Förstå hur du jordar din språkmodell
Språkmodeller utmärker sig för att generera engagerande text och är idealiska som bas för agenter. Agenter ger användarna ett intuitivt chattbaserat program för att få hjälp i sitt arbete. När du utformar en agent för ett specifikt användningsfall vill du se till att din språkmodell är grundad och använder faktainformation som är relevant för vad användaren behöver.
Även om språkmodeller tränas på en stor mängd data kanske de inte har åtkomst till den kunskap som du vill göra tillgängliga för dina användare. För att säkerställa att en agent baseras på specifika data för att tillhandahålla korrekta och domänspecifika svar kan du använda RAG (Retrieval Augmented Generation).
Förstå RAG
RAG är en teknik som du kan använda för att grunda en språkmodell. Med andra ord är det en process för att hämta information som är relevant för användarens första prompt. I allmänna termer innehåller RAG-mönstret följande steg:
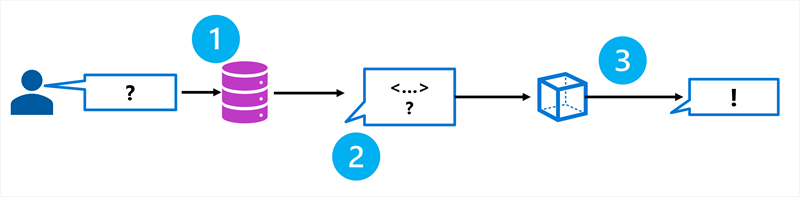
- Hämta jordningsdata baserat på den första användarinmatningsprompten.
- Utöka frågan med grundläggande data.
- Använd en språkmodell för att generera ett jordat svar.
Genom att hämta kontext från en angiven datakälla ser du till att språkmodellen använder relevant information när den svarar, i stället för att förlita sig på träningsdata.
Att använda RAG är en kraftfull och lättanvänd teknik i många fall där du vill grunda din språkmodell och förbättra den faktiska noggrannheten i genativ AI-appens svar.
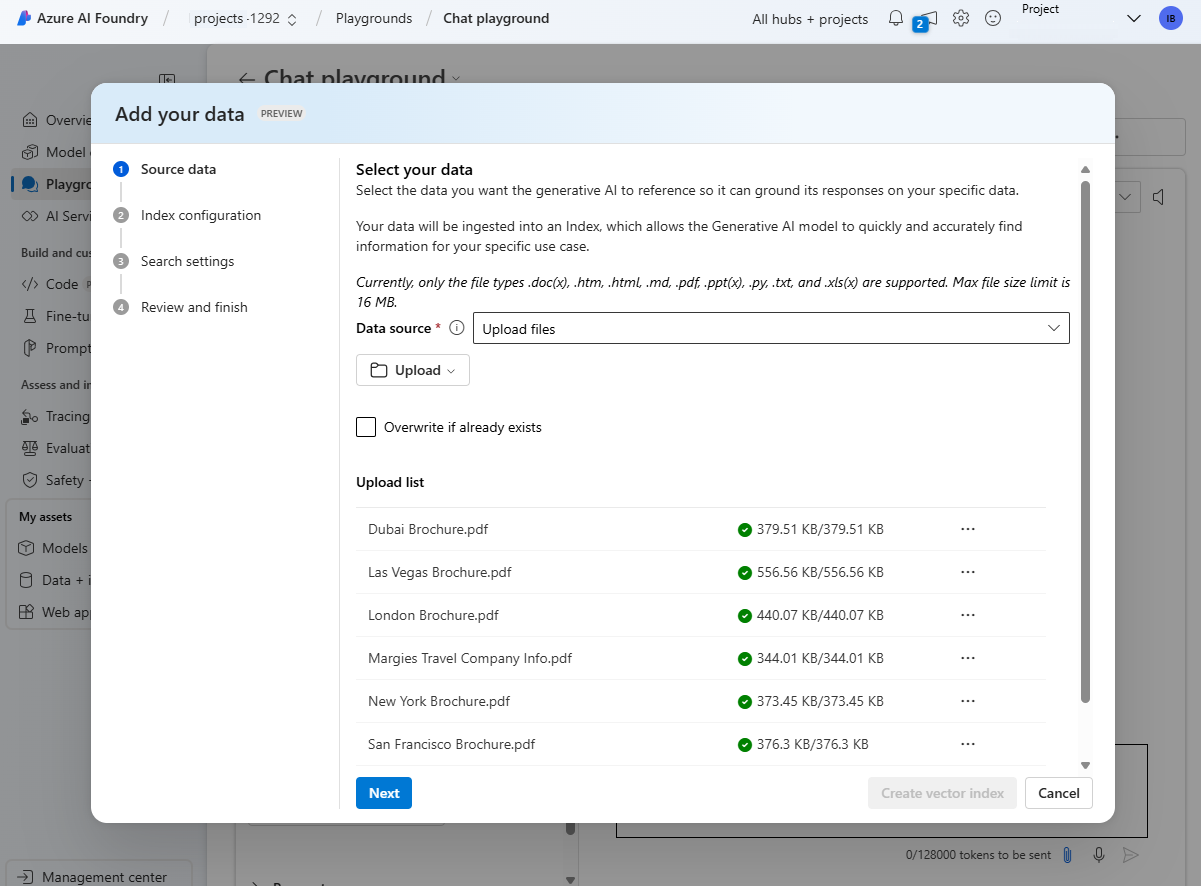
Lägga till grunddata i ett Azure AI-projekt
Du kan använda Microsoft Foundry för att skapa en anpassad agent som använder dina egna data för att skicka frågor. Microsoft Foundry stöder ett antal dataanslutningar som du kan använda för att lägga till data i ett projekt, inklusive:
- Azure Blob Storage
- Azure Data Lake Storage Gen2
- Microsoft OneLake
Du kan också ladda upp filer eller mappar till lagringen som används av AI Foundry-projektet.