Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
gäller för:![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)
CREATE TABLE AS SELECT (CTAS) är en av de viktigaste T-SQL-funktionerna som finns. Det är en helt parallelliserad operation som skapar en ny tabell baserat på utdata från ett SELECT-uttalande. CTAS är det enklaste och snabbaste sättet att skapa en kopia av en tabell.
Till exempel, använd CTAS för att:
- Skapa om en tabell med en annan hashfördelningskolumn.
- Skapa om en tabell som replikerad.
- Skapa ett kolumnlagringsindex på bara några av kolumnerna i tabellen.
- Fråga eller importera extern data.
Anmärkning
Eftersom CREATE TABLE AS SELECT (CTAS) ökar möjligheterna att skapa en tabell försöker detta ämne undvika att upprepa ämnet CREATE TABLE . Istället beskriver den skillnaderna mellan CTAS och CREATE TABLE.
- CTAS stöds i Warehouse i Microsoft Fabric. Visa Fabric-versionen av artikeln SKAPA TABELL SOM VÄLJ.
- Den här syntaxen stöds inte av en serverlös SQL-pool i Azure Synapse Analytics.
-
CREATE TABLE AS SELECT(CTAS) stöds i lagret i Microsoft Fabric. För mer information, se Fabric Data Warehouse-versionen av denna artikel.
![]() Transact-SQL syntaxkonventioner
Transact-SQL syntaxkonventioner
Syntax
CREATE TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
[ ( column_name [ ,...n ] ) ]
WITH (
<distribution_option> -- required
[ , <table_option> [ ,...n ] ]
)
AS <select_statement>
OPTION <query_hint>
[;]
<distribution_option> ::=
{
DISTRIBUTION = HASH ( distribution_column_name )
| DISTRIBUTION = HASH ( [distribution_column_name [, ...n]] )
| DISTRIBUTION = ROUND_ROBIN
| DISTRIBUTION = REPLICATE
}
<table_option> ::=
{
CLUSTERED COLUMNSTORE INDEX --default for Synapse Analytics
| CLUSTERED COLUMNSTORE INDEX ORDER (column[,...n])
| HEAP --default for Parallel Data Warehouse
| CLUSTERED INDEX ( { index_column_name [ ASC | DESC ] } [ ,...n ] ) --default is ASC
}
| PARTITION ( partition_column_name RANGE [ LEFT | RIGHT ] --default is LEFT
FOR VALUES ( [ boundary_value [,...n] ] ) )
<select_statement> ::=
[ WITH <common_table_expression> [ ,...n ] ]
SELECT select_criteria
<query_hint> ::=
{
MAXDOP
}
Arguments
För mer information, se avsnittet Argument i CREATE TABLE.
Kolumnalternativ
column_name [ ,...n ]
Kolumnnamn tillåter inte de kolumnalternativ SKAPA TABELL som nämns i CREATE TABLE. I stället kan du ange en valfri lista med ett eller flera kolumnnamn för den nya tabellen. Kolumnerna i den nya tabellen använder de namn som du anger. När du anger kolumnnamn måste antalet kolumner i kolumnlistan matcha antalet kolumner i urvalsresultatet. Om du inte anger några kolumnnamn använder den nya måltabellen kolumnnamnen i select-instruktionsresultatet.
Du kan inte ange några andra kolumnalternativ, till exempel datatyper, sortering eller nullabilitet. Var och en av dessa attribut härleds från resultatet av påståendet SELECT . Du kan dock använda SELECT-instruktionen för att ändra attributen. För ett exempel, se Använd CTAS för att ändra kolumnattribut.
Tabellfördelningsalternativ
För detaljer och för att förstå hur man väljer kolumnen för bästa fördelning, se avsnittet Tabellfördelningsalternativ i CREATE TABLE. För rekommendationer om vilken distribution man ska välja för en tabell baserat på faktisk användning eller exempelfrågor, se Distribution Advisor i Azure Synapse SQL.
DISTRIBUTION
=
HASH (distribution_column_name) | ROUND_ROBIN | REPLIKERA
CTAS-uttalandet kräver ett distributionsalternativ och har inga standardvärden. Detta skiljer sig från CREATE TABLE, som har standardinställningar.
DISTRIBUTION = HASH ( [distribution_column_name [, ...n]] )
Fördelar raderna baserat på hashvärden för upp till åtta kolumner, vilket möjliggör en jämnare fördelning av bastabelldata, minskar dataskevheten över tid och förbättrar frågeprestandan.
Anmärkning
- För att aktivera funktionen, ändra databasens kompatibilitetsnivå till 50 med detta kommando. För mer information om hur du ställer in databaskompatibilitetsnivån, se ALTER DATABASE SCOPED CONFIGURATION. Till exempel:
ALTER DATABASE SCOPED CONFIGURATION SET DW_COMPATIBILITY_LEVEL = 50; - För att inaktivera funktionen för multikolumndistribution (MCD), kör detta kommando för att ändra databasens kompatibilitetsnivå till AUTO. Till exempel:
ALTER DATABASE SCOPED CONFIGURATION SET DW_COMPATIBILITY_LEVEL = AUTO;Befintliga MCD-tabeller kommer att finnas kvar men bli oläsliga. Frågor över MCD-tabeller ger detta fel:Related table/view is not readable because it distributes data on multiple columns and multi-column distribution is not supported by this product version or this feature is disabled.- För att återfå tillgång till MCD-tabeller, aktivera funktionen igen.
- För att ladda data i en MCD-tabell, använd CTAS-satsen och datakällan måste vara Synapse SQL-tabeller.
- CTAS på MCD HEAP-måltabeller stöds inte. Använd istället INSERT SELECT som en lösning för att ladda data i MCD HEAP-tabeller.
- Att använda SSMS för att generera ett skript för att skapa MCD-tabeller stöds för närvarande även efter SSMS version 19.
För detaljer och för att förstå hur man väljer kolumnen för bästa fördelning, se avsnittet Tabellfördelningsalternativ i CREATE TABLE.
För rekommendationer om den bästa distributionen att använda baserat på dina arbetsbelastningar, se Synapse SQL Distribution Advisor (Preview).
Tabellpartitionsalternativ
CTAS-satsen skapar som standard en icke-partitionerad tabell, även om källtabellen är partitionerad. För att skapa en partitionerad tabell med CTAS-satsen måste du ange partitionsalternativet.
För detaljer, se avsnittet om tabellpartitionsalternativ i CREATE TABLE.
SELECT-instruktion
SELECT-satsen är den grundläggande skillnaden mellan CTAS och CREATE TABLE.
WITH
common_table_expression
Anger en tillfällig namngiven resultatuppsättning, som kallas för ett gemensamt tabelluttryck (CTE). Mer information finns i WITH common_table_expression (Transact-SQL).
SELECT
select_criteria
Fyller i den nya tabellen med resultatet från en SELECT-instruktion. select_criteria är brödtexten i SELECT-instruktionen som avgör vilka data som ska kopieras till den nya tabellen. Information om SELECT-instruktioner finns i SELECT (Transact-SQL).
Frågetips
Användare kan ställa in MAXDOP till ett heltalsvärde för att kontrollera maximal grad av parallellism. När MAXDOP är satt till 1 utförs frågan av en enda tråd.
Permissions
CTAS kräver SELECT tillstånd för alla objekt som refereras i select_criteria.
För behörigheter att skapa en tabell, se Behörigheter i CREATE TABLE.
Anmärkningar
För detaljer, se Allmänna anmärkningar i CREATE TABLE.
Begränsningar och restriktioner
För mer information om begränsningar och restriktioner, se Begränsningar och restriktioner i CREATE TABLE.
Ett ordnat klustrat kolumnlagringsindex kan skapas på kolumner av alla datatyper som stöds i Azure Synapse Analytics utom strängkolumner.
SET ROWCOUNT (Transact-SQL) har ingen effekt på CTAS. Använd TOP (Transact-SQL)för att uppnå ett liknande beteende.
CTAS stöder
OPENJSONinte funktionen som en del av uttalandetSELECT. Som alternativ, användINSERT INTO ... SELECT. Till exempel:DECLARE @json NVARCHAR(MAX) = N' [ { "id": 1, "name": "Alice", "age": 30, "address": { "street": "123 Main St", "city": "Wonderland" } }, { "id": 2, "name": "Bob", "age": 25, "address": { "street": "456 Elm St", "city": "Gotham" } } ]'; INSERT INTO Users (id, name, age, street, city) SELECT id, name, age, JSON_VALUE(address, '$.street') AS street, JSON_VALUE(address, '$.city') AS city FROM OPENJSON(@json) WITH ( id INT, name NVARCHAR(50), age INT, address NVARCHAR(MAX) AS JSON );
Låsningsbeteende
För detaljer, se Låsbeteende i CREATE TABLE.
Performance
För en hashdistribuerad tabell kan du använda CTAS för att välja en annan distributionskolumn för att uppnå bättre prestanda för joins och aggregeringar. Om det inte är ditt mål att välja en annan distributionskolumn, får du bäst CTAS-prestanda om du anger samma distributionskolumn eftersom detta undviker omfördelning av raderna.
Om du använder CTAS för att skapa tabeller och prestanda inte är en faktor, kan du specificera ROUND_ROBIN för att slippa bestämma dig för en distributionskolumn.
För att undvika datarörelse i efterföljande frågor kan du specificera REPLICATE att till priset av ökad lagring laddas en fullständig kopia av tabellen på varje Compute-nod.
Exempel för att kopiera en tabell
A. Använd CTAS för att kopiera en tabell
Gäller för: Azure Synapse Analytics and Analytics Platform System (PDW)
Kanske är en av de vanligaste användningarna CTAS att skapa en kopia av en tabell så att du kan ändra DDL. Om du till exempel ursprungligen skapade din tabell och ROUND_ROBIN nu vill ändra den till en tabell distribuerad på en kolumn, CTAS är det så du skulle ändra fördelningskolumnen.
CTAS kan också användas för att ändra partitionering, indexering eller kolumntyper.
Låt oss säga att du skapade denna tabell genom att specificera HEAP och använda standarddistributionstypen .ROUND_ROBIN
CREATE TABLE FactInternetSales
(
ProductKey INT NOT NULL,
OrderDateKey INT NOT NULL,
DueDateKey INT NOT NULL,
ShipDateKey INT NOT NULL,
CustomerKey INT NOT NULL,
PromotionKey INT NOT NULL,
CurrencyKey INT NOT NULL,
SalesTerritoryKey INT NOT NULL,
SalesOrderNumber NVARCHAR(20) NOT NULL,
SalesOrderLineNumber TINYINT NOT NULL,
RevisionNumber TINYINT NOT NULL,
OrderQuantity SMALLINT NOT NULL,
UnitPrice MONEY NOT NULL,
ExtendedAmount MONEY NOT NULL,
UnitPriceDiscountPct FLOAT NOT NULL,
DiscountAmount FLOAT NOT NULL,
ProductStandardCost MONEY NOT NULL,
TotalProductCost MONEY NOT NULL,
SalesAmount MONEY NOT NULL,
TaxAmt MONEY NOT NULL,
Freight MONEY NOT NULL,
CarrierTrackingNumber NVARCHAR(25),
CustomerPONumber NVARCHAR(25)
)
WITH(
HEAP,
DISTRIBUTION = ROUND_ROBIN
);
Nu vill du skapa en ny kopia av denna tabell med ett klustrat kolumnlagringsindex så att du kan dra nytta av prestandan hos klustrade kolumnlagringstabeller. Du vill också distribuera denna tabell på ProductKey eftersom du förväntar dig joins på denna kolumn och vill undvika datarörelse under joins på ProductKey. Slutligen vill du också lägga till OrderDateKey partitionering så att du snabbt kan radera gammal data genom att ta bort gamla partitioner. Här är CTAS-satsen som skulle kopiera din gamla tabell till en ny tabell:
CREATE TABLE FactInternetSales_new
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH(ProductKey),
PARTITION
(
OrderDateKey RANGE RIGHT FOR VALUES
(
20000101,20010101,20020101,20030101,20040101,20050101,20060101,20070101,20080101,20090101,
20100101,20110101,20120101,20130101,20140101,20150101,20160101,20170101,20180101,20190101,
20200101,20210101,20220101,20230101,20240101,20250101,20260101,20270101,20280101,20290101
)
)
)
AS SELECT * FROM FactInternetSales;
Slutligen kan du byta namn på dina tabeller för att byta ut din nya tabell och sedan ta bort din gamla tabell.
RENAME OBJECT FactInternetSales TO FactInternetSales_old;
RENAME OBJECT FactInternetSales_new TO FactInternetSales;
DROP TABLE FactInternetSales_old;
Exempel på kolumnalternativ
B. Använd CTAS för att ändra kolumnattribut
Gäller för: Azure Synapse Analytics and Analytics Platform System (PDW)
Detta exempel använder CTAS för att ändra datatyper, nullbarhet och sortering för flera kolumner i tabellen DimCustomer2 .
-- Original table
CREATE TABLE [dbo].[DimCustomer2] (
[CustomerKey] INT NOT NULL,
[GeographyKey] INT NULL,
[CustomerAlternateKey] nvarchar(15) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL
)
WITH (CLUSTERED COLUMNSTORE INDEX, DISTRIBUTION = HASH([CustomerKey]));
-- CTAS example to change data types, nullability, and column collations
CREATE TABLE test
WITH (HEAP, DISTRIBUTION = ROUND_ROBIN)
AS
SELECT
CustomerKey AS CustomerKeyNoChange,
CustomerKey*1 AS CustomerKeyChangeNullable,
CAST(CustomerKey AS DECIMAL(10,2)) AS CustomerKeyChangeDataTypeNullable,
ISNULL(CAST(CustomerKey AS DECIMAL(10,2)),0) AS CustomerKeyChangeDataTypeNotNullable,
GeographyKey AS GeographyKeyNoChange,
ISNULL(GeographyKey,0) AS GeographyKeyChangeNotNullable,
CustomerAlternateKey AS CustomerAlternateKeyNoChange,
CASE WHEN CustomerAlternateKey = CustomerAlternateKey
THEN CustomerAlternateKey END AS CustomerAlternateKeyNullable,
CustomerAlternateKey COLLATE Latin1_General_CS_AS_KS_WS AS CustomerAlternateKeyChangeCollation
FROM [dbo].[DimCustomer2]
-- Resulting table
CREATE TABLE [dbo].[test] (
[CustomerKeyNoChange] INT NOT NULL,
[CustomerKeyChangeNullable] INT NULL,
[CustomerKeyChangeDataTypeNullable] DECIMAL(10, 2) NULL,
[CustomerKeyChangeDataTypeNotNullable] DECIMAL(10, 2) NOT NULL,
[GeographyKeyNoChange] INT NULL,
[GeographyKeyChangeNotNullable] INT NOT NULL,
[CustomerAlternateKeyNoChange] NVARCHAR(15) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL,
[CustomerAlternateKeyNullable] NVARCHAR(15) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[CustomerAlternateKeyChangeCollation] NVARCHAR(15) COLLATE Latin1_General_CS_AS_KS_WS NOT NULL
)
WITH (DISTRIBUTION = ROUND_ROBIN);
Som ett sista steg kan du använda RENAME (Transact-SQL) för att byta tabellnamn. Detta gör att DimCustomer2 blir den nya tabellen.
RENAME OBJECT DimCustomer2 TO DimCustomer2_old;
RENAME OBJECT test TO DimCustomer2;
DROP TABLE DimCustomer2_old;
Exempel på tabellfördelning
C. Använd CTAS för att ändra distributionsmetoden för en tabell
Gäller för: Azure Synapse Analytics and Analytics Platform System (PDW)
Detta enkla exempel visar hur man ändrar fördelningsmetoden för en tabell. För att visa hur detta ska göras ändras en hashdistribuerad tabell till round-robin och sedan round-robin-tabellen tillbaka till hash-distribuerad. Det slutgiltiga bordet matchar det ursprungliga bordet.
I de flesta fall behöver du inte byta en hashdistribuerad tabell till en round-robin-tabell. Oftare kan du behöva byta ut en round-robin-tabell till en hashdistribuerad tabell. Till exempel kan du initialt ladda en ny tabell som round-robin och sedan senare flytta den till en hashdistribuerad tabell för att få bättre join-prestanda.
Detta exempel använder AdventureWorksDW:s exempeldatabas. För att ladda Azure Synapse Analytics-versionen, se Quickstart: Create and querya a dedicated SQL pool (tidigare SQL PW) i Azure Synapse Analytics med Azure-portalen.
-- DimSalesTerritory is hash-distributed.
-- Copy it to a round-robin table.
CREATE TABLE [dbo].[myTable]
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN
)
AS SELECT * FROM [dbo].[DimSalesTerritory];
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[myTable] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
Därefter ändrar du tillbaka till en hashdistribuerad tabell.
-- You just made DimSalesTerritory a round-robin table.
-- Change it back to the original hash-distributed table.
CREATE TABLE [dbo].[myTable]
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH(SalesTerritoryKey)
)
AS SELECT * FROM [dbo].[DimSalesTerritory];
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[myTable] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
D. Använd CTAS för att konvertera en tabell till en replikerad tabell
Gäller för: Azure Synapse Analytics and Analytics Platform System (PDW)
Detta exempel gäller för att konvertera round-robin- eller hashdistribuerade tabeller till en replikerad tabell. Detta specifika exempel tar den tidigare metoden att ändra fördelningstypen ett steg längre. Eftersom DimSalesTerritory är en dimension och troligen en mindre tabell kan du välja att återskapa tabellen som replikerad för att undvika datarörelse vid sammanfogning med andra tabeller.
-- DimSalesTerritory is hash-distributed.
-- Copy it to a replicated table.
CREATE TABLE [dbo].[myTable]
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = REPLICATE
)
AS SELECT * FROM [dbo].[DimSalesTerritory];
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[myTable] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
E. Använd CTAS för att skapa en tabell med färre kolumner
Gäller för: Azure Synapse Analytics and Analytics Platform System (PDW)
Följande exempel skapar en round-robin-distribuerad tabell med namnet myTable (c, ln). Den nya tabellen har bara två kolumner. Den använder kolumnaliasen i SELECT-satsen för kolumnnamnen.
CREATE TABLE myTable
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN
)
AS SELECT CustomerKey AS c, LastName AS ln
FROM dimCustomer;
Exempel på frågeledtrådar
F. Använd en frågeledtråd med CREATE TABLE AS SELECT (CTAS)
Gäller för: Azure Synapse Analytics and Analytics Platform System (PDW)
Denna fråga visar den grundläggande syntaxen för att använda en query join-ledtråd med CTAS-satsen. Efter att frågan har skickats in applicerar Azure Synapse Analytics hash-join-strategin när det genererar frågeplanen för varje enskild distribution. För mer information om hash-join-frågan, se OPTION-klausulen (Transact-SQL).
CREATE TABLE dbo.FactInternetSalesNew
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN
)
AS SELECT T1.* FROM dbo.FactInternetSales T1 JOIN dbo.DimCustomer T2
ON ( T1.CustomerKey = T2.CustomerKey )
OPTION ( HASH JOIN );
Exempel för externa tabeller
G. Använd CTAS för att importera data från Azure Blob-lagring
Gäller för: Azure Synapse Analytics and Analytics Platform System (PDW)
För att importera data från en extern tabell, använd SKAPA TABELL SOM VÄLJ för att välja från den externa tabellen. Syntaxen för att välja data från en extern tabell i Azure Synapse Analytics är densamma som syntaxen för att välja data från en vanlig tabell.
Följande exempel definierar en extern tabell över data i ett Azure Blob Storage-konto. Den använder sedan CREATE TABLE AS SELECT för att välja från den externa tabellen. Detta importerar data från Azure Blob Storage textdeparerade filer och lagrar datan i en ny Azure Synapse Analytics-tabell.
--Use your own processes to create the text-delimited files on Azure Blob Storage.
--Create the external table called ClickStream.
CREATE EXTERNAL TABLE ClickStreamExt (
url VARCHAR(50),
event_date DATE,
user_IP VARCHAR(50)
)
WITH (
LOCATION='/logs/clickstream/2015/',
DATA_SOURCE = MyAzureStorage,
FILE_FORMAT = TextFileFormat)
;
--Use CREATE TABLE AS SELECT to import the Azure Blob Storage data into a new
--Synapse Analytics table called ClickStreamData
CREATE TABLE ClickStreamData
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH (user_IP)
)
AS SELECT * FROM ClickStreamExt
;
H. Använd CTAS för att importera Hadoop-data från en extern tabell
Gäller för: Analytics Platform System (PDW)
För att importera data från en extern tabell, använd helt enkelt SKAPA TABELL SOM VÄLJ för att välja från den externa tabellen. Syntaxen för att välja data från en extern tabell i Analytics Platform System (PDW) är densamma som syntaxen för att välja data från en vanlig tabell.
Följande exempel definierar en extern tabell på ett Hadoop-kluster. Den använder sedan CREATE TABLE AS SELECT för att välja från den externa tabellen. Detta importerar data från Hadoops textseparerade filer och lagrar datan i en ny Analytics Platform System (PDW)-tabell.
-- Create the external table called ClickStream.
CREATE EXTERNAL TABLE ClickStreamExt (
url VARCHAR(50),
event_date DATE,
user_IP VARCHAR(50)
)
WITH (
LOCATION = 'hdfs://MyHadoop:5000/tpch1GB/employee.tbl',
FORMAT_OPTIONS ( FIELD_TERMINATOR = '|')
)
;
-- Use your own processes to create the Hadoop text-delimited files
-- on the Hadoop Cluster.
-- Use CREATE TABLE AS SELECT to import the Hadoop data into a new
-- table called ClickStreamPDW
CREATE TABLE ClickStreamPDW
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH (user_IP)
)
AS SELECT * FROM ClickStreamExt
;
Exempel som använder CTAS för att ersätta SQL Server-kod
Använd CTAS för att kringgå vissa funktioner som inte stöds. Förutom att kunna köra din kod på datalagret, brukar omskrivning av befintlig kod för att använda CTAS förbättra prestandan. Detta är ett resultat av dess helt parallelliserade design.
Anmärkning
Försök tänka "CTAS först". Om du tror att du kan lösa ett problem med hjälp CTAS är det generellt det bästa sättet att närma sig det – även om du skriver mer data som resultat.
I. Använd CTAS istället för SELECT.. IN
Gäller för: Azure Synapse Analytics and Analytics Platform System (PDW)
SQL Server-kod använder vanligtvis SELECT.. INTO för att fylla en tabell med resultaten från ett SELECT-uttalande. Detta är ett exempel på en SQL Server SELECT.. IN-uttalandet.
SELECT *
INTO #tmp_fct
FROM [dbo].[FactInternetSales]
Denna syntax stöds inte i Azure Synapse Analytics och Parallel Data Warehouse. Detta exempel visar hur man skriver om föregående SELECT.. INTO-uttalande som ett CTAS-uttalande. Du kan välja vilket av DISTRIBUTION-alternativen som beskrivs i CTAS-syntaxen. Detta exempel använder ROUND_ROBIN fördelningsmetoden.
CREATE TABLE #tmp_fct
WITH
(
DISTRIBUTION = ROUND_ROBIN
)
AS
SELECT *
FROM [dbo].[FactInternetSales]
;
J. Använd CTAS för att förenkla sammanslagningssatser
Gäller för: Azure Synapse Analytics and Analytics Platform System (PDW)
Merge-satser kan ersättas, åtminstone delvis, genom att använda CTAS. Du kan slå ihop och INSERT till UPDATE ett enda uttalande. Alla raderade poster måste stängas i ett andra uttalande.
Ett exempel på en UPSERT följer:
CREATE TABLE dbo.[DimProduct_upsert]
WITH
( DISTRIBUTION = HASH([ProductKey])
, CLUSTERED INDEX ([ProductKey])
)
AS
-- New rows and new versions of rows
SELECT s.[ProductKey]
, s.[EnglishProductName]
, s.[Color]
FROM dbo.[stg_DimProduct] AS s
UNION ALL
-- Keep rows that are not being touched
SELECT p.[ProductKey]
, p.[EnglishProductName]
, p.[Color]
FROM dbo.[DimProduct] AS p
WHERE NOT EXISTS
( SELECT *
FROM [dbo].[stg_DimProduct] s
WHERE s.[ProductKey] = p.[ProductKey]
)
;
RENAME OBJECT dbo.[DimProduct] TO [DimProduct_old];
RENAME OBJECT dbo.[DimProduct_upsert] TO [DimProduct];
K. Explicit tillståndsdatatyp och nullbarhet av utdata
Gäller för: Azure Synapse Analytics and Analytics Platform System (PDW)
När du migrerar SQL Server-kod till Azure Synapse Analytics kan du stöta på denna typ av kodningsmönster:
DECLARE @d DECIMAL(7,2) = 85.455
, @f FLOAT(24) = 85.455
CREATE TABLE result
(result DECIMAL(7,2) NOT NULL
)
WITH (DISTRIBUTION = ROUND_ROBIN)
INSERT INTO result
SELECT @d*@f
;
Instinktivt kanske du tror att du borde migrera denna kod till en CTAS och då har du rätt. Men det finns ett dolt problem här.
Följande kod ger INTE samma resultat:
DECLARE @d DECIMAL(7,2) = 85.455
, @f FLOAT(24) = 85.455
;
CREATE TABLE ctas_r
WITH (DISTRIBUTION = ROUND_ROBIN)
AS
SELECT @d*@f as result
;
Observera att kolumnens "resultat" för vidare datatyp- och nullbarhetsvärdena för uttrycket. Detta kan leda till subtila variationer i värden om du inte är försiktig.
Prova följande som exempel:
SELECT result,result*@d
from result
;
SELECT result,result*@d
from ctas_r
;
Värdet som lagras för resultat är annorlunda. Eftersom det bevarade värdet i resultatkolumnen används i andra uttryck blir felet ännu mer betydelsefullt.
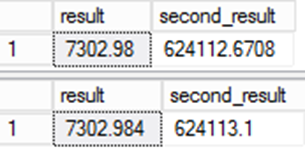
Detta är viktigt för datamigreringar. Även om den andra frågan kanske är mer korrekt finns det ett problem. Datan skulle skilja sig från källsystemet och det leder till frågor om integriteten i migreringen. Det här är ett av de sällsynta fallen där det "felaktiga" svaret faktiskt är det rätta!
Anledningen till att vi ser denna skillnad mellan de två resultaten beror på implicit typcasting. I det första exemplet definierar tabellen kolumndefinitionen. När raden infogas sker en implicit typkonvertering. I det andra exemplet finns ingen implicit typkonvertering eftersom uttrycket definierar kolumnens datatyp. Observera också att kolumnen i det andra exemplet har definierats som en NULLbar kolumn medan den i det första exemplet inte har det. När tabellen skapades i det första exemplet definierades kolumnen att nulla explicit. I det andra exemplet lämnades uttrycket till uttrycket och som standard skulle detta resultera i en NULL definition.
För att lösa dessa problem måste du uttryckligen sätta typkonvertering och nullbarhet i den SELECT del av satsen CTAS . Du kan inte ställa in dessa egenskaper i delen skapa tabell.
Detta exempel visar hur man fixar koden:
DECLARE @d DECIMAL(7,2) = 85.455
, @f FLOAT(24) = 85.455
CREATE TABLE ctas_r
WITH (DISTRIBUTION = ROUND_ROBIN)
AS
SELECT ISNULL(CAST(@d*@f AS DECIMAL(7,2)),0) as result
Observera följande i exemplet:
- CAST eller CONVERT kunde ha använts.
- ISNULL används för att tvinga fram NULLability, inte COALESCE.
- ISNULL är den yttersta funktionen.
- Den andra delen av ISNULL är en konstant,
0.
Anmärkning
För att nullbarheten ska vara korrekt inställd är det avgörande att använda ISNULL och inte COALESCE.
COALESCE är inte en deterministisk funktion och därför kommer resultatet av uttrycket alltid att vara NULLbart.
ISNULL är annorlunda. Det är deterministiskt. Därför, när den andra delen av ISNULL funktionen är en konstant eller ett literal, kommer det resulterande värdet INTE att vara NULL.
Detta tips är inte bara användbart för att säkerställa integriteten i dina beräkningar. Det är också viktigt för tabellpartitionsbyte. Föreställ dig att du har denna tabell definierad som ditt faktum:
CREATE TABLE [dbo].[Sales]
(
[date] INT NOT NULL
, [product] INT NOT NULL
, [store] INT NOT NULL
, [quantity] INT NOT NULL
, [price] MONEY NOT NULL
, [amount] MONEY NOT NULL
)
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101,20020101
,20030101,20040101,20050101
)
)
)
;
Dock är värdefältet ett beräknat uttryck, det ingår inte i källdatan.
För att skapa din partitionerade dataset, överväg följande exempel:
CREATE TABLE [dbo].[Sales_in]
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101
)
)
)
AS
SELECT
[date]
, [product]
, [store]
, [quantity]
, [price]
, [quantity]*[price] AS [amount]
FROM [stg].[source]
OPTION (LABEL = 'CTAS : Partition IN table : Create')
;
Frågan skulle fungera helt utan problem. Problemet uppstår när du försöker göra partitionbytet. Tabelldefinitionerna stämmer inte överens. För att göra tabelldefinitionerna måste CTAS ändras.
CREATE TABLE [dbo].[Sales_in]
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101
)
)
)
AS
SELECT
[date]
, [product]
, [store]
, [quantity]
, [price]
, ISNULL(CAST([quantity]*[price] AS MONEY),0) AS [amount]
FROM [stg].[source]
OPTION (LABEL = 'CTAS : Partition IN table : Create');
Du kan därför se att typkonsistens och att upprätthålla nullbarhetsegenskaper på en CTAS är god ingenjörspraxis. Det hjälper till att upprätthålla integriteten i dina beräkningar och säkerställer också att partitionsbyte är möjligt.
L. Skapa ett ordnat klustrat kolumnlagringsindex med MAXDOP 1
CREATE TABLE Table1 WITH (DISTRIBUTION = HASH(c1), CLUSTERED COLUMNSTORE INDEX ORDER(c1) )
AS SELECT * FROM ExampleTable
OPTION (MAXDOP 1);
Relaterat innehåll
- SKAPA EXTERN DATAKÄLLA (Transact-SQL)
- SKAPA EXTERNT FILFORMAT (Transact-SQL)
- SKAPA EXTERN TABELL (Transact-SQL)
- SKAPA EXTERN TABELL SOM SELECT (Transact-SQL)
- CREATE TABLE (Azure Synapse Analytics)
- DROP-TABELL (Transact-SQL)
- SLÄPP EXTERN TABELL (Transact-SQL)
- ALTER TABLE (Transact-SQL)
- ÄNDRA EXTERN TABELL (Transact-SQL)
gäller för:![]() Warehouse i Microsoft Fabric
Warehouse i Microsoft Fabric
CREATE TABLE AS SELECT (CTAS) är en av de viktigaste T-SQL-funktionerna som finns. Det är en helt parallelliserad operation som skapar en ny tabell baserat på utdata från ett SELECT-uttalande. CTAS är det enklaste och snabbaste sättet att skapa en kopia av en tabell.
Till exempel, använd CTAS i Warehouse i Microsoft Fabric för att:
- Skapa en kopia av en tabell med några av kolumnerna i källtabellen.
- Skapa en tabell som är resultatet av en fråga som ansluter till andra tabeller.
För mer information om hur man använder CTAS på ditt lager i Microsoft Fabric, se Inmata data i ditt lager med Transact-SQL.
Anmärkning
Eftersom CREATE TABLE AS SELECT (CTAS) ökar möjligheterna att skapa en tabell försöker detta ämne undvika att upprepa ämnet SKAPA TABELL. Istället beskriver den skillnaderna mellan CTAS och CREATE TABLE.
![]() Transact-SQL syntaxkonventioner
Transact-SQL syntaxkonventioner
Syntax
CREATE TABLE { warehouse_name.schema_name.table_name | schema_name.table_name | table_name } (
) WITH (CLUSTER BY [ ,... n ])
AS <select_statement>
[;]
<select_statement> ::=
SELECT select_criteria
Arguments
För detaljer om vanliga argument, se Argument i CREATE TABLE for Microsoft Fabric.
MED (KLUSTER MED [ ,... n])
Klausulen CLUSTER BY för dataklustring i Fabric Data Warehouse kräver att minst en kolumn anges för dataklustring och maximalt fyra kolumner.
För mer information, se Dataklustring i Fabric Data Warehouse.
SELECT-instruktion
Påståendet SELECT är den grundläggande skillnaden mellan CTAS och CREATE TABLE.
VÄLJ select_criteria
Fyller i den nya tabellen med resultaten från ett SELECT uttalande.
select_criteria är själva delen av satsen SELECT som avgör vilken data som ska kopieras till den nya tabellen. För information om SELECT påståenden, se SELECT (Transact-SQL).
Anmärkning
I Microsoft Fabric är användning av variabler i CTAS inte tillåten.
Permissions
CTAS kräver SELECT tillstånd för alla objekt som refereras i select_criteria.
För behörigheter att skapa en tabell, se Behörigheter i CREATE TABLE.
Anmärkningar
För detaljer, se Allmänna anmärkningar i CREATE TABLE.
Begränsningar och restriktioner
SET ROWCOUNT (Transact-SQL) har ingen effekt på CTAS. Använd TOP (Transact-SQL)för att uppnå ett liknande beteende.
För detaljer, se Begränsningar och restriktioner i CREATE TABLE.
Låsningsbeteende
För detaljer, se Låsbeteende i CREATE TABLE.
Exempel för att kopiera en tabell
För mer information om hur man använder CTAS på ditt lager i Microsoft Fabric, se Inmata data i ditt lager med Transact-SQL.
A. Använd CTAS för att ändra kolumnattribut
Detta exempel använder CTAS för att ändra datatyper och nullbarhet för flera kolumner i tabellen DimCustomer2 .
-- Original table
CREATE TABLE [dbo].[DimCustomer2] (
[CustomerKey] INT NOT NULL,
[GeographyKey] INT NULL,
[CustomerAlternateKey] VARCHAR(15)NOT NULL
)
-- CTAS example to change data types and nullability of columns
CREATE TABLE test
AS
SELECT
CustomerKey AS CustomerKeyNoChange,
CustomerKey*1 AS CustomerKeyChangeNullable,
CAST(CustomerKey AS DECIMAL(10,2)) AS CustomerKeyChangeDataTypeNullable,
ISNULL(CAST(CustomerKey AS DECIMAL(10,2)),0) AS CustomerKeyChangeDataTypeNotNullable,
GeographyKey AS GeographyKeyNoChange,
ISNULL(GeographyKey,0) AS GeographyKeyChangeNotNullable,
CustomerAlternateKey AS CustomerAlternateKeyNoChange,
CASE WHEN CustomerAlternateKey = CustomerAlternateKey
THEN CustomerAlternateKey END AS CustomerAlternateKeyNullable,
FROM [dbo].[DimCustomer2]
-- Resulting table
CREATE TABLE [dbo].[test] (
[CustomerKeyNoChange] INT NOT NULL,
[CustomerKeyChangeNullable] INT NULL,
[CustomerKeyChangeDataTypeNullable] DECIMAL(10, 2) NULL,
[CustomerKeyChangeDataTypeNotNullable] DECIMAL(10, 2) NOT NULL,
[GeographyKeyNoChange] INT NULL,
[GeographyKeyChangeNotNullable] INT NOT NULL,
[CustomerAlternateKeyNoChange] VARCHAR(15) NOT NULL,
[CustomerAlternateKeyNullable] VARCHAR(15) NULL,
NOT NULL
)
B. Använd CTAS för att skapa en tabell med färre kolumner
Följande exempel skapar en tabell som heter myTable (c, ln). Den nya tabellen har bara två kolumner. Den använder kolumnaliasen i SELECT-satsen för kolumnnamnen.
CREATE TABLE myTable
AS SELECT CustomerKey AS c, LastName AS ln
FROM dimCustomer;
C. Använd CTAS istället för SELECT.. IN
SQL Server-kod använder vanligtvis SELECT.. INTO för att fylla en tabell med resultaten från ett SELECT-uttalande. Detta är ett exempel på en SQL Server SELECT.. IN-uttalandet.
SELECT *
INTO NewFactTable
FROM [dbo].[FactInternetSales]
Detta exempel visar hur man skriver om föregående SELECT.. INTO-uttalande som ett CTAS-uttalande.
CREATE TABLE NewFactTable
AS
SELECT *
FROM [dbo].[FactInternetSales]
;
D. Använd CTAS för att förenkla sammanslagningssatser
Merge-satser kan ersättas, åtminstone delvis, genom att använda CTAS. Du kan slå ihop och INSERT till UPDATE ett enda uttalande. Alla raderade poster måste stängas i ett andra uttalande.
Ett exempel på en UPSERT följer:
CREATE TABLE dbo.[DimProduct_upsert]
AS
-- New rows and new versions of rows
SELECT s.[ProductKey]
, s.[EnglishProductName]
, s.[Color]
FROM dbo.[stg_DimProduct] AS s
UNION ALL
-- Keep rows that are not being touched
SELECT p.[ProductKey]
, p.[EnglishProductName]
, p.[Color]
FROM dbo.[DimProduct] AS p
WHERE NOT EXISTS
( SELECT *
FROM [dbo].[stg_DimProduct] s
WHERE s.[ProductKey] = p.[ProductKey]
)
;
D. Skapa en tabell med dataklustring
Använd följande kommando för att skapa en ny tabell med CREATE TABLE AS SELECT (CTAS) med en specificerad kolumn för dataklustring:
CREATE TABLE nyctlc_With_DataClustering
WITH (CLUSTER BY (lpepPickupDatetime))
AS SELECT * FROM nyctlc;
För mer information, se Dataklustring i Fabric Data Warehouse.