Förstå och testa modellen
Vi har skapat en maskininlärningsmodell! Nu ska vi testa den och ta en titt på hur bra den presterar.
Modellprestanda
Custom Vision visar tre mått när du testar din modell. Mått är indikatorer som kan hjälpa dig att förstå hur din modell fungerar. Indikatorerna anger inte hur faktisk eller korrekt modellen är. Indikatorerna visar bara hur modellen presterade på de data du angav. Hur väl modellen utförs på kända data ger dig en uppfattning om hur modellen kommer att prestera på nya data.
Följande mått tillhandahålls för hela modellen och för varje klass:
| Mätvärde | Beskrivning |
|---|---|
precision |
Om din modell förutsäger en tagg anger det här måttet hur troligt det är att rätt tagg förutsades. |
recall |
Av de taggar som modellen ska förutsäga korrekt anger det här måttet procentandelen taggar som din modell förutsade korrekt. |
average precision |
Mäter modellprestanda genom att beräkna precisionen och återkalla vid olika tröskelvärden. |
När vi testar vår Custom Vision-modell ser vi siffror för vart och ett av dessa mått i iterationstestresultatet.
Vanliga misstag
Innan vi testar vår modell ska vi överväga några av de "nybörjarmisstag" som du bör hålla utkik efter när du börjar skapa maskininlärningsmodeller.
Använda obalanserade data
Du kan se den här varningen när du distribuerar din modell:
Unbalanced data detected. The distribution of images per tag should be uniform to ensure model performance.
Den här varningen anger att du inte har ett jämnt antal exempel för varje dataklass. Även om du har flera alternativ i det här scenariot är ett vanligt sätt att lösa obalanserade data att använda syntetisk översamplingsteknik (SMOTE). SMOTE duplicerar träningsexempel från din befintliga träningspool.
Kommentar
I vår modell kanske du inte ser den här varningen, särskilt om du har laddat upp en bråkdel av datamängden. Datamängden Red-tailed Hawk (Dark morph) innehåller mindre än 60 foton jämfört med de andra modellerna som har mer än 100 foton. Att använda obalanserade data är något att hålla utkik efter i alla maskininlärningsmodeller.
Överanpassning av modellen
Om du inte har tillräckligt med data eller om dina data inte är tillräckligt olika kan din modell bli överanpassad. När en modell är överanpassad känner den till den angivna datamängden väl och den är överanpassad till mönstren i dessa data. I det här fallet fungerar modellen bra på träningsdata, men fungerar dåligt på nya data som den inte har sett tidigare. Därför använder vi alltid nya data för att testa en modell!
Använda träningsdata för att testa
Precis som vid överanpassning, om du testar modellen med samma data som du använde för att träna modellen, verkar modellen fungera bra. Men när du distribuerar modellen till produktion kommer den troligen att fungera dåligt.
Använda felaktiga data
Ett annat vanligt misstag är att använda felaktiga data för att träna modellen. Vissa data kan faktiskt minska modellens noggrannhet. Till exempel kan användning av data som är "bullriga" minska en modells noggrannhet. I brusdata finns för mycket information som inte är användbar i datamängden, och det orsakar förvirring i modellen. Mer data är bara bättre om data är bra data som modellen kan använda. Du kan behöva rensa data eller ta bort funktioner för att förbättra modellens noggrannhet.
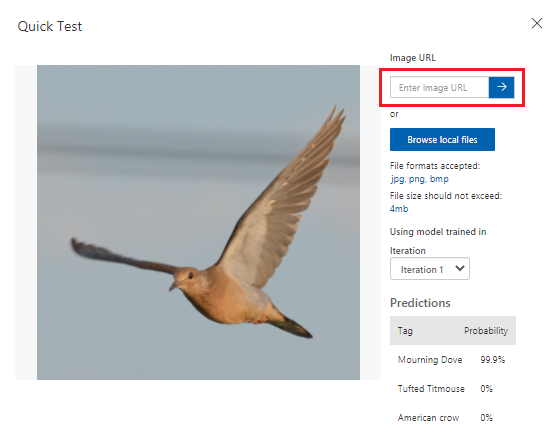
Testa modellen
Enligt de mått som Custom Vision tillhandahåller presterar vår modell på en tillfredsställande nivå. Nu ska vi testa vår modell och se hur den fungerar på nya data. Vi använder en bild av en fågel från en internetsökning.
I webbläsaren söker du efter en bild av en fågel som matchar en av de arter som du har tränat modellen att känna igen. Kopiera URL:en för bilden.
I Custom Vision-portalen väljer du projektet Fågelklassificering.
I den översta menyraden väljer du Snabbtest.
I Snabbtest klistrar du in URL:en i bild-URL:en och trycker sedan på Retur för att testa modellens noggrannhet. Förutsägelsen visas i fönstret.
Custom Vision analyserar bilden för att testa modellens noggrannhet och visar resultatet:
I nästa steg ska vi distribuera modellen. När modellen har distribuerats kan vi göra fler tester med en slutpunkt som vi skapar.