller andra leverantörer | SQL-autentisering, Windows-autentisering, Microsoft Entra ID (MSOLEDBSQL) | No | SQL Server (alla versioner som stöds) |
| Filfrågor | OPENROWSET(BULK ...) |
Filer på lokal disk, nätverk eller moln (Azure Blob, ADLS, S3, OneLake) | SAS-token, åtkomstnyckel, hanterad identitet, Microsoft Entra-ID | Ja för molnet*; Nej för lokal | SQL Server 2005; SQL Server 2022 (16.x) och senare versioner (moln); Azure SQL |
| PolyBase-anslutningsappar |
CREATE EXTERNAL TABLE med CREATE EXTERNAL DATA SOURCE hjälp av sqlserver://, oracle://, teradata://, mongodb://, odbc:// |
Fjärr-SQL Server, Oracle, Teradata, MongoDB, ODBC-källor | Endast SQL-autentisering | Ja | SQL Server 2019 (15.x) och senare versioner (Windows); SQL Server 2025 (17.x) och senare versioner (Linux) |
PolyBase-tjänster krävs för molnfilåtkomst i SQL Server 2019 (15.x) och SQL Server 2022 (16.x). SQL Server 2025 (17.x) och senare versioner har inbyggt molnfilstöd och kräver inte längre PolyBase för CSV, Parquet eller Delta.
När du ska använda varje metod
Använd OLE DB OPENROWSET för:
- Snabba ad hoc-frågor en gång utan att skapa beständiga objekt
- Microsoft Entra-ID eller hanterad identitetsautentisering (via MSOLEDBSQL)
- Undvika PolyBase-tjänstberoenden
- Ansluta till en datakälla med en OLE DB-provider
Använd File OPENROWSET(BULK) för:
- Ad hoc-filutforskning och schemaidentifiering
- Snabbtransformeringar och förhandsversioner innan du förbinder dig till en tabelldefinition
- Flexibla kolumntransformeringar infogade (gjutning, filtrering, beräknade kolumner)
- Data som inte ändras ofta och som inte behöver beständiga metadata
Använd PolyBase-anslutningar med kommandot CREATE EXTERNAL TABLE för:
- Beständiga, återanvändbara tabelldefinitioner som används av flera användare eller program
- Produktionsarbetsbelastningar som kräver statistik och frågeplansoptimering
- Pushdown-beräkning till fjärrkällor (filter som skickas till Oracle, SQL Server osv.)
- Delad styrning och säkerhet (när de har skapats behöver
SELECTanvändarna bara behörighet) - När du har SQL-autentisering tillgänglig för fjärrkällan
OPENROWSET (OLE DB) – ad hoc-fjärrfrågor (inga PolyBase-tjänster krävs)
OLE DB-formen OPENROWSET ansluter till en fjärrdatakälla via en OLE DB-provider, kör en direktfråga och returnerar resultatet som en raduppsättning. Det är ett engångs ad hoc-alternativ till en länkad server. Inga beständiga metadata skapas. Den här syntaxen kräver inte PolyBase-tjänster och stöder inte molnfiler eller externa datakällor.
Den här exempelfrågan ansluter till en fjärr-SQL Server via OLE DB (inte PolyBase).
SELECT *
FROM OPENROWSET (
'MSOLEDBSQL',
'Server=remote-server;Database=AdventureWorks;Trusted_Connection=yes;',
'SELECT TOP 10 * FROM AdventureWorks.Sales.SalesOrderHeader'
);
OPENROWSET(BULK) – filbaserade frågor (PolyBase)
Formen BULK av OPENROWSET läser data direkt från filer. På SQL Server 2019 (15.x) och tidigare versioner läser den från lokala sökvägar eller UNC-filsökvägar och kräver en formatfil. I SQL Server 2022 (16.x) och senare versioner kan du läsa från molnlagring med parametrarna DATA_SOURCE och FORMAT . Den här metoden är den PolyBase-integrerade version som används för datavirtualisering.
I samband med PolyBase och datavirtualisering, när den här guiden refererar till OPENROWSET syftar det på syntaxen OPENROWSET(BULK ...) med en FORMAT sats för att söka igenom externa filer.
Exempel:
Den här exempelfrågan läser en Parquet-fil från Azure Blob Storage (SQL Server 2022 och senare versioner).
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'data/sales/*.parquet',
DATA_SOURCE = 'MyAzureStorage',
FORMAT = 'PARQUET'
) AS [result];
Den här exempelfrågan läser en Parquet-fil med en infogad sökväg (Azure SQL Database, Azure SQL Managed Instance).
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet',
FORMAT = 'PARQUET'
) AS [result];
När du ska använda OPENROWSET jämfört med externa tabeller
Med både OPENROWSET(BULK ...) och externa tabeller kan du köra frågor mot externa data med T-SQL, men de är utformade för olika användningsfall. I följande tabell sammanfattas de viktigaste skillnaderna som hjälper dig att avgöra vilken metod som passar ditt scenario.
| Förmåga | OPENROWSET(BULK ...) |
Extern tabellen |
|---|---|---|
| Purpose | Ad hoc-utforskning och engångsfrågor | Beständiga, återanvändbara tabelldefinitioner |
| Metadata som lagras i databasen | Nej. Ingenting sparas efter att sökfrågan har körts | Ja. Tabelldefinitionen, datakällan och filformatet lagras som databasobjekt |
| Schemadefinition | Härleds automatiskt från filen (Parquet) eller anges infogat med en WITH klause |
Uppges uttryckligen i CREATE EXTERNAL TABLE anvisningen |
| Behörigheter | Kräver ADMINISTER BULK OPERATIONS eller ADMINISTER DATABASE BULK OPERATIONS |
När den har skapats räcker det med standardbehörighet SELECT i tabellen |
| Beräknade kolumner | Ja. Lägg till uttryck och beräknade kolumner i SELECT listan; metadatafunktioner som filename() och filepath() är endast tillgängliga här. |
Nej. Fast kolumnlista; utföra transformeringar i en vy eller i frågan som läser den externa tabellen |
| Statistik | Azure SQL: manuell statistik med en kolumn via sys.sp_create_openrowset_statistics; SQL Server 2022 (16.x) och senare versioner: skapa statistik automatiskt på predikat (ingen manuell statistik på SQL Server). Se manuell statistik för OPENROWSET. |
Fullständigt CREATE STATISTICS stöd på alla plattformar, plus autogenerering i SQL Server 2022 (16.x) och senare versioner. Se Skapa manuell statistik för extern tabell. |
| Pushdown | Begränsat stöd. Motorn kan trycka ned filter till filsökningen, men det finns ingen tryck ned till fjärranslutna RDBMS-källor. | Ja. Stödjer pushdownberäkning för kopplingar till RDBMS som SQL Server, Oracle, Teradata och MongoDB. |
| Bäst för | Datautforskning, schemaidentifiering, prototypfrågor, engångsdatainläsningar, flexibla omvandlingar | Produktionsarbetsbelastningar, upprepade frågor, delad åtkomst mellan användare, instrumentpaneler och rapportering |
Använd OPENROWSET när du behöver flexibilitet
Använd OPENROWSET för att utforska en fil, testa olika scheman eller lägga till beräknade kolumner och transformeringar utan att skapa några beständiga objekt. Du kan till exempel extrahera filsökvägen som en kolumn, omvandla datatyper direkt eller filtrera enligt beräknade uttryck i en och samma fråga.
Den här exempelfrågan innehåller beräknade kolumner och transformeringar:
SELECT result.filename() AS [FileName],
result.filepath(1) AS [Year],
result.filepath(2) AS [Month],
CAST (OrderDate AS DATE) AS OrderDate,
Amount,
OrderDate
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*/*/*/*.parquet',
FORMAT = 'PARQUET'
) AS result
WHERE result.filepath(1) = '2025';
Tips/Råd
Funktionerna filepath() och filename() är tillgängliga i Azure SQL Database, Azure SQL Managed Instance och SQL Server 2022 (16.x) och senare versioner. De låter dig filtrera på delar av filsökvägen (partitionseliminering) och exponera källfilnamnet som en kolumn, vilket inte är direkt möjligt med externa tabeller.
Använda externa tabeller när du behöver beständighet och styrning
Använd externa tabeller när flera användare eller program måste köra frågor mot samma externa data upprepade gånger. Du definierar schemat, datakällan och autentiseringsuppgifterna en gång och lagrar dem i databasen. Konsumenter behöver SELECT bara behörighet i tabellen.
Externa tabeller stödjer också statistik, som frågeoptimeraren använder för att skapa bättre exekveringsplaner. Du kan skapa statistik manuellt eller låta motorn skapa dem automatiskt (SQL Server 2022 (16.x) och senare versioner).
Den här exempelfrågan skapar statistik i en extern tabell för bättre frågeplaner.
CREATE STATISTICS Stats_OrderDate
ON dbo.SalesExternal(OrderDate)
WITH FULLSCAN;
Mer information om statistik för båda metoderna finns i Prestandaöverväganden för PolyBase – Statistik.
BULK INSERT jämfört med OPENROWSET(BULK): Vilken ska jag använda?
Både BULK INSERT och OPENROWSET(BULK ...) importera data från filer till SQL Server med hjälp av samma underliggande massinläsningsmotor. De skiljer sig dock åt i syntax, flexibilitet och vad du kan göra med resultaten. I följande tabell sammanfattas de viktigaste skillnaderna:
Anmärkning
BULK INSERT är inte tillgängligt i SQL-databasen i Fabric. För Fabric använder du OPENROWSET(BULK ...) med OneLake.
| Förmåga | BULK INSERT |
OPENROWSET(BULK ...) |
|---|---|---|
| Grundläggande syfte | Läser in data från en fil direkt till en måltabell | Returnerar en raduppsättning som du använder i en SELECT- eller INSERT ... SELECT-instruktion |
| Användningsmönster | Fristående instruktion: BULK INSERT <table> FROM '<file>' |
Måste användas i en fråga: SELECT * FROM OPENROWSET(BULK ...) eller INSERT INTO <table> SELECT * FROM OPENROWSET(BULK ...) |
| Kräver en måltabell? | Ja. Skriv alltid direkt till en tabell | Nej. Du kan SELECT från detta utan att infoga den någonstans, eller infoga den i en valfri tabell eller temporär tabell |
| Kolumntransformeringar under inläsning | Begränsat stöd. Data flödar från fil till tabell as-is (mappning styrs av formatfil eller kolumnordning) | Fullständigt stöd. Du kan lägga till uttryck, CAST, WHERE filter, JOIN andra tabeller och beräknade kolumner i de omgivande SELECT |
| Tabellhintar | Satsen WITH innehåller stöd för BATCHSIZE, CHECK_CONSTRAINTS, FIRE_TRIGGERS, KEEPIDENTITY, KEEPNULLS, TABLOCKoch mycket mer |
Stödjer tabelltips via syntaxen INSERT ... SELECT * FROM OPENROWSET(BULK ...) WITH (TABLOCK, IGNORE_CONSTRAINTS, ...) |
| Import av stora objekt (LOB) med ett värde | Stöds ej | Ja. Stöder SINGLE_BLOB, SINGLE_CLOB, SINGLE_NCLOB för att importera en hel fil som ett varbinary(max), varchar(max)eller nvarchar(max) värde |
| Formatera filer | Ja. Stöds via (XML och icke-XML) | Ja. Stöds (XML och icke-XML) |
| Åtkomst till molnfiler (Azure Blob Storage, ADLS Gen2, S3) | Ja. Stöds via DATA_SOURCE parameter (SQL Server 2017 (14.x) och senare versioner, Azure SQL) |
Ja. Stöds via DATA_SOURCE parameter eller infogad URL med FORMAT -sats (SQL Server 2022 (16.x) och senare versioner, Azure SQL) |
| Parquet- eller Delta-filer | Stöds inte. Endast CSV/avgränsad text | Ja. Stöds med FORMAT = 'PARQUET' eller FORMAT = 'DELTA' (SQL Server 2022 (16.x) och senare versioner, Azure SQL) |
| Behörighet krävs |
ADMINISTER BULK OPERATIONS eller ADMINISTER DATABASE BULK OPERATIONS, plus INSERT i måltabellen |
ADMINISTER BULK OPERATIONS eller ADMINISTER DATABASE BULK OPERATIONS |
| Minimal loggning | Ja. Stöds under enkla eller massloggade återställningsmodeller med TABLOCK |
Ja. Stöds när det används med INSERT ... SELECT och TABLOCK |
När du ska välja MASSINFOGNING
Använd BULK INSERT när du har en enkel fil-till-tabell-inläsning och inte behöver transformera, filtrera eller koppla data under importen. Den använder enklare syntax för CSV eller andra avgränsade filer:
Den här exempelfrågan läser in en CSV-fil från Azure Blob Storage direkt till en tabell.
BULK INSERT Sales.Invoices
FROM 'invoices/inv-2025-01.csv'
WITH (
DATA_SOURCE = 'MyAzureBlobStorage',
FORMAT = 'CSV',
FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR = '\n'
);
Den här exempelfrågan läser in en lokal fil med en formatfil för kolumnmappning.
BULK INSERT dbo.Products
FROM 'C:\Data\products.csv'
WITH (
FORMATFILE = 'C:\Data\products.fmt',
FIRSTROW = 2,
TABLOCK
);
När du bör välja OPENROWSET(BULK)
Använd OPENROWSET(BULK ...) när du behöver ett eller flera av följande villkor:
- Fråga efter eller förhandsgranska fildata utan att skapa en tabell först.
- Transformera, filtrera eller koppla data under importen.
-
Läs in Parquet- eller Delta-filer (stöder endast
OPENROWSETdessa format). -
Importera en hel fil som ett enda LOB-värde (
SINGLE_BLOB,SINGLE_CLOB,SINGLE_NCLOB).
Den här exempelfrågan förhandsgranskar en CSV-fil från Azure Blob Storage utan att infoga data någonstans.
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'invoices/inv-2025-01.csv',
DATA_SOURCE = 'MyAzureBlobStorage',
FORMAT = 'CSV',
FIRSTROW = 2,
FIELDTERMINATOR = ','
) AS src;
Den här exempelfrågan infogar data med transformering och filtrering.
INSERT INTO Sales.Invoices (InvoiceDate, Amount, Customer)
SELECT CAST (InvoiceDate AS DATE),
Amount * 1.1, -- Apply a 10% markup
UPPER(Customer)
FROM OPENROWSET (
BULK 'invoices/inv-2025-01.csv',
DATA_SOURCE = 'MyAzureBlobStorage',
FORMAT = 'CSV',
FIRSTROW = 2
) WITH (
InvoiceDate VARCHAR (10),
Amount DECIMAL (18, 2),
Customer VARCHAR (100)
) AS src
WHERE Amount IS NOT NULL;
Den här exempelfrågan läser in en Parquet-fil (inte möjligt med BULK INSERT).
INSERT INTO Sales.Invoices
SELECT *
FROM OPENROWSET (
BULK 'data/invoices/*.parquet',
DATA_SOURCE = 'MyAzureStorage',
FORMAT = 'PARQUET') AS src;
Den här exempelfrågan importerar en hel XML-fil som ett enda varbinary-värde (max ).
INSERT INTO dbo.XmlDocuments (DocContent)
SELECT BulkColumn
FROM OPENROWSET (
BULK 'C:\Data\catalog.xml',
SINGLE_BLOB
) AS x;
Tips/Råd
En metod är att börja med OPENROWSET(BULK ...) i en SELECT för att utforska och validera fildata och sedan växla till BULK INSERT för den slutliga produktionsbelastningen om du inte behöver transformeringar. Om du behöver stöd för Parquet eller Delta eller inbyggd filtrering kan du hålla dig till OPENROWSET.
Mer information finns i följande relaterade guider:
- Använd BULK INSERT eller OPENROWSET(BULK...) för att importera data till SQL Server: En detaljerad guide sida vid sida med säkerhetsöverväganden.
-
Massimport och export av data (SQL Server): En översikt över alla massdataförflyttningsmetoder (bcp,
BULK INSERT,OPENROWSET). - BULK INSERT (Transact-SQL): En fullständig T-SQL-referens.
- OPENROWSET BULK (Transact-SQL): En fullständig T-SQL-referens.
- Exempel på massåtkomst till data i Azure Blob Storage: Exempel sida vid sida med båda metoderna med Azure Storage.
-
Massimportera stora objektdata med OPENROWSET Bulk Rowset Provider (SQL Server):
SINGLE_BLOB,SINGLE_CLOBochSINGLE_NCLOBexempel. - Använd en formatfil för att massimportera data (SQL Server): Formatera filanvändning med båda metoderna.
Användbara metadatafunktioner
När du kör frågor mot externa filer med OPENROWSET eller externa tabeller kan du använda flera inbyggda funktioner och procedurer för att granska filmetadata, identifiera scheman och implementera partitionsmedvetna frågor.
filepath() och filename()
Funktionerna filepath() och filename() returnerar delar av filsökvägen eller filnamnet för varje rad i resultatuppsättningen. De är särskilt användbara för:
Partitionseliminering: Filtrera på mappsegment (till exempel år/månad/dag-partitioner) så att motorn endast läser de matchande filerna i stället för att skanna allt.
Exponera källmetadata: Inkludera det ursprungliga filnamnet eller sökvägen som en kolumn i frågeresultatet, vilket är användbart för granskning eller felsökning.
| Function | Retur | Exempel |
|---|---|---|
filename() |
Filnamnet (inklusive tillägget) för källfilen för varje rad | sales_2025_01.parquet |
filepath(N) |
Det N:e mappsegmentet efter jokertecknet (*) i BULK sökvägen, där N börjar på 1 |
För sökvägen sales/2025/01/*.parquet returnerar filepath(1)2025, filepath(2) returnerar 01 |
Gäller för: Azure SQL Database, Azure SQL Managed Instance, SQL Server 2022 (16.x) och senare versioner, SQL Database in Fabric.
Den här exempelfrågan använder filepath() för partitionseliminering och filename() för att identifiera källfiler. Den läser bara filer under /2025/ mappen och läser bara filer under undermappen /06/ .
SELECT result.filename() AS SourceFile,
result.filepath(1) AS [Year],
result.filepath(2) AS [Month],
*
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*/*/*.parquet',
FORMAT = 'PARQUET'
) AS result
WHERE result.filepath(1) = '2025'
AND result.filepath(2) = '06';
Tips/Råd
Placera WHERE -satsen kan motorn utföra partitionseliminering på filgenomsökningsnivå, vilket avsevärt minskar I/O.
sp_describe_first_result_set – identifiera OPENROWSET-kolumntyper
När du använder OPENROWSET med Parquet-filer härleder motorn kolumndatatyper automatiskt (schemainferens). De härledda typerna kan vara större än nödvändigt. Teckenkolumner härleds till exempel ofta som varchar(8000) eftersom Parquet-metadata inte innehåller någon maximal längd. Det här valet kan försämra prestanda och förbruka mer minne.
Använd sp_describe_first_result_set för att inspektera det härledda schemat innan du slutför frågan. När du ser de härledda typerna anger du smalare typer i en WITH sats för att förbättra prestandan.
Steg 1: Granska det här schemat.
EXECUTE sp_describe_first_result_set N' SELECT * FROM OPENROWSET( BULK ''abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet'', FORMAT = ''PARQUET'' ) AS result';Utdata visar varje kolumns namn, härledd datatyp, maximal längd, precision och skala. Om du ser varchar(8000) där ett varchar(100) skulle räcka åsidosätter du det:
Steg 2: Använd explicita typer för bättre prestanda.
SELECT TOP 100 * FROM OPENROWSET ( BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet', FORMAT = 'PARQUET' ) WITH ( OrderId INT, OrderDate DATE, Amount DECIMAL (18, 2), Customer VARCHAR (100) -- much narrower than the inferred varchar(8000) ) AS result;
Schemainferens fungerar bara med Parquet-filer. För CSV-filer anger du alltid kolumndefinitioner antingen i en WITH sats (för OPENROWSET) eller i -instruktionen CREATE EXTERNAL TABLE .
sp_describe_first_result_set är en allmän SQL Server- och Azure SQL-procedur, men den är särskilt användbar för OPENROWSET frågor. För mer information, se sp_describe_first_result_set.
Prestanda, felsökning och metodtips
När du har implementerat datavirtualisering använder du dessa guider för att optimera prestanda, diagnostisera problem och säkerställa produktionsberedskap:
| Område | Artikel | Detaljer |
|---|---|---|
| PolyBase-prestanda | prestandaöverväganden i PolyBase för SQL Server | Statistik, pushdown, parallellism och minneshantering |
| Pushdown-beräkning | Pushdown-beräkningar i PolyBase | Anger vilka åtgärder som skickas till fjärrkällan |
| Så här ser du om pushdown har inträffat | Så här ser du om extern pushdown har inträffat | Frågeplaner och DMV:er |
| Felsökning | Övervaka och felsöka PolyBase | Vanliga fel och lösningar |
| Kerberos-anslutning | Felsöka PolyBase Kerberos-anslutning | |
| Vanliga frågor och svar | Vanliga frågor och svar om PolyBase | |
| Fel och lösningar | PolyBase-fel och möjliga lösningar |