Belastningsutjämning
Att skala ut genom att aktivera nya virtuella datorer när trafiken ökar är en effektiv strategi för att skala om efter efterfrågan. Något som är viktigt för elasticiteten är att virtuella datorer kan etableras så snabbt. Men du tjänar ingenting på att lägga till ytterligare servrar om inte trafiken är jämnt fördelad mellan servrarna. Det här hjälper systemet att hantera den ökade belastningen totalt sett. Det är därför det är lika viktigt med belastningsutjämning eftersom det kan justera den mängd resurser som används för en viss aktivitet dynamiskt.
Behovet av belastningsutjämning beror på två grundläggande saker. Den första är att dataflödet förbättrats vid parallell bearbetning. Om en enda server kan hantera 5 000 förfrågningar per tidsenhet så kan 10 perfekt belastningsutjämnade servrar hantera 50 000 förfrågningar per tidsenhet. Den andra är att belastningsutjämnade resurser ger högre tillgänglighet. I stället för att vidarebefordra en förfrågan till en server som redan kämpar med att hålla jämna steg så kan en belastningsutjämnare skicka förfrågan till en server med lägre belastning. Om en server går ned och lastbalanseraren upptäcker det, kan den dessutom skicka förfrågningar till andra servrar.
Vad är belastningsutjämning?
En välkänd form av belastningsutjämning är resursallokerings-DNS, som många stora webbtjänster använder till att fördela förfrågningar mellan flera servrar. I synnerhet gäller det här i situationer där flera klientdelsservrar har en unik IP-adress men delar samma DNS-namn. Stora företag som Google fördelar antalet förfrågningar till respektive server genom att underhålla en pool med IP-adresser för varje DNS-post. När en klient gör en begäran (till exempel för att www.google.com) väljer Googles DNS en av de tillgängliga adresserna från poolen och skickar den till klienten. Den enklaste strategin för att skicka till olika IP-adresser är att använda en round-robin-kö, där listan med adresser permuteras efter varje DNS-svar.
Innan molnet var DNS-belastningsutjämning ett enkelt sätt att minska svarstiden för anslutningar över stora avstånd. Fördelningsfunktionen på DNS-servern var programmerad att svara med IP-adressen till servern som geografiskt låg närmast klienten. Det enklaste sättet att göra detta var att svara med IP-adressen från poolen som numeriskt låg närmast klientens IP-adress. Den här metoden var inte så tillförlitlig eftersom IP-adresser inte är distribuerade i någon global hierarki. Dagens tekniker är mer sofistikerade och förlitar sig på programvarumappning av IP-adresser till platser baserat på fysiska kartor med internetleverantörer. Eftersom mappningen implementeras som en kostsam programvarusökning ger den här metoden bättre resultat, men är dyr att köra. Kostnaden för en långsam sökning periodiseras dock eftersom DNS-sökningen bara sker när klienten först ansluter till en server. All efterföljande kommunikation sker direkt mellan klienten och servern som äger den IP-adress som används. Du ser ett exempel på DNS-belastningsutjämning i bild 9.
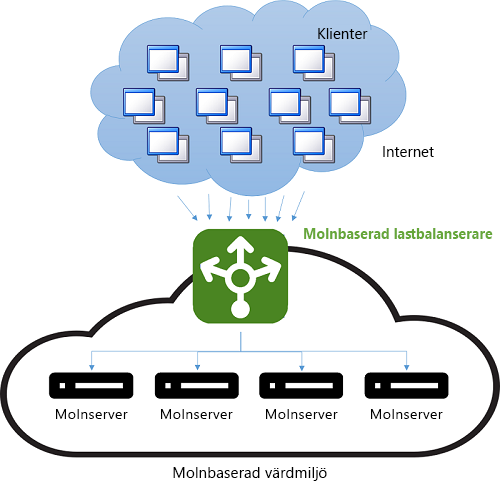
Bild 9: Belastningsutjämning i en molnmiljö.
Nackdelen med den här metoden är att växlingen till en annan IP-adress vid ett serverhaveri är beroende av TTL-konfigurationen (Time-to-Live) för DNS-cachen. DNS-poster varar generellt länge och det tar i allmänhet över en vecka att sprida uppdateringar. Det innebär att det är svårt att snabbt ”dölja” ett serverhaveri för klienten. Om du minskar giltighetstiden (TTL) för en IP-adress i cacheminnet blir problemet mindre, på bekostnad av prestanda och ett större antal sökningar.
Modern belastningsutjämning handlar ofta om att använda en dedikerad instans (eller ett instanspar) till att skicka inkommande förfrågningar till serverdelen. För varje inkommande förfrågan över en viss port dirigerar lastbalanseraren om trafiken till en av servrarna i serverdelen baserat på en fördelningsstrategi. Lastbalanseraren behåller även metadata för förfrågan, som protokollrubriker (till exempel HTTP-rubriker). I den här situationen är det inte något problem med föråldrad information eftersom varje förfrågan passerar lastbalanseraren.
Även om alla typer av lastbalanserare i nätverk vidarebefordrar förfrågningar tillsammans med en kontext till serverdelen så kan de bara använda en av två grundläggande strategier1 när det gäller att skicka svaret tillbaka till klienten:
Via proxy – i den här metoden tar lastbalanseraren emot svaret från serverdelen och skickar det vidare till klienten. Lastbalanseraren fungerar som en vanlig webbproxy och ingår i båda halvorna av nätverkstransaktionen, nämligen att vidarebefordra förfrågan från klienten och att skicka tillbaka svaret.
TCP-leverans – i den här metoden skickas TCP-anslutningen till klienten vidare till servern i serverdelen så att servern skickar svaret direkt till klienten, utan att gå via lastbalanseraren.
Du ser den senare strategin i bild 10.
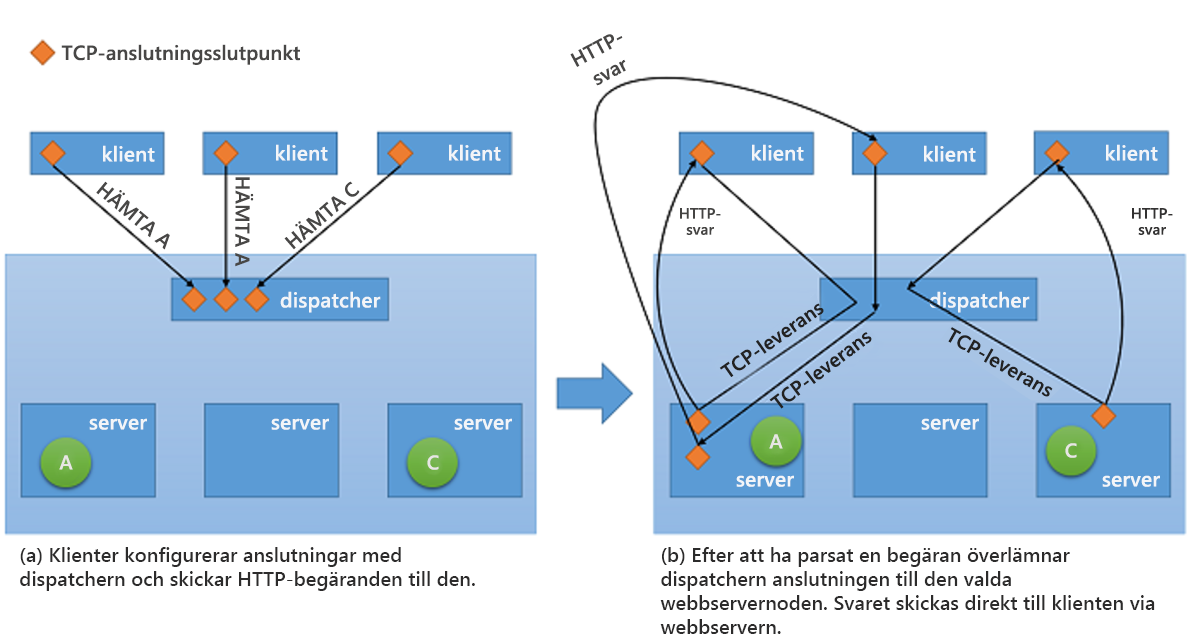
Bild 10: TCP Handoff-mekanism från avsändaren till serverdelsservern.
Fördelar med belastningsutjämning
En av fördelarna med belastningsutjämning är att felen i ett system döljs. Så länge klienten exponeras för en enda slutpunkt som representerar flera resurser så döljs fel hos enskilda resurser från klienten genom att andra resurser bearbetar förfrågan. Nu blir däremot lastbalanseraren en enskild felpunkt. Om den havererar av någon anledning så bearbetas inga klientförfrågningar, även om alla servrar i serverdelen fortfarande fungerar. För att få hög tillgänglighet implementeras lastbalanserare därför ofta i par.
Ännu viktigare är att belastningsutjämning förbättrar svarstiderna genom att arbetsbelastningar fördelas mellan fler beräkningsresurser i molnet. Att ha en enda beräkningsinstans i molnet medför flera begränsningar. I tidigare moduler har vi diskuterat fysiska prestandabegränsningar, där det behövs fler resurser för att klara större arbetsbelastningar. När belastningsutjämning används så fördelas större arbetsbelastningar mellan flera resurser så att varje resurs kan bearbeta sina förfrågningar oberoende och parallellt, vilket förbättrar dataflödet i programmet. Belastningsutjämning förbättrar också den genomsnittliga svarstiden eftersom det finns fler servrar som hanterar arbetsbelastningen.
Det är viktigt med hälsokontroller i implementeringen av en lyckad strategi för belastningsutjämning. En lastbalanserare behöver veta när en resurs slutar vara tillgänglig så att den kan undvika att vidarebefordra trafik till resursen. Övervakning med pingekon, där lastbalanseraren ”pingar” servrar med ICMP-förfrågningar (Internet Control Message Protocol), är en av de populäraste taktikerna som används för att kontrollera resursers hälsotillstånd. Förutom att ta hänsyn till hälsotillståndet för en resurs när trafik ska vidarebefordras så används även andra mått i en del strategier, som dataflöden, svarstider och processoranvändning.
Lastbalanserare måste ofta garantera hög tillgänglighet. Det enklaste sättet att göra detta är att skapa flera instanser av lastbalanseraren (var och en med en unik IP-adress) och koppla dem till samma DNS-adress. Varje gång en belastningsutjämnare havererar av någon anledning ersätts den med en ny, och all trafik skickas vidare till reservinstansen med minimal påverkan på prestanda. Samtidigt kan en ny lastbalanserarinstans konfigureras för att ersätta den havererade, och DNS-registret måste uppdateras omedelbart.
Förutom att distribuera förfrågningar mellan servrar i serverdelen så har lastbalanserare ofta mekanismer för att minska belastningen på servrarna och förbättra det totala dataflödet. Här är några sådana mekanismer:
SSL-avlastning – HTTPS-anslutningar har större prestandakostnad eftersom trafiken över dem är krypterad. I stället för att hantera alla förfrågningar via SSL (Secure Sockets Layer) kan klientanslutningen till lastbalanseraren göras via SSL, samtidigt som förfrågningar som omdirigeras till varje server görs via okrypterad HTTP. Den här tekniken minskar belastningen på servrarna avsevärt. Dessutom bibehålls säkerheten så länge som omdirigeringarna inte görs över ett öppet nätverk.
TCP-buffring – en strategi för avlastning av klienter med långsamma anslutningar till lastbalanseraren som skickar svar till klienterna.
Cachelagring – i vissa fall kan lastbalanseraren använda en cache för de mest populära förfrågningarna (eller förfrågningar som kan hanteras utan kommunikation med servrarna, som för statiskt innehåll) så att belastningen på servrarna minskar.
Trafikomvandling – en lastbalanserare kan använda den här metoden för att skjuta upp eller prioritera om flödet av paket så att trafiken optimeras för serverkonfigurationen. Det här påverkar tjänstkvaliteten för vissa förfrågningar, men säkerställer samtidigt att den inkommande belastningen kan hanteras.
Kom dock ihåg att belastningsutjämning bara fungerar om belastningen på själva lastbalanseraren är hanterbar. Annars blir lastbalanseraren själv en flaskhals. Lyckligtvis sker normalt ganska lite bearbetning av förfrågningarna i själva lastbalanseraren, utan istället är det servrarna i serverdelen som utför det faktiska arbetet med att göra förfrågningar till svar.
Rättvis sändning
Flera strategier för belastningsutjämning används i molnet. En av de vanligaste är rättvis sändning, där en enkel round-robin-algoritm används till att fördela trafiken jämnt mellan alla noder. Här beaktas inte utnyttjandet av enskilda resurser i systemet, och inte heller förfrågningarnas körningstid. Syftet med metoden är att se till att alla noder i systemet har uppgifter att utföra, och det är en av de enklaste metoderna att implementera.
AWS använder den här metoden i sitt ELB-erbjudande (Elastic Load Balancer). Med ELB etableras lastbalanserare som fördelar trafiken mellan anslutna EC2-instanser. Lastbalanserarna är i praktiken också EC2-instanser med en tjänst som specifikt dirigerar trafik. När resurserna bakom lastbalanseraren skalas ut uppdateras IP-adresserna för de nya resurserna i lastbalanserarens DNS-register. Processen tar flera minuter att slutföra eftersom det krävs både övervakning och etablering. Den här tidsperioden, väntetiden tills lastbalanseraren kan hantera den högre belastningen, kallas för ”uppvärmning” av lastbalanseraren.
Lastbalanserarna i AWS utför även hälsokontroller av resurserna som är kopplade till arbetsbelastningsfördelningen. Pingekon används till att säkerställa att alla resurser fungerar. ELB-användare kan konfigurera hälsokontrollens parametrar genom att ange fördröjningar och antalet omförsök.
Hash-baserad distribution
Syftet med den här metoden är att alla förfrågningar från samma klient under sessionen skickas till samma server genom att hasha metadata som definierar respektive förfrågan och använda hashen till att välja server. Om hashningen görs på rätt sätt fördelas förfrågningarna relativt jämnt mellan servrarna. En fördel med den här metoden är att den passar bra för sessionsbaserade program, där sessionsdata kan lagras i minnet snarare än att de skrivs ut till ett delat datalager som en databas eller ett Redis-cache. En nackdel är att varje förfrågan måste hashas, vilket ger lite längre svarstider.
I Azure Load Balancer används en hashbaserad mekanism till att fördela belastningar. Den här mekanismen skapar ett hashvärde för varje förfrågan baserat på käll-IP, källport, mål-IP, målport och protokolltyp, så att varje paket under normala förhållanden hamnar hos samma server i serverdelen. Hashfunktionen väljs så att fördelningen av anslutningar till servrarna är slumpmässig.
Andra strategier för belastningsutjämning
Även om en viss server är upptagen med att bearbeta en förfrågan (eller en uppsättning förfrågningar) så vidarebefordrar lastbalanserare med round-robin-metoder eller hashbaserade algoritmer förfrågningar till den ändå. Det finns andra, mer avancerade strategier för att belastningsutjämna mellan flera resurser som även tar hänsyn till kapaciteten. Här är två av de vanligaste måtten för att mäta kapacitet:
Körningstid för förfrågningar – i strategier som baseras på det här måttet används en schemaläggningsalgoritm för prioritering där körningstiden för förfrågningar används till att välja mål för enskilda förfrågningar. Den främsta utmaningen med den här metoden är att mäta körningstiderna korrekt. En lastbalanserare kan gissa körningstider genom att använda (och ständigt uppdatera) en tabell i minnet med tidsskillnaden mellan det att en förfrågan vidarebefordras och att servern svarar.
Resursutnyttjande – i strategier som baseras på det här måttet används processoranvändningen till att balansera fördelningen mellan noder. Lastbalanserare upprätthåller en sorterad lista med resurserna baserat på användningsgraden och skickar varje förfrågan till resursen som har den lägsta belastningen.
Det är viktigt med belastningsutjämning när du ska implementera skalbara molntjänster. Utan ett effektivt sätt att fördela trafiken mellan resurser i serverdelen så vinner du inte alls lika mycket på att kunna skapa resurser när de behövs och avetablera dem när de inte gör det.
Referenser
- Aron, Mohit and Sanders, Darren and Druschel, Peter and Zwaenepoel, Willy (2000). "Skalbar distribution av innehållsmedvetna begäranden på klusterbaserade nätverksservrar." Förfaranden vid den tekniska konferensen usenix för år 2000.