Designa inmatningsmönster för ett modernt informationslager
Datainmatning kan ske på flera olika sätt. Den primära komponenten i Azure Synapse Analytics för att mata in data är att använda aktiviteten Kopiera data i Azure Synapse Pipelines. Den här typen av aktivitet lagras vanligtvis i en Execute Pipeline-aktivitet med andra funktioner, till exempel en uppslagsåtgärd eller en delningsdataaktivitet.
Du kan också skapa en anslutning inom en Dataflöde som pekar på en källdatabas som används är startpunkten för att mata in data och använda data i ytterligare transformeringsaktiviteter.
Följande visar ett exempel på båda.
Datamatning
Välj integrera hubben.

Expandera Pipelines och välj 1 huvudpipeline (1). Peka på de aktiviteter (2) som kan läggas till i pipelinen och visa pipelinearbetsytan (3) till höger.

Vår Synapse-arbetsyta innehåller 16 pipelines som gör att vi kan samordna dataflytt och transformeringssteg över data från flera källor.
Listan Aktiviteter innehåller ett stort antal aktiviteter som du kan dra och släppa till pipelinearbetsytan till höger.
Här ser vi att vi har tre körningspipelines (underordnade) :

Välj aktiviteten Kör Anpassa alla pipeline (1). Välj fliken Inställningar (2 ). Visa att den anropade pipelinen är Anpassa alla (3) och välj sedan Öppna (4)..

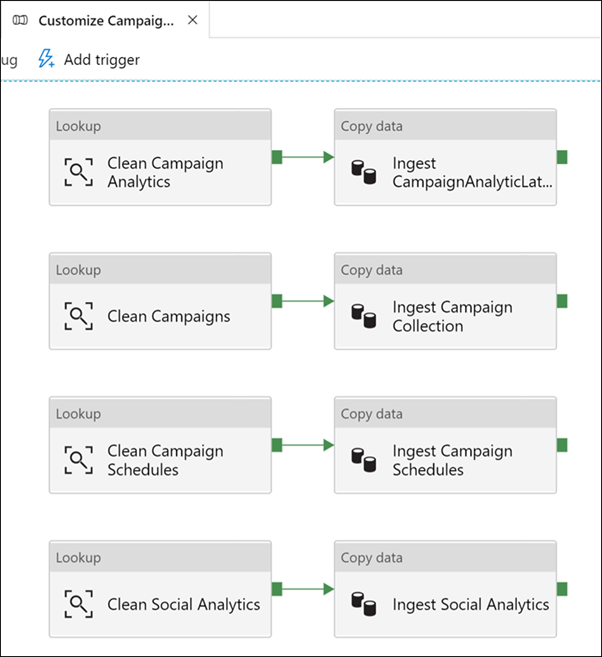
Som du ser finns det fem underordnade pipelines. Den här kör först pipelineaktiviteten rensar och matar in nya kampanjdata för tillverkare för campaign analytics-rapporten.
Välj kampanjanalysaktiviteten (1), välj fliken Inställningar (2), observera att den anropade pipelinen är inställd på Anpassa alla (3)och välj sedan Öppna (4).

Observera hur rensning och inmatning sker i pipelinen genom att klicka på varje aktivitet.
Välj Utveckla hubb.
Expandera Dataflöden och välj sedan det ingest_data_from_sap_hana_to_azure_synapse dataflödet.

Som tidigare nämnts är dataflöden kraftfulla arbetsflöden för datatransformering som använder kraften i Apache Spark, men som har skapats med hjälp av ett kodfritt GUI. Det arbete du utför i användargränssnittet omvandlas automatiskt till kod som körs av ett hanterat Spark-kluster utan att behöva skriva någon kod eller hantera klustret.
Dataflödet utför följande funktioner:
- Extraherar data från SAP HANA-datakällan (Välj data frånSAPHANA-steget).
- Hämtar endast dessa rader för en upsert-aktivitet, där ShipDate-värdet är större än 2014-01-01 (Välj Last5YearsData-steg).
- Utför datatyptransformeringar på källkolumnerna med hjälp av en härledd kolumnaktivitet (Välj den översta DerivedColumn-aktiviteten).
- I den översta sökvägen för dataflödet väljer vi alla kolumner och läser sedan in data i AggregatedSales_SAPHANANew Synapse-pooltabellen (Välj aktiviteten Selectallcolumns och aktiviteten LoadtoAzureSynapse).
- I den nedre sökvägen för dataflödet väljer vi en delmängd av kolumnerna (Välj aktiviteten SelectRequiredColumns).
- Sedan grupperar vi efter fyra av kolumnerna (Välj aktiviteten TotalSalesByYearMonthDay) och skapar summa- och genomsnittsaggregeringar i kolumnen SalesAmount (välj alternativet Aggregeringar).
- Slutligen läses de aggregerade data in i tabellen AggregatedSales_SAPHANA Synapse-pool (Välj aktiviteten LoadtoSynapse).