Beskriva databasobjekt
Förutom tabeller kan en relationsdatabas innehålla andra strukturer som hjälper till att optimera dataorganisationen, kapsla in programmatiska åtgärder och förbättra åtkomsthastigheten. I den här lektionen lär du dig mer om tre av dessa strukturer: vyer, lagrade procedurer och index.
Vad är en vy?
En vy är en virtuell tabell baserat på resultatet av en SELECT-fråga . Du kan se en vy som ett fönster på angivna rader i en eller flera underliggande tabeller. Du kan till exempel skapa en vy över tabellerna Order och Kund som hämtar order- och kunddata för att tillhandahålla ett enda objekt som gör det enkelt att fastställa leveransadresser för beställningar:
CREATE VIEW Deliveries
AS
SELECT o.OrderNo, o.OrderDate,
c.FirstName, c.LastName, c.Address, c.City
FROM Order AS o JOIN Customer AS c
ON o.Customer = c.ID;
Du kan köra frågor mot vyn och filtrera data på ungefär samma sätt som i en tabell. Följande fråga hittar information om beställningar för kunder som bor i Seattle:
SELECT OrderNo, OrderDate, LastName, Address
FROM Deliveries
WHERE City = 'Seattle';
Vad är en lagrad procedur?
En lagrad procedur definierar SQL-instruktioner som kan köras med kommandot . Lagrade procedurer används för att kapsla in programmatisk logik i en databas för åtgärder som program behöver utföra när de arbetar med data.
Du kan definiera en lagrad procedur med parametrar för att skapa en flexibel lösning för vanliga åtgärder som kan behöva tillämpas på data baserat på en specifik nyckel eller ett visst villkor. Följande lagrade procedur kan till exempel definieras för att ändra namnet på en produkt baserat på det angivna produkt-ID:t.
CREATE PROCEDURE RenameProduct
@ProductID INT,
@NewName VARCHAR(20)
AS
UPDATE Product
SET Name = @NewName
WHERE ID = @ProductID;
När en produkt måste byta namn kan du köra den lagrade proceduren och skicka ID:t för produkten och det nya namnet som ska tilldelas:
EXEC RenameProduct 201, 'Spanner';
Vad är ett index?
Ett index hjälper dig att söka efter data i en tabell. Tänk på ett index över en tabell som ett index längst bak i en bok. Ett bokindex innehåller en sorterad uppsättning referenser och ett eller flera sidnummer där referensen förekommer. När du vill hitta en referens till någonting i boken söker du i indexet. Du kan använda sidnumren i indexet för att gå direkt till rätt sidor i boken. Utan indexet kanske du behöver läsa igenom hela boken för att hitta de referenser du letar efter.
När du skapar ett index i en databas anger du en kolumn i tabellen, och indexet innehåller då en sorterad kopia av dessa data med pekare till motsvarande rader i tabellen. När användaren kör en fråga som anger den här kolumnen i WHERE-satsen kan databashanteringssystemet använda det här indexet för att hämta data snabbare än om det var tvunget att söka igenom hela tabellraden efter rad.
Du kan till exempel använda följande kod för att skapa ett index i kolumnen Namn i tabellen Produkt :
CREATE INDEX idx_ProductName
ON Product(Name);
Indexet skapar en trädbaserad struktur som databassystemets frågeoptimerare kan använda för att snabbt hitta rader i tabellen Produkt baserat på ett angivet namn.
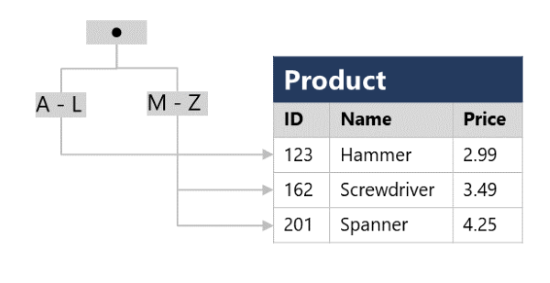
För en tabell som innehåller några rader är det förmodligen inte effektivare att använda indexet än att bara läsa hela tabellen och hitta de rader som begärs av frågan (i så fall ignorerar frågeoptimeraren indexet). Men när en tabell har många rader kan index avsevärt förbättra prestanda för frågor.
Du kan skapa många index för en tabell. Så om du också vill hitta produkter baserat på pris kan det vara användbart att skapa ett annat index på kolumnen Pris i tabellen Produkt . Det är dock inte gratis med index. Ett index förbrukar lagringsutrymme och varje gång du infogar, uppdaterar eller tar bort data i en tabell måste indexen för tabellen underhållas. Det här ytterligare arbetet kan göra åtgärderna infoga, uppdatera och ta bort långsammare. Du måste hitta en balans mellan att ha index som påskyndar dina frågor jämfört med kostnaden för att utföra andra åtgärder.