Förstå normalisering
Normalisering är en term som används av databasproffs för en schemadesignprocess som minimerar dataduplicering och framtvingar dataintegritet.
Det finns många komplexa regler som definierar processen för att omstrukturera data till olika nivåer (eller former) av normalisering, men en enkel definition för praktiska ändamål är:
- Avgränsa varje entitet i en egen tabell.
- Avgränsa varje diskret attribut i sin egen kolumn.
- Identifiera varje entitetsinstans (rad) unikt med hjälp av en primärnyckel.
- Använd sekundärnyckelkolumner för att länka relaterade entiteter.
För att förstå grundprinciperna för normalisering antar vi att följande tabell representerar ett kalkylblad som ett företag använder för att spåra sin försäljning.
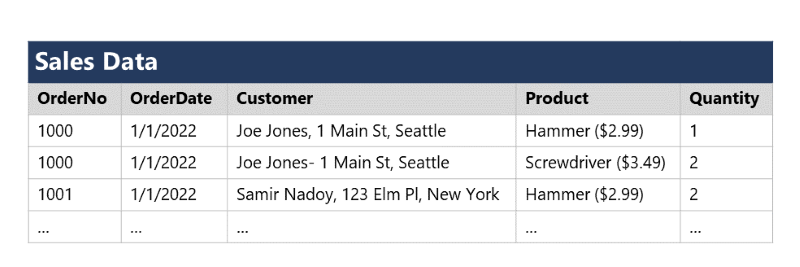
Observera att kund- och produktinformationen dupliceras för varje enskild artikel som säljs. och att kundens namn och postadress samt produktnamnet och priset kombineras i samma kalkylbladsceller.
Nu ska vi titta på hur normaliseringen ändrar hur data lagras.

Varje entitet som representeras i data (kund, produkt, försäljningsorder och radobjekt) lagras i sin egen tabell, och varje diskret attribut för dessa entiteter finns i sin egen kolumn.
Om du registrerar varje instans av en entitet som en rad i en entitetsspecifik tabell tar du bort duplicering av data. Om du till exempel vill ändra en kunds adress behöver du bara ändra värdet på en enda rad.
Nedbrytningen av attribut i enskilda kolumner säkerställer att varje värde begränsas till en lämplig datatyp, till exempel måste produktpriserna vara decimalvärden, medan radartikelkvantiteter måste vara heltalsnummer. Dessutom ger skapandet av enskilda kolumner en användbar detaljnivå i data för frågor, till exempel kan du enkelt filtrera kunder till dem som bor i en viss stad.
Instanser av varje entitet identifieras unikt av ett ID eller annat nyckelvärde, som kallas primärnyckel. och när en entitet refererar till en annan (till exempel en order har en associerad kund) lagras den relaterade entitetens primärnyckel som en sekundärnyckel. Du kan söka efter kundens adress (som endast lagras en gång) för varje post i tabellen Order genom att referera till motsvarande post i tabellen Kund . Vanligtvis kan ett hanteringssystem för relationsdatabaser (RDBMS) framtvinga referensintegritet för att säkerställa att ett värde som anges i ett sekundärnyckelfält har en befintlig motsvarande primärnyckel i den relaterade tabellen , till exempel förhindra beställningar för obefintliga kunder.
I vissa fall kan en nyckel (primär eller sekundär) definieras som en sammansatt nyckel baserat på en unik kombination av flera kolumner. Tabellen LineItem i exemplet ovan använder till exempel en unik kombination av OrderNo och ItemNo för att identifiera ett radobjekt från en enskild ordning.