Automatiserad skalning i molnet
Molnadministratörer kan manuellt skala upp eller ut för att hantera en ökad efterfrågan och in eller ned för att minska kostnaderna när behovet minskar. En vaksam administratör kan till exempel upptäcka att efterfrågan ökar och använda molntjänstleverantörens verktyg för att starta fler virtuella datorer (skala ut) eller ersätta befintliga virtuella datorer med större datorer som har mer processorkraft och mer minne (skala upp). Nyckelordet är "vaksamt". Om efterfrågan når sin kulmen och ingen känner till det kan systemet som helhet bli långsamt, till och med svarar inte, för slutanvändarna. Och om du skalar upp eller ut för att hantera högre belastningar och glömmer att skala ned igen när belastningen minskar så betalar du för resurser som du inte behöver.
Det är därför som populära molnplattformar erbjuder mekanismer för automatisk skalning så att resurserna kan skalas om enligt en varierande efterfrågan utan mänsklig inblandning. Det finns två huvudsakliga metoder för automatisk skalning:
Tidsbaserad – resurser skalas enligt ett förutbestämt schema. Om din organisations webbplats till exempel upplever den högsta belastningen under arbetstid konfigurerar du automatisk skalning så att resurserna skalas upp eller ut kl. 08:00 varje morgon och skalas ned eller in kl. 17:00 varje eftermiddag. Tidsbaserad skalning kallas ibland för schemalagd skalning.
Måttbaserad – om belastningen är mindre förutsägbar kan du skala om resurser baserat på fördefinierade mått som processoranvändning, minnesbelastning eller genomsnittlig väntetid för förfrågningar. Om den genomsnittliga processoranvändningen når 70 % kan du till exempel automatiskt starta fler virtuella datorer, och när den sjunker till 30 % kan du avetablera de extra virtuella datorerna.
Oavsett om du väljer att skala baserat på tid, mått eller båda så är den automatiska skalningen beroende av skalningsregler eller skalningsprinciper som molnadministratören konfigurerar. Moderna molnplattformar har stöd för skalningsregler som sträcker sig från enkla, till exempel expanderar från två instanser till fyra varje dag klockan 08:00 och återgår till två instanser kl. 17:00, till komplexa – öka till exempel antalet virtuella datorer med en om den maximala CPU-användningen överskrider 70 % eller om den genomsnittliga väntetiden för begäran når 5 sekunder. Molnadministratören måste ofta experimentera en del för att hitta rätt kombination av regler.
Alla större molntjänstleverantörer som Amazon, Microsoft och Google har stöd för automatisk skalning. AWS Auto Scaling kan användas för EC2-instanser, DynamoDB-tabeller och en del andra AWS-molntjänster. Azure har alternativ för automatisk skalning för viktiga tjänster som App Service och Virtual Machines. Google gör samma sak för Google Compute Engine och Google App Engine.
I allmänhet skalar automatiska skalningstjänster in och ut snarare än upp och ned, bland annat eftersom skalning upp och ned innebär att byta en instans mot en annan vilket oundvikligen ger en del nedtid när den nya instansen skapas och tas online.
Tidsbaserad automatisk skalning
Tidsbaserad automatisk skalning passar när belastningen varierar på ett förutsägbart sätt. Många organisationers IT-system har till exempel den högsta belastningen under arbetstid och lite eller ingen belastning under de tidiga morgontimmarna. Domino's Pizzas webbplats kan uppleva belastningar dygnets alla timmar eftersom den driver mer än 16 000 butiker i nästan 100 länder/regioner. Dock ökar belastningen förutsägbart under vissa tider på året.
I båda de här fallen går det att använda tidsbaserad automatisk skalning. I bild 7 ser du hur schemalagd automatisk skalning fungerar i Azure. I det här exemplet konfigurerar en molnadministratör en Azure App Service som är värd för organisationens webbplats för att köra två instanser som standard, men skalar upp till fyra instanser mellan 06:00 och 18:00 sex dagar i veckan exklusive söndag. Genom att välja alternativet ”Ange start-/slutdatum” i stället kan administratören lika enkelt konfigurera App Service att skala ut till 10 instanser under melodifestivalen. Hon kan också definiera flera skalningsvillkor för att skala ut under andra datum också.
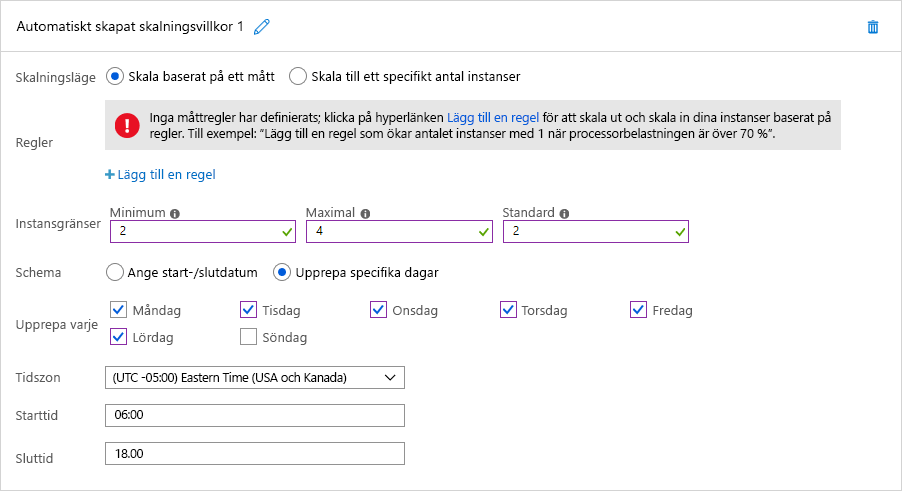
Bild 7: Schemalagd automatisk skalning i Azure.
Måttbaserad automatisk skalning
En skalning som baseras på mått som processoranvändning och genomsnittlig väntetid för förfrågningar passar bra när belastningen är mindre förutsägbar. Det är viktigt med övervakning när det gäller automatisk skalning av resurser baserat på prestandamått eftersom den anger när resurserna ska skalas om. Via övervakning kan du analysera trafikmönster och resursutnyttjande så att du kan bedöma när och hur mycket du behöver skala om resurserna för att maximera tjänstkvaliteten till lägsta möjliga kostnad.
Du kan övervaka flera aspekter hos dina resurser och använda dem till att utlösa skalning. Det vanligaste måttet är resursutnyttjande. En övervakningstjänst kan till exempel spåra processoranvändningen för varje resursnod och skala om resurserna om användningen är för hög eller för låg. Om användningen för varje resurs till exempel är högre än 90 % är det förmodligen bra att lägga till fler resurser, eftersom systemet är hårt belastat. Tjänsteleverantörer fastställer vanligtvis dessa utlösare genom att analysera resursnodernas brytpunkt, när de börjar haverera, och kartlägga deras beteende vid olika belastningsnivåer. Även om det är viktigt att maximera användningsgraden för varje resurs av kostnadsskäl så bör du lämna lite utrymme så att operativsystemet kan hantera extraaktiviteter. Om användningen å andra sidan understiger till exempel 30 % så kanske inte alla resursnoder behövs, och då kan du avetablera några.
I praktiken övervakar tjänstleverantörer oftast en kombination av flera olika mått för en resursnod så att de kan utvärdera när resurser bör skalas om. Några sådana mått är processoranvändning, minnesförbrukning, dataflöde och svarstider. AWS använder CloudWatch till att övervaka EC2-resurser och tillhandahålla skalningsmått (bild 8). CloudWatch spårar mått för alla EC2-instanser i en skalningsgrupp och genererar ett larm när ett visst mått korsar ett tröskelvärde, till exempel när processoranvändningen överskrider 70 %. AWS ökar eller minskar då antalet EC2-instanser baserat på de skalningsprinciper som administratören har konfigurerat.
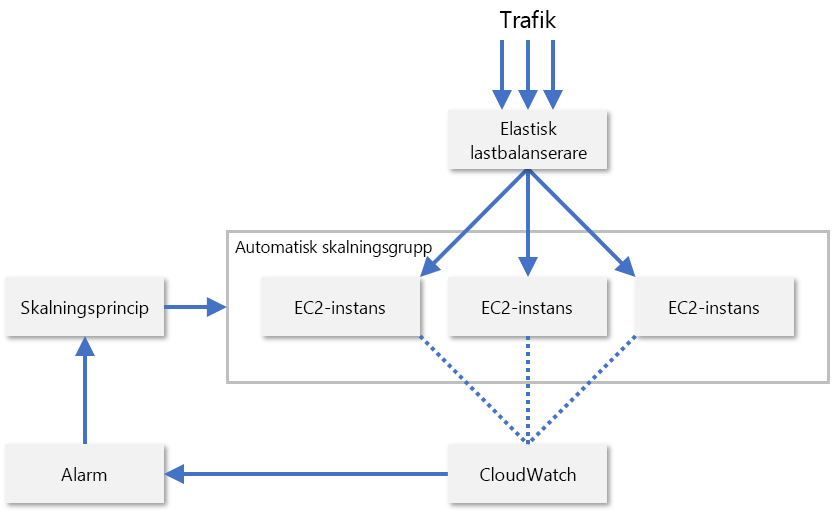
Bild 8: Automatisk skalning av EC2-instanser i AWS.
AWS har också stöd för prediktiv skalning, där maskininlärning används till att förutse trafikmönster och hantera antalet instanser i enlighet med detta. Målet är att skala om molnresurserna smart utan att någon administratör ska behöva konfigurera regler för automatisk skalning. De största molntjänstleverantörerna hittar hela tiden nya sätt att förbättra sina plattformar med maskininlärning. Microsoft använder till exempel nu maskininlärning till att förbättra återhämtningen för virtuella Azure-datorer genom att förutse och åtgärda VM-fel prediktivt1.
Referenser
- Microsoft (2018). Förbättra azure virtual machine-återhämtning med förutsägande ML och direktmigrering. https://azure.microsoft.com/blog/improving-azure-virtual-machine-resiliency-with-predictive-ml-and-live-migration/.