Använda en visionskompatibel modell i Microsoft Foundry-portalen
Om du vill hantera frågor som innehåller bilder måste du distribuera en multimodal generativ AI-modell – med andra ord en modell som inte bara stöder textbaserade indata, utan även bildbaserade (och i vissa fall ljudbaserade) indata. Multimodala modeller som är tillgängliga i Microsoft Foundry inkluderar (bland annat):
- Microsoft Phi-4-multimodal-instruct
- OpenAI gpt-4.1
- OpenAI gpt-4.1-mini
Tips/Råd
Mer information om tillgängliga modeller i Microsoft Foundry finns i översiktsartikeln Microsoft Foundry Models i Microsoft Foundry-dokumentationen.
Testa multimodala modeller med bildbaserade prompter
När du har distribuerat en multimodal modell kan du testa den på chattlekplatsen i Microsoft Foundry-portalen.
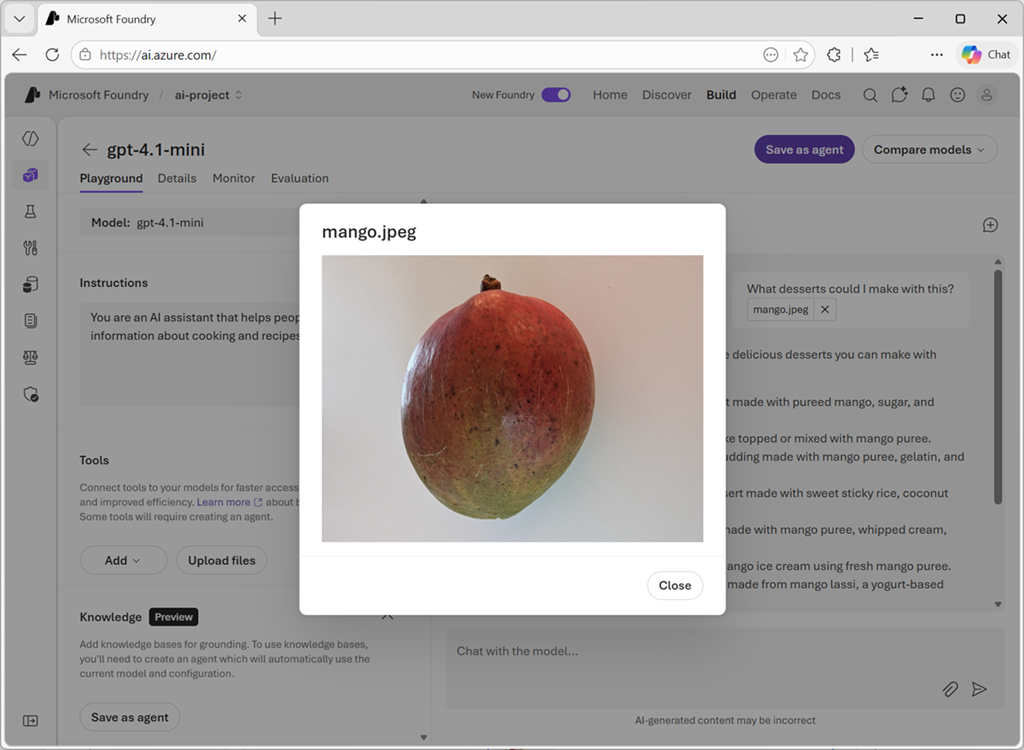
I chattlekplatsen kan du ladda upp en bild från en lokal fil och lägga till text i meddelandet för att få ett svar från en multimodal modell.