Utforska en IaaS-lösning med hög tillgänglighet och haveriberedskap
Det finns många olika kombinationer av funktioner som kan distribueras i Azure för IaaS. I det här avsnittet beskrivs fem vanliga exempel på HADR-arkitekturer (high availability and disaster recovery) för SQL Server i Azure.
Exempel på hög tillgänglighet för en region 1 – AlwaysOn-tillgänglighetsgrupper
Om du bara behöver hög tillgänglighet och inte haveriberedskap är konfigurering av en tillgänglighetsgrupp en av de mest allestädes närvarande metoderna oavsett var du använder SQL Server. Bilden nedan är ett exempel på hur en möjlig tillgänglighetsgrupp i en enda region kan se ut.
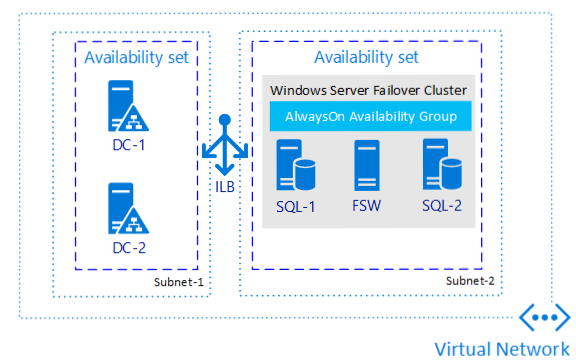
Varför är den här arkitekturen värd att överväga?
Den här arkitekturen skyddar data genom att ha fler än en kopia på olika virtuella datorer (VM).
Med den här arkitekturen kan du uppfylla mål för återställningstid (RTO) och mål för återställningspunkter (RPO) med minimal till ingen dataförlust om det implementeras korrekt.
Den här arkitekturen ger en enkel, standardiserad metod för program att komma åt både primära och sekundära repliker (om saker som skrivskyddade repliker används).
Den här arkitekturen ger förbättrad tillgänglighet under korrigeringsscenarier.
Den här arkitekturen behöver ingen delad lagring, så det är mindre komplikation än när du använder en redundansklusterinstans (FCI).
Exempel 2 – Alltid på redundansklusterinstans för en enskild region med hög tillgänglighet
Fram till dess att AG:er introducerades var FCI:er det populäraste sättet att implementera SQL Server med hög tillgänglighet. FCI:er utformades dock när fysiska distributioner var dominerande. I en virtualiserad värld ger FCI:er inte många av samma skydd på samma sätt som på fysisk maskinvara eftersom det är ovanligt att en virtuell dator har problem. FCI:er har utformats för att skydda mot saker som fel på nätverkskort eller diskfel, som sannolikt inte skulle inträffa i Azure.
Med det sagt har FCI:er en plats i Azure. De fungerar, och så länge du har rätt förväntningar på vad som är och inte tillhandahålls, är en FCI en helt acceptabel lösning. Bilden nedan, från Microsoft-dokumentationen, visar en översikt över hur en FCI-distribution ser ut när du använder Lagringsdirigering.
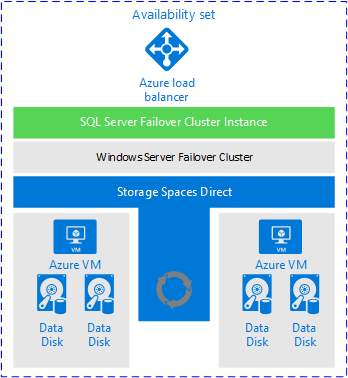
Varför är den här arkitekturen värd att överväga?
FCI:er är fortfarande en populär tillgänglighetslösning.
Berättelsen om delad lagring förbättras med funktioner som Azure Shared Disk.
Den här arkitekturen uppfyller de flesta RTO och RPO för HA (även om DR inte hanteras).
Den här arkitekturen ger en enkel, standardiserad metod för program att komma åt den klustrade instansen av SQL Server.
Den här arkitekturen ger förbättrad tillgänglighet under korrigeringsscenarier.
Haveriberedskapsexempel 1 – Tillgänglighetsgrupp för flera regioner eller Hybrid AlwaysOn
Om du använder AG:er är ett alternativ att konfigurera tillgänglighetsgruppen i flera Azure-regioner eller potentiellt som en hybridarkitektur. Det innebär att alla noder som innehåller replikerna deltar i samma WSFC. Detta förutsätter god nätverksanslutning, särskilt om det här är en hybridkonfiguration. En av de största övervägandena skulle vara vittnesresursen för WSFC. Den här arkitekturen skulle kräva att AD DS och DNS är tillgängliga i alla regioner och potentiellt även lokalt om detta är en hybridlösning. Bilden nedan visar hur en enskild tillgänglighetsgrupp som har konfigurerats på två platser ser ut med hjälp av Windows Server.

Varför är den här arkitekturen värd att överväga?
Den här arkitekturen är en beprövad lösning. Det skiljer sig inte från att ha två datacenter i dag i en tillgänglighetsgruppstopologi.
Den här arkitekturen fungerar med Standard- och Enterprise-utgåvor av SQL Server.
AG:er ger naturligtvis redundans med ytterligare kopior av data.
Den här arkitekturen använder en funktion som ger både HA och D/R
Haveriberedskap exempel 2 – distribuerad tillgänglighetsgrupp
En distribuerad tillgänglighetsgrupp är en enterprise edition-funktion som endast introducerades i SQL Server 2016. Det skiljer sig från en traditionell tillgänglighetsgrupp. I stället för att ha en underliggande WSFC där alla noder innehåller repliker som deltar i en tillgänglighetsgrupp enligt beskrivningen i föregående exempel, består en distribuerad tillgänglighetsgrupp av flera AG:er. Den primära repliken som innehåller lässkrivningsdatabasen kallas global primär. Den primära för den andra tillgänglighetsgruppen kallas vidarebefordrare och håller de sekundära replikerna för den tillgänglighetsgruppen synkroniserade. I grund och botten är detta en ag av AG:er.
Den här arkitekturen gör det lättare att hantera saker som kvorum eftersom varje kluster skulle behålla sitt eget kvorum, vilket innebär att det också har ett eget vittne. En distribuerad tillgänglighetsgrupp fungerar oavsett om du använder Azure för alla resurser eller om du använder en hybridarkitektur.
Bilden nedan visar ett exempel på en distribuerad tillgänglighetsgruppskonfiguration. Det finns två WSFCs. Tänk dig att var och en finns i en annan Azure-region eller att den ena är lokal och den andra finns i Azure. Varje WSFC har en tillgänglighetsgrupp med två repliker. Den globala primära i ag 1 är att hålla den sekundära repliken av AG 1 synkroniserad samt vidarebefordraren, som också är den primära av AG 2. Repliken håller den sekundära repliken av AG 2 synkroniserad.
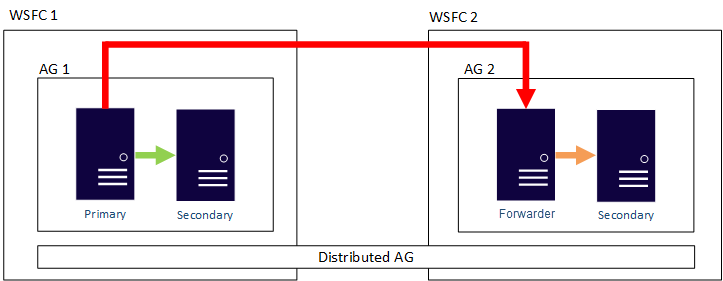
Varför är den här arkitekturen värd att överväga?
Den här arkitekturen separerar WSFC som en felpunkt om alla noder förlorar kommunikationen
I den här arkitekturen synkroniserar en primär inte alla sekundära repliker.
Den här arkitekturen kan ge återställning efter fel från en plats till en annan.
Haveriberedskapsexempel 3 – Loggleverans
Loggleverans är en av de äldsta HADR-metoderna för att konfigurera haveriberedskap för SQL Server. Som beskrivs ovan är måttenheten säkerhetskopieringen av transaktionsloggen. Om du inte planerar att byta till ett varmt vänteläge för att säkerställa att inga data går förlorade, kommer dataförlust troligen att inträffa. När det gäller haveriberedskap är det alltid bäst att anta viss dataförlust även om den är minimal. Bilden nedan, från Microsoft-dokumentationen, visar ett exempel på en loggleveranstopologi.
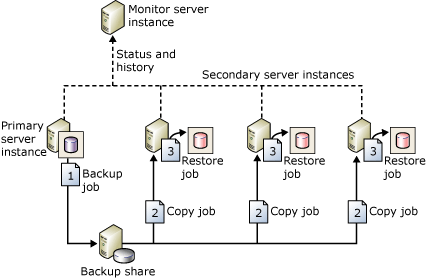
Varför är den här arkitekturen värd att överväga?
Loggleverans är en beprövad funktion som har funnits i över 20 år
Loggleverans är lätt att distribuera och administrera eftersom den baseras på säkerhetskopiering och återställning.
Loggleverans är tolerant mot nätverk som inte är robusta.
Loggleveransen uppfyller de flesta mål för RTO och RPO för dr.
Loggleverans är ett bra sätt att skydda FCI:er.
Haveriberedskapsexempel 4 – Azure Site Recovery
För dem som inte vill implementera en SQL Server-baserad katastroflösning är Azure Site Recovery ett potentiellt alternativ. De flesta dataexperter föredrar dock en databascentrerad metod eftersom den i allmänhet har ett lägre RPO.
Bilden nedan, från Microsoft-dokumentationen. visar var i Azure-portalen du konfigurerar replikering för Azure Site Recovery.
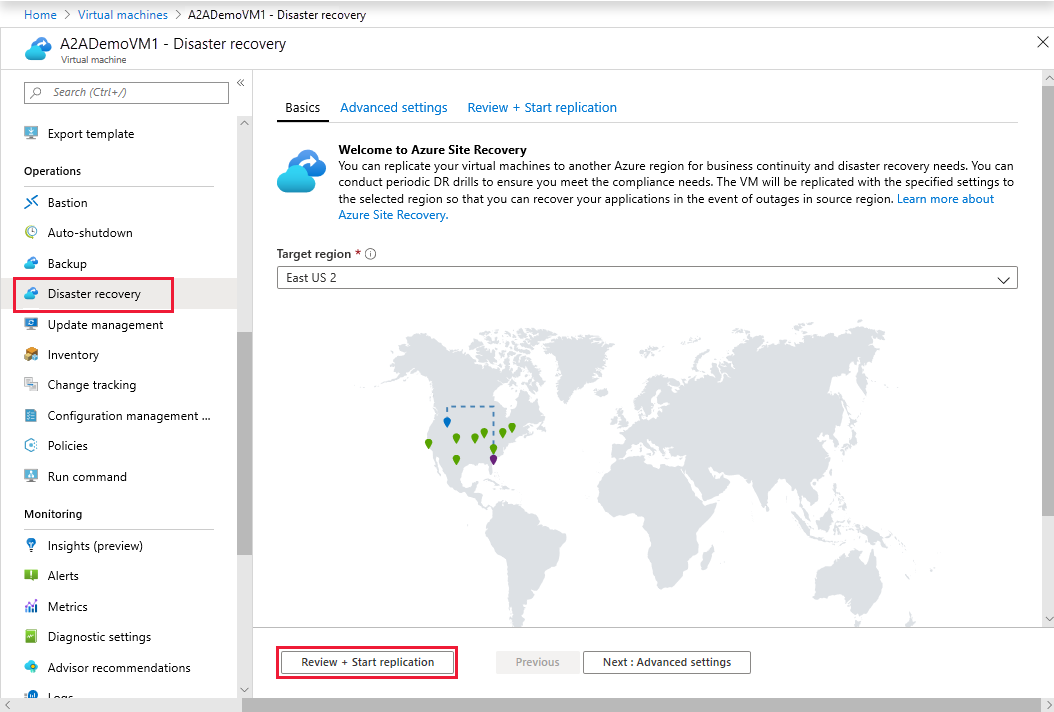
Varför är den här arkitekturen värd att överväga?
Azure Site Recovery fungerar med mer än bara SQL Server.
Azure Site Recovery kan uppfylla RTO och eventuellt RPO.
Azure Site Recovery tillhandahålls som en del av Azure-plattformen.