Förstå lakedatabasbegrepp
I en traditionell relationsdatabas består databasschemat av tabeller, vyer och andra objekt. Tabeller i en relationsdatabas definierar de entiteter som data lagras för, till exempel kan en detaljhandelsdatabas innehålla tabeller för produkter, kunder och beställningar. Varje entitet består av en uppsättning attribut som definieras som kolumner i tabellen och varje kolumn har ett namn och en datatyp. Data för tabellerna lagras i databasen och är nära kopplade till tabelldefinitionen. som framtvingar datatyper, nullabilitet, nyckel unikhet och referensintegritet mellan relaterade nycklar. Alla frågor och datamanipuleringar måste utföras via databassystemet.
Det finns inget fast schema i en datasjö. Data lagras i filer som kan vara strukturerade, halvstrukturerade eller ostrukturerade. Program och dataanalytiker kan arbeta direkt med filerna i datasjön med hjälp av de verktyg som de väljer. utan begränsningarna i ett relationsdatabassystem.
En sjödatabas tillhandahåller ett relationsmetadatalager över en eller flera filer i en datasjö. Du kan skapa en lake-databas som innehåller definitioner för tabeller, inklusive kolumnnamn och datatyper samt relationer mellan primär- och sekundärnyckelkolumner. Tabellerna refererar till filer i datasjön, så att du kan använda relationssemantik för att arbeta med data och köra frågor mot dem med hjälp av SQL. Lagringen av datafilerna är dock frikopplad från databasschemat. ger större flexibilitet än vad ett relationsdatabassystem vanligtvis erbjuder.
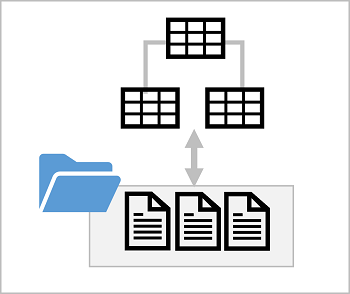
Lake Database-schema
Du kan skapa en lake-databas i Azure Synapse Analytics och definiera de tabeller som representerar de entiteter som du behöver lagra data för. Du kan använda beprövade principer för datamodellering för att skapa relationer mellan tabeller och använda lämpliga namngivningskonventioner för tabeller, kolumner och andra databasobjekt.
Azure Synapse Analytics innehåller ett grafiskt databasdesigngränssnitt som du kan använda för att modellera komplexa databasscheman med hjälp av många av de bästa metoderna för databasdesign som du skulle tillämpa på en traditionell databas.
Lake Database Storage
Data för tabellerna i din lake-databas lagras i datasjön som Parquet- eller CSV-filer. Filerna kan hanteras oberoende av databastabellerna, vilket gör det enklare att hantera datainmatning och manipulering med en mängd olika verktyg och tekniker för databearbetning.
Lake-databaskapacitet
Om du vill köra frågor mot och ändra data via de tabeller som du har definierat kan du använda en Azure Synapse-serverlös SQL-pool för att köra SQL-frågor eller en Azure Synapse Apache Spark-pool för att arbeta med tabellerna med Spark SQL API.