Identifiera problematiska frågeplaner
Den typiska metod som DBA använder för att felsöka frågeprestanda är att först identifiera den problematiska frågan, vanligtvis den som förbrukar mest systemresurser och sedan hämta dess körningsplan. Det finns två huvudscenarier. Ett scenario är att frågan konsekvent presterar dåligt. Detta kan bero på olika problem, till exempel maskinvaruresursbegränsningar (även om detta vanligtvis inte påverkar en enskild fråga som körs isolerat), suboptimal frågestruktur, databaskompatibilitetsinställningar, saknade index eller dåliga planval av frågeoptimeraren. Det andra scenariot är att frågan fungerar bra i vissa körningar men dåligt i andra. Den här inkonsekvensen kan orsakas av faktorer som datasnedvridning i en parameteriserad fråga, som har en effektiv plan för vissa körningar och en dålig för andra. Andra vanliga faktorer är blockering, där en fråga väntar på att en annan fråga ska slutföras för att få åtkomst till en tabell eller maskinvarukonkurration.
Nu ska vi utforska vart och ett av dessa scenarier i detalj.
Maskinvarubegränsningar
Maskinvarubegränsningar visas vanligtvis inte under enstaka frågekörningar, men blir uppenbara under produktionsbelastningen när PROCESSORtrådar och minne är begränsade. Cpu-konkurrens kan identifieras genom att observera prestandaövervakarens räknare "% processortid", som mäter serverns CPU-användning. I SQL Server kan SOS_SCHEDULER_YIELD - och CXPACKET-väntetyper indikera CPU-tryck. Dåliga prestanda för lagringssystemet kan göra även optimerade enskilda frågekörningar långsammare. Lagringsprestanda spåras bäst på operativsystemnivå med prestandaövervakarens Disk Seconds/Read räknare och Disk Seconds/Write, som mäter I/O-åtgärdens slutförandetider. SQL Server loggar dåliga lagringsprestanda om en I/O tar längre tid än 15 sekunder. Höga PAGEIOLATCH_SH väntetider i SQL Server kan tyda på problem med lagringsprestanda. Maskinvaruprestanda utvärderas vanligtvis tidigt i felsökningsprocessen på grund av att den är enkel att utvärdera.
De flesta problem med databasprestanda beror på suboptimala frågemönster, vilket kan sätta otillbörlig press på maskinvaran. Till exempel kan saknade index leda till processor-, lagrings- och minnestryck genom att hämta mer data än nödvändigt. Vi rekommenderar att du åtgärdar och finjusterar suboptimala frågor innan du tar itu med maskinvaruproblem. Därefter tittar vi på frågejustering.
Suboptimala frågekonstruktioner
Relationsdatabaser fungerar bäst när du kör uppsättningsbaserade åtgärder, som manipulerar data (INSERT, , UPDATEDELETEoch SELECT) i uppsättningar, vilket ger antingen ett enda värde eller en resultatuppsättning. Alternativet är radbaserad bearbetning, med hjälp av markörer eller while-loopar, som ökar kostnaderna linjärt med antalet rader som påverkas – en problematisk skala när datavolymerna växer.
Det är viktigt att identifiera suboptimal användning av radbaserade åtgärder med markörer eller WHILE-loopar, men det finns andra SQL Server-antimönster att känna igen. Tabellvärdesfunktioner (TVF:er), särskilt TVF:er med flera instruktioner, orsakade problematiska körningsplanmönster före SQL Server 2017. Utvecklare använder ofta TVF:er med flera instruktioner för att köra flera frågor i en enda funktion och aggregera resultat till en enda tabell. Att använda TVF:er kan dock leda till prestandastraff.
SQL Server har två typer av TVF:er: infogade och flera instruktioner. Infogade TVF:er behandlas som vyer, medan TVF:er med flera instruktioner behandlas som tabeller under frågebearbetningen. Eftersom TVF:er är dynamiska och saknar statistik använder SQL Server ett fast radantal för att beräkna kostnaden för frågeplan. Detta kan vara bra för små radantal, men ineffektivt för tusentals eller miljontals rader.
Ett annat antimönster är användningen av skalära funktioner, som har liknande uppskattnings- och körningsproblem. Microsoft har gjort betydande prestandaförbättringar med intelligent frågebearbetning under kompatibilitetsnivåer 140 och 150.
SARGability
Termen SARGable i relationsdatabaser refererar till ett predikat (WHERE -sats) formaterat för att använda ett index för att påskynda frågekörningen. Predikat i rätt format kallas "Sökargument" eller SARG:er. I SQL Server innebär användning av en SARG att optimeraren utvärderar med hjälp av ett icke-grupperat index i kolumnen som refereras i SARG för en SEEK-åtgärd , i stället för att genomsöka hela indexet eller tabellen för att hämta ett värde.
Förekomsten av en SARG garanterar inte användningen av ett index för en SEEK. Optimeringsalgoritmerna för kostnadsberäkning kan fortfarande avgöra att indexet är för dyrt, särskilt om en SARG refererar till en stor procentandel rader i en tabell. Avsaknaden av en SARG innebär att optimeraren inte utvärderar en SEEK på ett icke-grupperat index.
Exempel på icke-SARGable-uttryck är de med en LIKE -sats som använder ett jokertecken i början av strängen, till exempel WHERE lastName LIKE '%SMITH%'. Andra icke-SARGable predikat inträffar när du använder funktioner i en kolumn, till exempel WHERE CONVERT(CHAR(10), CreateDate,121) = '2020-03-22'. Dessa frågor identifieras vanligtvis genom att undersöka körningsplaner för index- eller tabellgenomsökningar där sökningar annars bör ske.
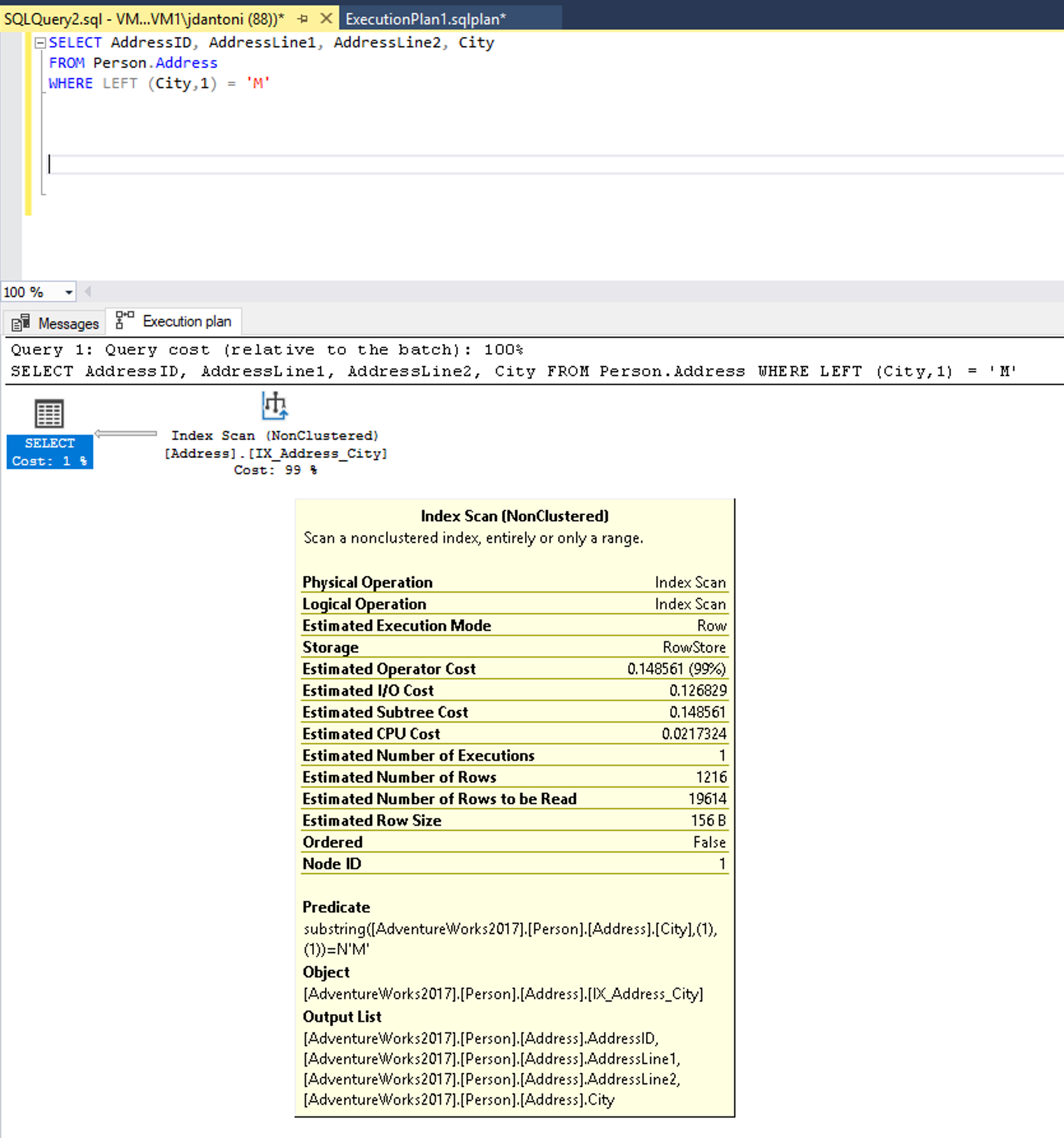
Det finns ett index i kolumnen Stad som används i -satsen i WHERE frågan och medan det används i den här körningsplanen ovan kan du se att indexet genomsöks, vilket innebär att hela indexet läses. Funktionen LEFT i predikatet gör att det här uttrycket inte är SARGable. Optimeraren kommer inte att utvärdera med hjälp av en indexsökning av indexet på kolumnen Ort.
Den här frågan kan skrivas för att använda ett predikat som är SARGable. Optimeraren utvärderar sedan en SEEK på indexet på kolumnen Stad. I det här fallet skulle en indexsökningsoperator läsa en mindre uppsättning rader.
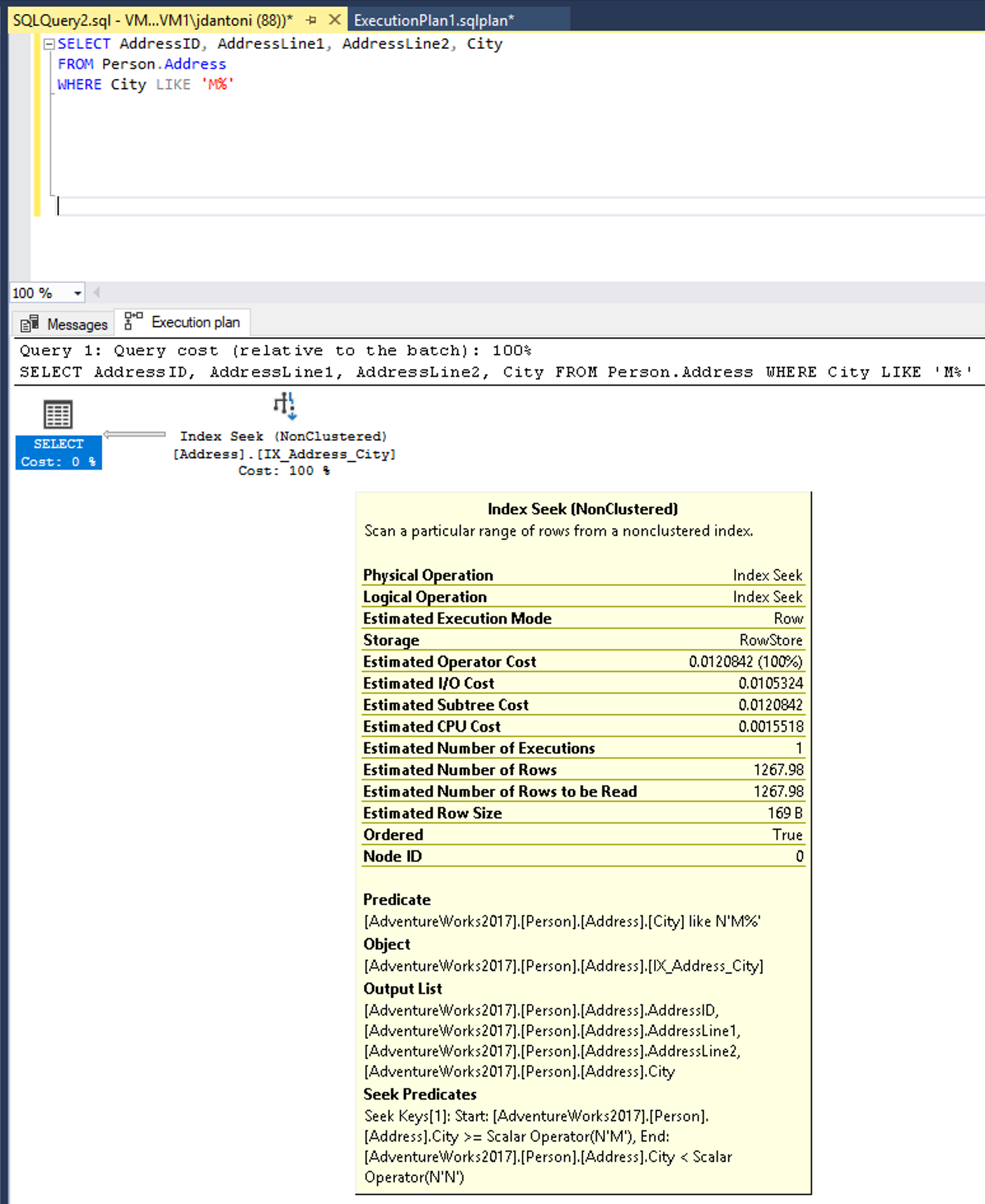
Om du ändrar LEFT funktionen till en LIKE resulterar det i en indexsökning.
Anmärkning
Nyckelordet LIKE i det här exemplet har inte ett jokertecken till vänster, så det letar efter städer som börjar med M. Om det var "tvåsidigt" eller började med ett jokertecken ("%M%" eller "%M") skulle det vara icke-SARGable. Sökåtgärden beräknas returnera 1 267 rader, eller cirka 15% av uppskattningen för frågan med predikatet som inte är SARGable.
Vissa andra skydd mot databasutveckling behandlar databasen som en tjänst i stället för ett datalager. Användning av en databas för att konvertera data till JSON, ändra strängar eller utföra komplexa beräkningar kan leda till överdriven processoranvändning och ökad svarstid. Frågor som försöker hämta alla poster och sedan utföra beräkningar i databasen kan leda till överdriven I/O- och CPU-användning. Helst bör du använda databasen för dataåtkomståtgärder och optimerade databaskonstruktioner som sammansättning.
Index saknas
De vanligaste prestandaproblemen för databasadministratörer beror på brist på användbara index, vilket gör att motorn läser fler sidor än nödvändigt för att returnera frågeresultat. Även om index förbrukar resurser (påverkar skrivprestanda och förbrukar utrymme) uppväger prestandaökningarna ofta de extra resurskostnaderna. Körningsplaner med dessa problem kan identifieras av frågeoperatorn Klustrad indexgenomsökning eller kombinationen av Icke-klustrad indexsök och nyckeluppslag, som indikerar saknade kolumner i ett befintligt index.
Databasmotorn hjälper till genom att rapportera saknade index i körningsplaner. Namn och information om rekommenderade index är tillgängliga via vyn sys.dm_db_missing_index_detailsdynamisk hantering . Andra DMV:er som sys.dm_db_index_usage_stats och sys.dm_db_index_operational_stats markerar användningen av befintliga index.
Det kan vara klokt att ta bort ett oanvänt index. Saknade index-DMV:er och planvarningar bör vara startpunkter för att justera frågor. Det är viktigt att förstå viktiga frågor och skapa index för att stödja dem. Vi rekommenderar inte att du skapar alla saknade index utan att utvärdera dem i kontexten.
Saknad och inaktuell statistik
Det är viktigt att förstå vikten av kolumn- och indexstatistik för frågeoptimeraren. Det är också viktigt att känna igen villkor som kan leda till inaktuell statistik och hur det här problemet kan manifesteras i SQL Server. Azure SQL-erbjudanden har som standard automatisk uppslagsstatistik inställd på PÅ. Före SQL Server 2016 var standardbeteendet för autouppdaterad statistik att inte uppdatera statistiken förrän antalet ändringar av kolumner i indexet motsvarade cirka 20% av antalet rader i en tabell. Det här beteendet kan leda till betydande dataändringar som ändrar frågeprestanda utan att uppdatera statistiken, vilket leder till suboptimala planer baserat på inaktuell statistik.
Före SQL Server 2016 kunde spårningsflagga 2371 användas för att ändra det antal ändringar som krävs till ett dynamiskt värde, så när tabellen växte minskade procentandelen radändringar som behövdes för att utlösa en statistikuppdatering. Nyare versioner av SQL Server, Azure SQL Database och Azure SQL Managed Instance stöder det här beteendet som standard. Funktionen sys.dm_db_stats_properties för dynamisk hantering visar senaste gången statistik uppdaterades och antalet ändringar sedan den senaste uppdateringen, så att du snabbt kan identifiera statistik som kan behöva manuella uppdateringar.
Dåliga val för optimerare
Även om frågeoptimeraren gör ett bra jobb med att optimera de flesta frågor finns det vissa gränsfall där den kostnadsbaserade optimeraren kan fatta beslut som inte är helt förstådda. Det finns många sätt att hantera detta, inklusive att använda frågetips, spårningsflaggor, tvingad körningsplan och andra justeringar för att nå en stabil och optimal frågeplan. Microsoft har ett supportteam som kan hjälpa dig att felsöka dessa scenarier.
I exemplet nedan från databasen AdventureWorks2017 används ett frågetips för att instruera databasoptimeraren att alltid använda ett stadsnamn i Seattle. Det här tipset garanterar inte den bästa körningsplanen för alla stadsvärden, men den är förutsägbar. Värdet för "Seattle" för @city_name används endast under optimeringen. Under körningen används det faktiska angivna värdet (‘Ascheim’) .
DECLARE @city_name nvarchar(30) = 'Ascheim',
@postal_code nvarchar(15) = 86171;
SELECT *
FROM Person.Address
WHERE City = @city_name
AND PostalCode = @postal_code
OPTION (OPTIMIZE FOR (@city_name = 'Seattle');
Som visas i exemplet använder frågeställningen en antydan ( OPTION -satsen) för att instruera optimeraren att använda ett specifikt variabelvärde för att skapa sin exekveringsplan.
Parametersniffning
SQL Server cachelagrar frågekörningsplaner för framtida användning. Eftersom hämtningsprocessen för körningsplanen baseras på hashvärdet för en fråga måste frågetexten vara identisk för varje körning av frågan för att den cachelagrade planen ska användas. För att stödja flera värden i samma fråga använder många utvecklare parametrar som skickas via lagrade procedurer, enligt följande exempel:
CREATE PROC GetAccountID (@Param INT)
AS
<other statements in procedure>
SELECT accountid FROM CustomerSales WHERE sales > @Param;
<other statements in procedure>
RETURN;
-- Call the procedure:
EXEC GetAccountID 42;
Frågor kan också uttryckligen parametriseras med hjälp av proceduren sp_executesql. Explicit parameterisering av enskilda förfrågningar görs dock via programmet med någon form (beroende på API) av PREPARE och EXECUTE. När databasmotorn kör frågan för första gången optimeras frågan baserat på parameterns initiala värde, i det här fallet 42. Det här beteendet, som kallas parametersniffning, gör att den övergripande arbetsbelastningen för kompilering av frågor kan minskas på servern. Men om det finns datasnedvridning kan frågeprestanda variera kraftigt.
En tabell som till exempel hade 10 miljoner poster och 99% av dessa poster har ett ID på 1, och de andra 1% är unika tal, prestanda baseras på vilket ID som ursprungligen användes för att optimera frågan. Den här mycket fluktuerande prestandan tyder på datasnedvridning och är inte ett inneboende problem med parametersniffning. Det här beteendet är ett ganska vanligt prestandaproblem som du bör känna till. Du bör förstå alternativen för att lindra problemet. Det finns några sätt att lösa det här problemet, men var och en har kompromisser:
- Använd tipset
RECOMPILEi din fråga eller körningsalternativetWITH RECOMPILEi dina lagrade procedurer. Det här tipset gör att frågan eller proceduren omkompileras varje gång den körs, vilket ökar CPU-användningen på servern men alltid använder det aktuella parametervärdet. - Du kan använda frågetipset
OPTIMIZE FOR UNKNOWN. Det här tipset gör att optimeraren väljer att inte sniffa parametrar och jämför värdet med kolumndata histogram. Det här alternativet ger dig inte den bästa möjliga planen, men tillåter en konsekvent körningsplan. - Skriv om proceduren eller frågorna genom att lägga till logik kring parametervärden till endast RECOMPILE för kända besvärliga parametrar. I exemplet nedan, om parametern SalesPersonID är NULL, körs frågan med
OPTION (RECOMPILE).
CREATE OR ALTER PROCEDURE GetSalesInfo (@SalesPersonID INT = NULL)
AS
DECLARE @Recompile BIT = 0
, @SQLString NVARCHAR(500)
SELECT @SQLString = N'SELECT SalesOrderId, OrderDate FROM Sales.SalesOrderHeader WHERE SalesPersonID = @SalesPersonID'
IF @SalesPersonID IS NULL
BEGIN
SET @Recompile = 1
END
IF @Recompile = 1
BEGIN
SET @SQLString = @SQLString + N' OPTION(RECOMPILE)'
END
EXEC sp_executesql @SQLString
,N'@SalesPersonID INT'
,@SalesPersonID = @SalesPersonID
GO
Det här exemplet är en bra lösning, men det kräver en ganska stor utveckling och en fast förståelse för din datadistribution. Det kräver underhåll när data ändras.