Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
gäller för:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Med fulltextsökning i SQL Server and Azure SQL Database kan användare och program köra fulltextfrågor mot teckenbaserade data i SQL Server-tabeller.
Viktigt!
Det finns brytande förändringar i Full-Text Search i SQL Server 2025 (17.x) och senare versioner. För mer information, se Viktiga ändringar av databasmotorfunktioner i SQL Server 2025.
Grundläggande uppgifter
Den här artikeln innehåller en översikt över Full-Text Search och beskriver dess komponenter och arkitektur. Om du föredrar att komma igång direkt, här är de grundläggande uppgifterna.
- Kom igång med Full-Text Search
- Skapa och hantera Full-Text kataloger
- Skapa och hantera fulltextindex
- Fyll i Full-Text index
- fråga med Full-Text Sök
Full-Text Search är en valfri komponent i SQL Server Database Engine. Om du inte valde Full-Text Sök när du installerade SQL Server kör du SQL Server-installationen igen för att lägga till den.
Översikt
Ett fulltextindex innehåller en eller flera teckenbaserade kolumner i en tabell. Dessa kolumner kan ha någon av följande datatyper: char, varchar, nchar, nvarchar, text, ntext, image, xml eller varbinary(max) och FILESTREAM. Varje fulltextindex indexerar en eller flera kolumner från tabellen, och varje kolumn kan använda ett visst språk.
Fulltextfrågor utför språkliga sökningar mot textdata i fulltextindex genom att arbeta med ord och fraser baserat på reglerna för ett visst språk, till exempel engelska eller japanska. Fulltextfrågor kan innehålla enkla ord och fraser eller flera former av ett ord eller en fras. En fulltextfråga returnerar alla dokument som innehåller minst en matchning (kallas även träff). En matchning inträffar när ett måldokument innehåller alla termer som anges i fulltextfrågan och uppfyller andra sökvillkor, till exempel avståndet mellan matchande termer.
Full-Text Sökfrågor
När kolumner har lagts till i ett fulltextindex kan användare och program köra fulltextfrågor på texten i kolumnerna. Dessa frågor kan söka efter något av följande villkor:
- Ett eller flera specifika ord eller fraser (enkel term)
- Ett ord eller en fras där orden börjar med angiven text (prefixterm)
- Böjningsformer av det specifika ordet (generation term)
- Ett ord eller en fras nära ett annat ord eller en annan fras (närhetsterm)
- Synonyma former av ett specifikt ord (synonymordlistan)
- Ord eller fraser med viktade värden (viktad term)
Fulltextfrågor är inte skiftlägeskänsliga. Om du till exempel söker Aluminum efter eller aluminum returnerar samma resultat.
Fulltextfrågor använder en liten uppsättning Transact-SQL predikat (CONTAINS och FREETEXT) och funktioner (CONTAINSTABLE och FREETEXTTABLE). Sökmålen för ett visst affärsscenario påverkar dock strukturen för fulltextfrågorna. Till exempel:
Söker efter en produkt på en e-handelswebbplats:
SELECT product_id FROM products WHERE CONTAINS ((product_description), '"Snap Happy 100EZ" OR FORMSOF(THESAURUS,"Snap Happy") OR "100EZ"') AND product_cost < 200;Rekryteringsscenariosökning för jobbkandidater som har erfarenhet av att arbeta med SQL Server:
SELECT candidate_name, SSN FROM candidates WHERE CONTAINS ((candidate_resume), '"SQL Server"') AND candidate_division = 'DBA';
Mer information finns i Fråga med Full-Text Search.
Jämför Full-Text sökfrågor med LIKE-predikatet
Till skillnad från fulltextsökning fungerar LIKE -Transact-SQL predikat endast på teckenmönster. Du kan inte heller använda predikatet LIKE för att fråga efter formaterade binära data. Dessutom är en LIKE fråga mot en stor mängd ostrukturerade textdata mycket långsammare än en motsvarande fulltextfråga mot samma data. Det LIKE kan ta några minuter att returnera en fråga mot miljontals rader med textdata, medan en fulltextfråga bara kan ta sekunder eller mindre mot samma data, beroende på antalet rader som returneras.
Full-Text sökarkitektur
Fulltextsökningsarkitektur består av följande processer:
SQL Server-processen (
sqlservr.exe).Filterdaemonvärdprocessen (
fdhost.exe).Av säkerhetsskäl läses filter in av separata processer som kallas filterdaemonvärdar. Processerna
fdhost.exeskapas av en FDHOST-starttjänst (MSSQLFDLauncher) och de körs under säkerhetsautentiseringsuppgifterna för FDHOST-starttjänstkontot. Därför måste FDHOST-starttjänsten köras för att fulltextindexering och fulltextfrågor ska fungera. Information om hur du anger tjänstkontot för den här tjänsten finns i Ange tjänstkontot för Daemon Launcher för fulltextfilter.
Dessa två processer innehåller komponenterna i fulltextsökningsarkitekturen. Dessa komponenter och deras relationer sammanfattas i följande bild. Komponenterna beskrivs efter bilden.
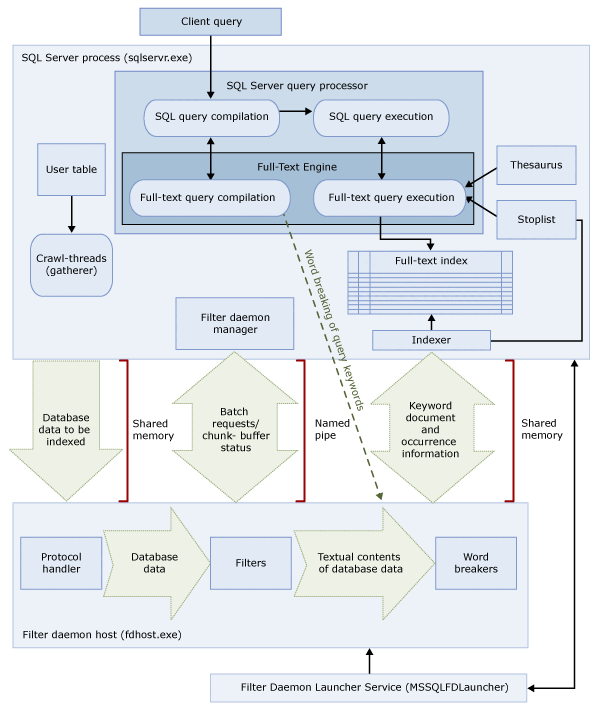
SQL Server-process
SQL Server-processen använder följande komponenter för fulltextsökning:
| Komponent | Beskrivning |
|---|---|
| Användartabeller | Dessa tabeller innehåller de data som ska indexeras i fulltext. |
| Fulltextinsamling | Fulltextinsamlaren samarbetar med fulltextens crawltrådar. Den ansvarar för att schemalägga och driva populationen av fulltextindex och även för övervakning av fulltextkataloger. |
| Synonymordboksfiler | Dessa filer innehåller synonymer med söktermer. Mer information finns i Konfigurera och hantera synonymfiler för Full-Text sökning. |
| Stoppalisteobjekt | Stoplist-objekt innehåller en lista med vanliga ord som inte är användbara för sökningen. Mer information finns i Konfigurera och hantera stoppord och stopplistor för Full-Text Search. |
| SQL Server-frågeprocessor | Frågeprocessorn kompilerar och kör SQL-frågor. Om en SQL-fråga innehåller en fulltextsökningsfråga skickas frågan till Full-Text Engine, både under kompilering och under körningen. Frågeresultatet matchas mot fulltextindexet. |
| Full-Text Motor | Full-Text Engine i SQL Server är helt integrerad med frågeprocessorn. Full-Text Engine kompilerar och kör fulltextfrågor. Som en del av frågekörningen kan motorn Full-Text ta emot indata från en synonymsamling och en stopplista. |
| Indexskrivare (indexerare) | Indexskrivaren skapar den struktur som används för att lagra indexerade token. |
| Filterdaemonhanterare | Filterdaemon-hanteraren ansvarar för att övervaka daemonvärden för Full-Text Engine-filtret. |
Filtrera daemonvärdprocess
Filterdaemonvärden är en process som startas av Full-Text Engine. Den kör följande fulltextsökningskomponenter, som ansvarar för åtkomst, filtrering och ordbrytning av data från tabeller, samt för ordindelning och stamning av frågeindata.
Komponenterna i filterdaemonvärden är följande:
| Komponent | Beskrivning |
|---|---|
| Protokollhanterare | Den här komponenten hämtar data från minnet för vidare bearbetning och åtkomst till data från en användartabell i en angiven databas. Ett av dess ansvarsområden är att samla in data från kolumnerna som indexeras i fulltext och skicka dem till filterdaemonvärden, som tillämpar filtrering och ordbrytare efter behov. |
| Filter | Vissa datatyper kräver filtrering innan data i ett dokument kan indexeras i fulltext, inklusive data i varbinary-, varbinary(max)-, bild- eller XML-kolumner . Filtret som används för ett visst dokument beror på dess dokumenttyp. Olika filter används till exempel för Microsoft Word-dokument (.doc), Microsoft Excel-dokument (.xls) och XML-dokument (.xml). Sedan extraherar filtret textsegment från dokumentet, tar bort inbäddad formatering och behåller texten och eventuellt information om textens position. Resultatet är en ström av textinformation. Mer information finns i Konfigurera och hantera filter för sökning. |
| Ordbrytare och stemmers | En ordbrytare är en språkspecifik komponent som hittar ordgränser baserat på lexikala regler för ett visst språk (ordbrytning). Varje ordbrytare är associerad med en språkspecifik stemmerkomponent som konjugerar verb och utför böjningsutvidgningar. Under indexeringen använder filterdemonens värd en ordbrytare och stemmer för att utföra språklig analys på textdata från en viss tabellkolumn. Språket som är associerat med en tabellkolumn i fulltextindexet avgör vilken ordbrytare och stemmer som används för att indexera kolumnen. Mer information finns i Konfigurera och hantera ordbrytare och stamordbildare för sökning (SQL Server). |
SQL Server 2012 (11.x) installerar en ny version av ordbrytare och ordstammare för amerikansk engelska (LCID 1033) och brittisk engelska (LCID 2057). Du kan dock växla till den tidigare versionen av dessa komponenter om du vill behålla det tidigare beteendet. Mer information finns i Ändra ordbrytaren som används för amerikansk engelska och brittisk engelska.
Full-Text sökbearbetning
Fulltextsökningen drivs av Full-Text Engine. Full-Text Engine har två roller: indexeringsstöd och frågestöd.
Full-Text indexeringsprocess
När en fulltextpopulation (även kallad crawlning) initieras skickar Full-Text Engine stora mängder data till minnet och meddelar filterdaemonvärden. Värden filtrerar och delar upp orden i data och omvandlar den omvandlade datan till inverterade ordlistor. Fulltextsökningen hämtar sedan konverterade data från ordlistorna, bearbetar data för att ta bort stoppord och bevarar ordlistorna för en batch till ett eller flera inverterade index.
När du indexerar data som lagras i en varbinary(max) eller bildkolumn extraherar filtret, som implementerar IFilter gränssnittet, text baserat på det angivna filformatet för dessa data (till exempel Microsoft Word). I vissa fall kräver filterkomponenterna att varbinary(max) eller bilddata skrivs ut till filterdata mappen i stället för att skickas till minnet.
Som en del av bearbetningen skickas de insamlade textdata genom en ordbrytare för att separera texten i enskilda token eller nyckelord. Det språk som används för tokenisering anges på kolumnnivå eller kan identifieras i varbinary(max), bild eller XML-data av filterkomponenten.
Extra bearbetning kan utföras för att ta bort stoppord och normalisera token innan de lagras i fulltextindexet eller ett indexfragment.
När en population är klar utlöses en slutlig sammanslagningsprocess som sammanfogar indexfragmenten till ett huvudindex i fulltext. Detta resulterar i bättre frågeprestanda eftersom endast huvudindexet behöver frågas i stället för flera indexfragment, och bättre bedömningsstatistik kan användas för relevansrankning.
Full-Text frågeprocessen
Frågeprocessorn skickar fulltextdelarna av en fråga till Full-Text Engine för bearbetning. Den Full-Text Engine utför ordbrytning och, om du vill, synonymexpansioner, stamning och stopword (brusord) bearbetning. Sedan representeras fulltextdelarna av frågan i form av SQL-operatorer, främst som strömmande tabellvärdesfunktioner (STVFs). Under frågekörningen kommer dessa STVF:er åt det inverterade indexet för att hämta rätt resultat. Resultatet returneras antingen till klienten vid den här tidpunkten, eller så bearbetas de ytterligare innan de returneras till klienten.
Arkitektur för fulltextindex
Informationen i fulltextindex används av Full-Text Engine för att kompilera fulltextfrågor som snabbt kan söka i en tabell efter specifika ord eller kombinationer av ord. Ett fulltextindex lagrar information om viktiga ord och deras plats i en eller flera kolumner i en databastabell. Ett fulltextindex är en särskild typ av tokenbaserat funktionellt index som skapas och underhålls av Full-Text Engine för SQL Server. Processen med att skapa ett fulltextindex skiljer sig från att skapa andra typer av index. I stället för att konstruera en B-trädstruktur baserat på ett värde som lagras på en viss rad skapar Full-Text Engine en inverterad, staplad, komprimerad indexstruktur baserat på enskilda token från texten som indexeras. Storleken på ett fulltextindex begränsas endast av de tillgängliga minnesresurserna på den dator där SQL Server-instansen körs.
Från och med SQL Server 2008 (10.0.x) är fulltextindexen integrerade med databasmotorn, i stället för att de finns i filsystemet som i tidigare versioner av SQL Server. För en ny databas är fulltextkatalogen nu ett virtuellt objekt som inte tillhör någon filgrupp. det är bara ett logiskt begrepp som refererar till en grupp med fulltextindex. Observera dock att under uppgraderingen av en SQL Server 2005-databas (9.x), alla fulltextkataloger som innehåller datafiler, skapas en ny filgrupp. Mer information finns i Uppgradera Full-Text Search.
Endast ett fulltextindex tillåts per tabell. För att ett fulltextindex ska skapas i en tabell måste tabellen ha en enda unik kolumn som inte är null. Du kan skapa ett fulltextindex på kolumner av typen char, varchar, nchar, nvarchar, text, ntext, image, xml, varbinary och varbinary(max) kan indexeras för fulltextsökning. Om du skapar ett fulltextindex för en kolumn vars datatyp är varbinary, varbinary(max), image eller xml måste du ange en typkolumn. En typkolumn är en tabellkolumn där du lagrar filnamnstillägget (.doc, .pdf, .xlsoch så vidare) av dokumentet på varje rad.
Fulltextindexstruktur
En god förståelse av strukturen för ett fulltextindex hjälper dig att förstå hur Full-Text Engine fungerar. I den här artikeln används följande utdrag av Document tabellen i AdventureWorks2025 som en exempeltabell. Det här utdraget visar bara två kolumner, DocumentID kolumnen och Title kolumnen och tre rader från tabellen.
I det här exemplet förutsätter vi att ett fulltextindex har skapats i Title kolumnen.
| Dokument-ID | Titel |
|---|---|
1 |
Crank Arm and Tire Maintenance |
2 |
Front Reflector Bracket and Reflector Assembly 3 |
3 |
Front Reflector Bracket Installation |
Följande tabell, som visar fragment 1, visar till exempel innehållet i det fulltextindex som skapats i Title kolumnen i Document tabellen. Fulltextindex innehåller mer information än vad som visas i den här tabellen. Tabellen är en logisk representation av ett fulltextindex och tillhandahålls endast i demonstrationssyfte. Raderna lagras i ett komprimerat format för att optimera diskanvändningen.
Datan är inverterad från de ursprungliga dokumenten. Inversion beror på att nyckelorden mappas till dokument-ID:n. Därför kallas ett fulltextindex ofta för ett inverterat index.
Observera också att nyckelordet and tas bort från fulltextindexet. Detta görs eftersom and är ett stoppord, och om du tar bort stoppord från ett fulltextindex kan det leda till stora besparingar i diskutrymmet, vilket förbättrar frågeprestandan. Mer information om stoppord finns i Konfigurera och hantera stoppord och stopplistor för Full-Text Search.
Fragment 1
| Nyckelord | ColId | DocId | Förekomst |
|---|---|---|---|
Crank |
1 | 1 | 1 |
Arm |
1 | 1 | 2 |
Tire |
1 | 1 | 4 |
Maintenance |
1 | 1 | 5 |
Front |
1 | 2 | 1 |
Front |
1 | 3 | 1 |
Reflector |
1 | 2 | 2 |
Reflector |
1 | 2 | 5 |
Reflector |
1 | 3 | 2 |
Bracket |
1 | 2 | 3 |
Bracket |
1 | 3 | 3 |
Assembly |
1 | 2 | 6 |
3 |
1 | 2 | 7 |
Installation |
1 | 3 | 4 |
Kolumnen Keyword innehåller en representation av en enda token som extraheras vid indexeringstiden. Ordbrytare avgör vad som utgör en token.
Kolumnen ColId innehåller ett värde som motsvarar en viss kolumn som är fulltextindexerad.
Kolumnen DocId innehåller värden för ett heltal på 8 byte som mappar till ett visst nyckelvärde i fulltext i en indexerad tabell med fulltext. Den här mappningen är nödvändig när fulltextnyckeln inte är en heltalsdatatyp. I sådana fall bevaras mappningar mellan fulltextnyckelvärden och DocId-värden i en separat tabell som kallas DocId Mapping. För att använda dessa mappningar, använd den lagrade systemproceduren sp_fulltext_keymappings. För att uppfylla ett sökvillkor DocId måste värden från den föregående tabellen kopplas till mappningstabellen DocId för att hämta rader från bastabellen som efterfrågas. Om nyckelvärdet i fulltext i bastabellen är en heltalstyp fungerar värdet direkt som DocId och ingen mappning krävs. Genom att använda heltalsnyckelvärden i fulltext kan du därför optimera fulltextfrågor.
Kolumnen Occurrence innehåller ett heltalsvärde. För varje DocId-värde finns det en lista med förekomstvärden som motsvarar de relativa ordförskjutningarna för det specifika nyckelordet inom den aktuella DocId. Förekomstvärden är användbara för att fastställa fras- eller närhetsmatchningar, till exempel fraser som har numeriskt angränsande förekomstvärden. De är också användbara för att beräkna relevanspoäng; Till exempel kan antalet förekomster av ett nyckelord i ett DocId användas i bedömning.
Fulltextindexfragment
Det logiska fulltextindexet delas vanligtvis upp i flera interna tabeller. Varje intern tabell kallas för ett fulltextindexfragment. Vissa av dessa fragment kan innehålla nyare data än andra. Om en användare till exempel uppdaterar följande rad vars DocId är 3 och tabellen ändras automatiskt skapas ett nytt fragment.
| Dokument-ID | Titel |
|---|---|
3 |
Rear Reflector |
I följande exempel, som visar Fragment 2, innehåller fragmentet nyare data om DocId 3 jämfört med Fragment 1. Därför används data från Fragment 2 för DocId 3 när användaren efterfrågar Rear Reflector. Varje fragment markeras med en tidsstämpel vid skapandet som kan efterfrågas med hjälp av sys.fulltext_index_fragments katalogvyn.
Fragment 2
| Nyckelord | ColId | DocId | Occ |
|---|---|---|---|
Rear |
1 | 3 | 1 |
Reflector |
1 | 3 | 2 |
Som framgår av fragment 2 måste fulltextfrågor söka i varje fragment internt och rensa bort äldre poster. Därför kan för många fulltextindexfragment i fulltextindex leda till betydande försämring av frågeprestanda. Om du vill minska antalet fragment, ordna om fulltextkatalogen genom att använda alternativet REORGANIZE på ALTER FULLTEXT CATALOGTransact-SQL-instruktionen. Den här instruktionen utför en huvudsammanslagning som sammanfogar fragmenten till ett enda större fragment och tar bort alla föråldrade poster från fulltextindexet.
När omorganiseras innehåller exempelindexet följande rader:
| Nyckelord | ColId | DocId | Occ |
|---|---|---|---|
Crank |
1 | 1 | 1 |
Arm |
1 | 1 | 2 |
Tire |
1 | 1 | 4 |
Maintenance |
1 | 1 | 5 |
Front |
1 | 2 | 1 |
Rear |
1 | 3 | 1 |
Reflector |
1 | 2 | 2 |
Reflector |
1 | 2 | 5 |
Reflector |
1 | 3 | 2 |
Bracket |
1 | 2 | 3 |
Assembly |
1 | 2 | 6 |
3 |
1 | 2 | 7 |
Skillnader mellan fulltextindex och vanliga SQL Server-index
| Fulltextindexer | Vanliga SQL Server-index |
|---|---|
| Endast ett fulltextindex tillåts per tabell. | Flera vanliga index tillåts per tabell. |
| Tillägg av data till fulltextindex, som kallas population, kan begäras via antingen ett schema eller en specifik begäran eller kan ske automatiskt med tillägg av nya data. | Uppdateras automatiskt när de data som de baseras på infogas, uppdateras eller tas bort. |
| Grupperad i samma databas i en eller flera fulltextkataloger. | Inte grupperad. |
Full-Text sök språkkomponenter och språkstöd
Fulltextsökning stöder nästan 50 olika språk, till exempel engelska, spanska, kinesiska, japanska, arabiska, Bangla och hindi. En fullständig lista över de fulltextspråk som stöds finns i sys.fulltext_languages. Var och en av kolumnerna i fulltextindexet är associerad med en Microsoft Windows-språkidentifierare (LCID) som motsvarar ett språk som stöds av fulltextsökning. LCID 1033 motsvarar till exempel amerikansk engelska, och LCID 2057 motsvarar brittisk engelska. För varje fulltextspråk som stöds tillhandahåller SQL Server språkkomponenter som stöder indexering och frågekörning av fulltextdata som lagras på det språket.
Språkspecifika komponenter innehåller följande objekt:
| Komponent | Beskrivning |
|---|---|
| Ordbrytare och stemmers | En ordbrytare hittar ordgränser baserat på lexikala regler för ett visst språk (ordbrytning). Varje ordbrytare är associerad med en stemmer som konjugerar verb för samma språk. Mer information finns i Konfigurera och hantera ordbrytare och stamordbildare för sökning (SQL Server). |
| Stopplistor | En systemstopplista tillhandahålls, som innehåller en grundläggande uppsättning stoppord (kallas även brusord). Ett stoppord är ett ord som inte hjälper sökningen och som ignoreras av fulltextfrågor. Till exempel, för det engelska språket betraktas ord som a, and, is, och the som stoppord. Normalt behöver du konfigurera en eller flera synonymfiler och stopplistor. Mer information finns i Konfigurera och hantera stoppord och stopplistor för Full-Text Search. |
| Synonymordboksfiler | SQL Server installerar också en synonymfil för varje fulltextspråk och en global synonymfil. De installerade synonymordboksfilerna är tomma, men du kan redigera dem för att definiera synonymer för ett specifikt språk eller affärsscenario. Genom att utveckla en synonymordlista som är anpassad till dina fulltextdata kan du effektivt bredda omfattningen av fulltextfrågor på dessa data. Mer information finns i Konfigurera och hantera synonymfiler för Full-Text sökning. |
| Filter (iFilters) | För att indexera ett dokument i en kolumn av typen varbinary(max), bild eller XML-datatyp krävs ett filter för att utföra extra bearbetning. Filtret måste vara specifikt för dokumenttypen (.doc, , .pdf.xls, .xmloch så vidare). Mer information finns i Konfigurera och hantera filter för sökning. |
Ord-brytare (och stammare) och filter körs i värdprocessen för filterdaemoner (fdhost.exe).