Övning – Utforska hur Citus distribuerar tabeller
I den här övningen skapar du en Azure Cosmos DB för PostgreSQL-databas med flera noder. Sedan skapar du några tabeller innan du kör några frågor mot databasen för att lära dig mer om den distribuerade arkitekturen som tillhandahålls av Citus-tillägget för PostgreSQL.
Skapa en Azure Cosmos DB för PostgreSQL-databas
För att slutföra den här övningen måste du skapa en Azure Cosmos DB för PostgreSQL-klustret. Klustret kommer att ha:
- En koordinatornod med 4 virtuella kärnor, 16 GiB RAM och 512 GiBM lagring
- Två arbetsnoder, var och en med 4 virtuella kärnor, 32-GiB RAM och 512 GiBM lagring
Gå till Azure-portalen i en webbläsare.
I Azure-portalen väljer du Skapa en resurs, databaser och Azure Cosmos DB. Du kan också använda sökfunktionen för att hitta resursen.
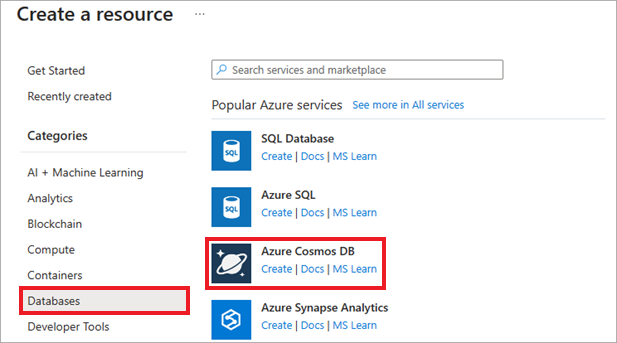
På skärmen Välj API-alternativ väljer du Skapa i panelen Azure Cosmos DB for PostgreSQL.
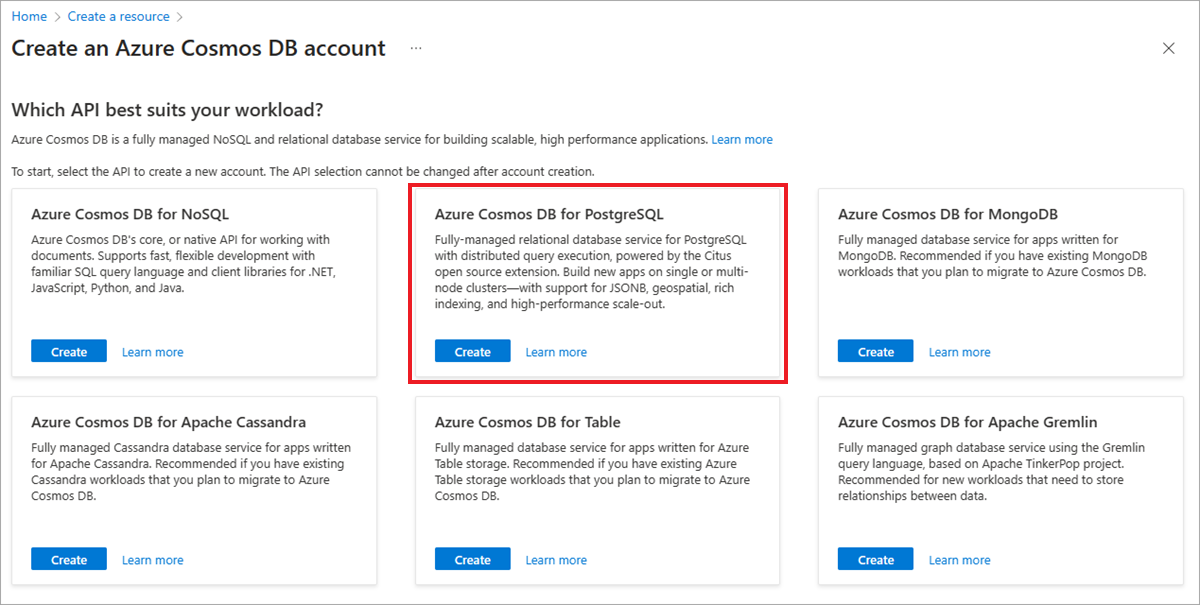
Kommentar
När du har valt Skapa visas en databaskonfigurationsskärm i portalen.
På fliken Grundläggande anger du följande information:
Parameter Värde Projektinformation Prenumeration Välj din Azure-prenumeration. Resursgrupp Välj Skapa ny och ge resursgruppen learn-cosmosdb-postgresqlnamnet .Klusterinformation Klusternamn Ange ett globalt unikt namn, till exempel learn-cosmosdb-postgresql.Location Lämna standardvärdet eller använd en region nära dig. Skala Se konfigurationsinställningar i nästa steg. PostgreSQL-version Låt standardversionen (15) vara markerad. Administratörskonto Användarnamn för administratör Det här användarnamnet är inställt på citusoch kan inte redigeras.Password Ange och bekräfta ett starkt lösenord. 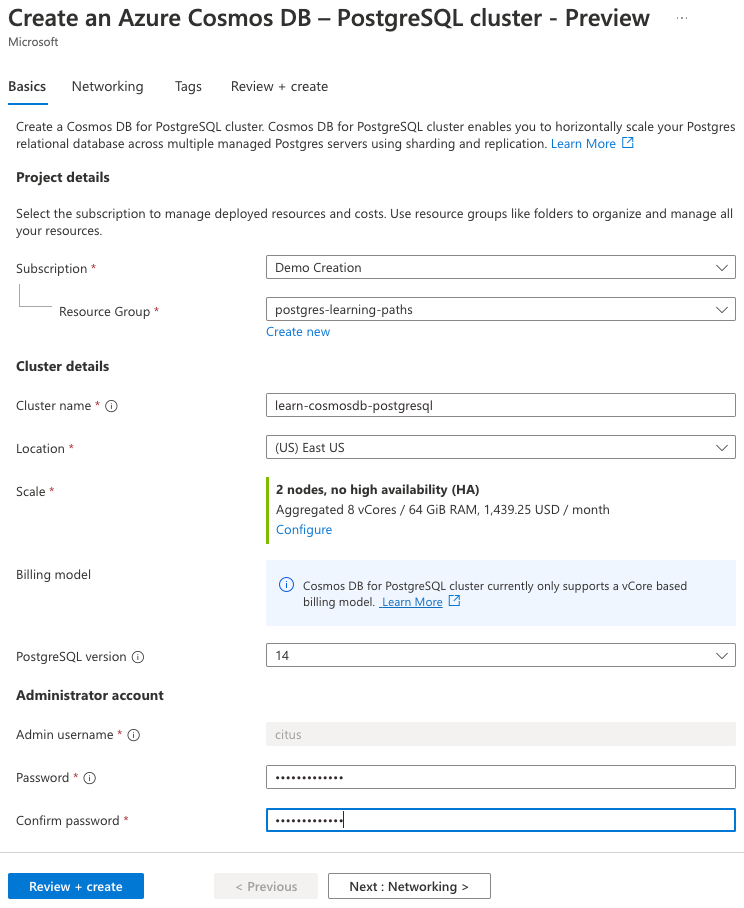
Anteckna lösenordet för senare användning.
För skalningsinställningen väljer du Konfigurera och anger följande på nodkonfigurationssidan:
Parameter Värde Noder Nodantal Välj 2 noder. Beräkning per nod Välj 4 virtuella kärnor, 32 GiB RAM-minne. Lagring per nod Välj 512 GiBM. Samordnare (Du kan behöva expandera det här avsnittet) Koordinatorberäkning Välj 4 virtuella kärnor, 16 GiB RAM-minne. Koordinatorlagring Välj 512 GiBM. Funktionerna för hög tillgänglighet och automatisk redundans ligger utanför omfånget för den här övningen, så låt kryssrutan Hög tillgänglighet vara avmarkerad.
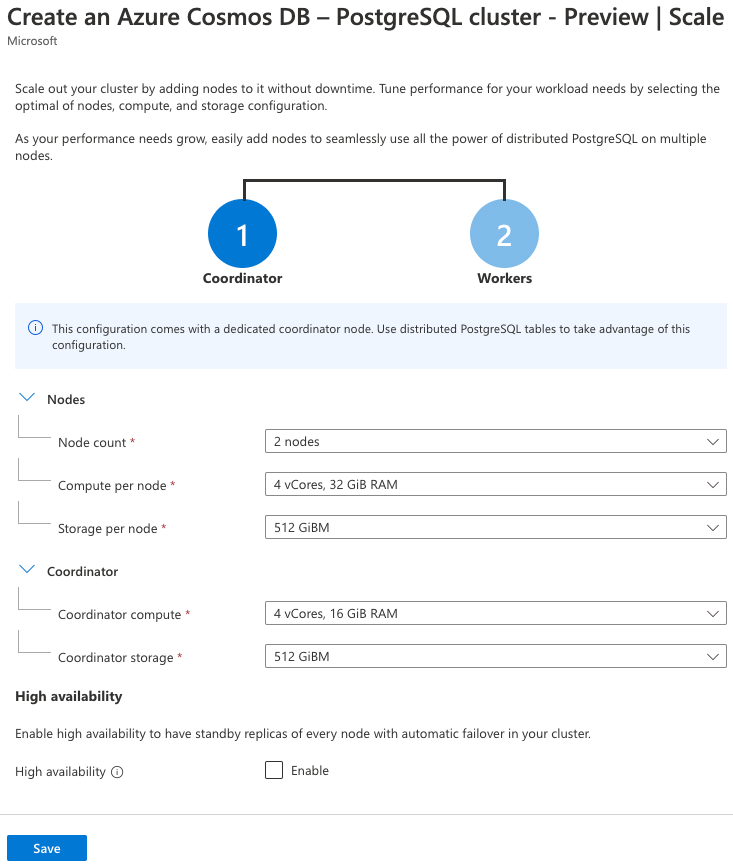
Välj Spara på skalningssidan för att återgå till klusterkonfigurationen.
Välj knappen Nästa: Nätverk > för att gå vidare till fliken Nätverk i konfigurationsdialogrutan.
På fliken Nätverk anger du metoden Anslut ivity till Offentlig åtkomst (tillåtna IP-adresser) och markerar rutan Tillåt offentlig åtkomst från Azure-tjänster och resurser i Azure till det här klustret.
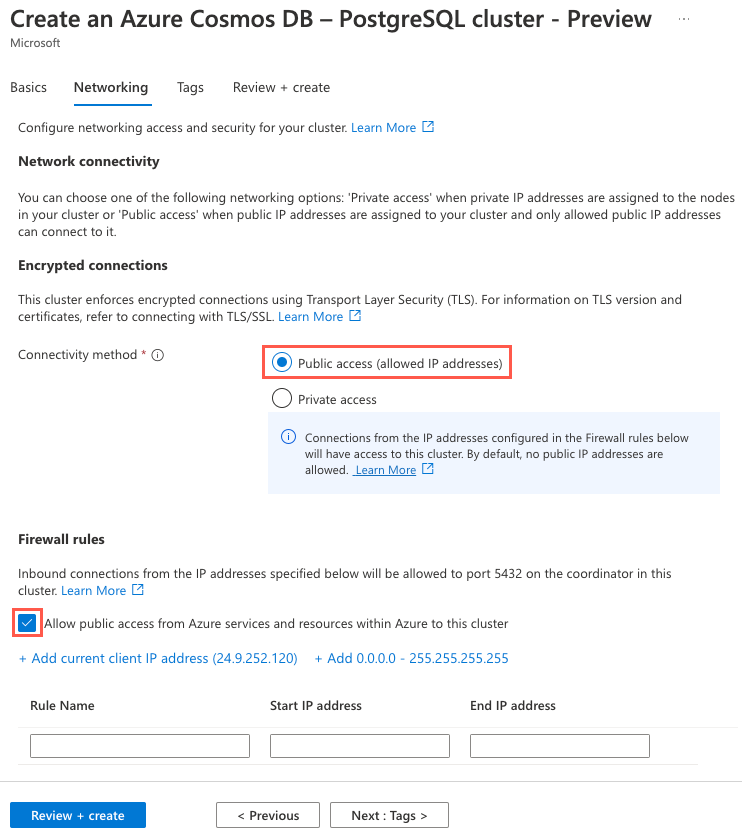
Välj knappen Granska + skapa och välj sedan Skapa på granskningsskärmen för att skapa klustret.
Anslut till databasen med psql i Azure Cloud Shell
När azure Cosmos DB for PostgreSQL-klustret har slutfört etableringen går du till resursen i Azure-portalen.
I den vänstra navigeringsmenyn väljer du Anslut ionssträngar under Inställningar och kopierar anslutningssträng märkt psql.
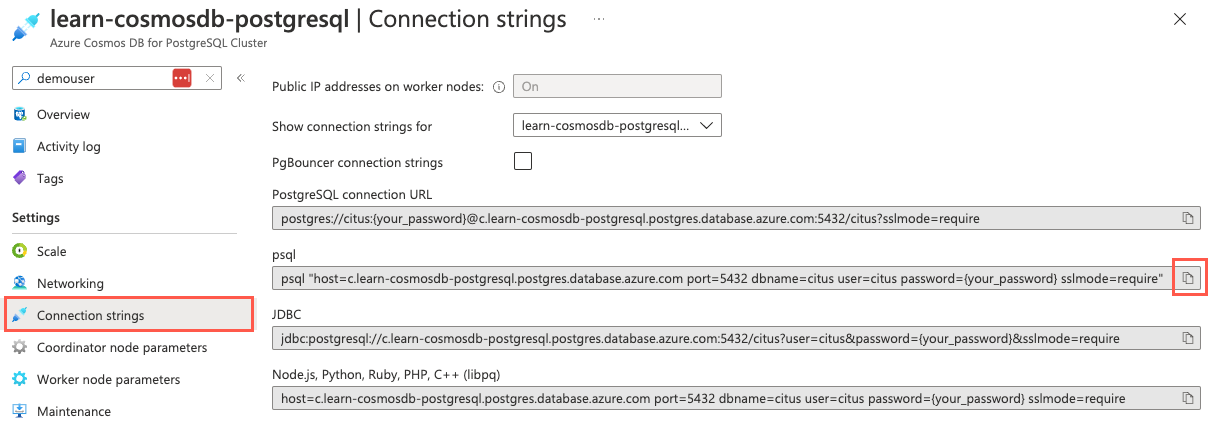
På sidan Anslut ionssträngar är knappen kopiera till Urklipp till höger om psql-anslutningssträng markerad.
Klistra in anslutningssträng i en textredigerare som Anteckningar och ersätt
{your_password}token med det lösenord som du tilldeladecitusanvändaren när du skapade klustret. Kopiera den uppdaterade anslutningssträng för användning nedan.Öppna Azure Cloud Shell i en webbläsare.
Välj Bash som miljö.
Om du uppmanas till det väljer du den prenumeration som du använde för ditt Azure Cosmos DB för PostgreSQL-konto. Välj sedan Skapa lagring.
Använd nu kommandoradsverktyget psql för att ansluta till databasen. Klistra in den uppdaterade anslutningssträng (den som innehåller rätt lösenord) i kommandotolken i Cloud Shell och kör sedan kommandot, som bör se ut ungefär som följande kommando:
psql "host=c.learn-cosmosdb-postgresql.postgres.database.azure.com port=5432 dbname=citus user=citus password=P@ssword.123! sslmode=require"
Identifiera information om noderna i klustret
Koordinatormetadatatabellerna innehåller information om arbetsnoder i klustret.
Kör följande fråga mot arbetsnodtabellen
pg_dist_nodeför att visa information om noderna i klustret:-- Turn on expanded display to pivot the results \x-- Retrieve node details SELECT * FROM pg_dist_node;Granska frågeutdata för mer information, inklusive ID, namn och port som är associerad med varje nod. Dessutom kan du se om noden är aktiv och bör innehålla shards, bland annat information.
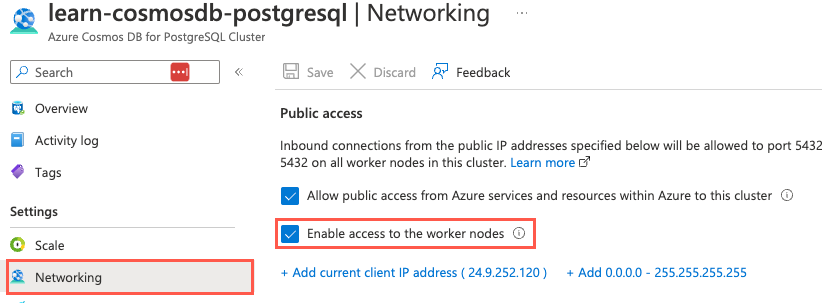
-[ RECORD 1 ]----+----------------------------------------------------------------- nodeid | 2 groupid | 2 nodename | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com nodeport | 5432 noderack | default hasmetadata | t isactive | t noderole | primary nodecluster | default metadatasynced | t shouldhaveshards | t -[ RECORD 2 ]----+----------------------------------------------------------------- nodeid | 3 groupid | 3 nodename | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com nodeport | 5432 noderack | default hasmetadata | t isactive | t noderole | primary nodecluster | default metadatasynced | t shouldhaveshards | t -[ RECORD 3 ]----+----------------------------------------------------------------- nodeid | 4 groupid | 0 nodename | private-c.learn-cosmosdb-postgresql.postgres.database.azure.com nodeport | 5432 noderack | default hasmetadata | t isactive | t noderole | primary nodecluster | default metadatasynced | t shouldhaveshards | fDu kan använda nodnamnen och portnumren som anges i utdata för att ansluta direkt till arbetare, vilket är vanligt vid justering av frågeprestanda. Anslut direkt till arbetsnoder kräver Aktivera åtkomst till arbetsnoderna genom att markera kryssrutan på sidan Nätverk för din Azure Cosmos DB for PostgreSQL-resurs i Azure-portalen.
Skapa distribuerade tabeller
Nu när du är ansluten till databasen kan du börja fylla i databasen. Du använder psql för att:
- Skapa användare och betalningstabeller.
- Instruera Citus att distribuera båda tabellerna och partitionera dem mellan arbetsnoderna.
Distribuerade tabeller partitioneras vågrätt över tillgängliga arbetsnoder. Den här fördelningen innebär att tabellens rader lagras på olika noder i fragmenttabeller som kallas shards.
I Cloud Shell kör du följande fråga för att skapa tabellerna
payment_usersochpayment_events:CREATE TABLE payment_users ( user_id bigint PRIMARY KEY, url text, login text, avatar_url text ); CREATE TABLE payment_events ( event_id bigint, event_type text, user_id bigint, merchant_id bigint, event_details jsonb, created_at timestamp, -- Create a compound primary key so that user_id can be set as the distribution column PRIMARY KEY (event_id, user_id) );Tilldelningen
PRIMARY KEYpayment_eventsför tabellen är en sammansatt nyckel som gör att fältetuser_idkan tilldelas som distributionskolumn.CREATE TABLENär kommandona körs skapas lokala tabeller på koordinatornoden. Om du vill distribuera tabellerna till arbetsnoderna måste du köracreate_distributed_tablefunktionen för varje tabell och ange vilken distributionskolumn som ska användas vid horisontell partitionering av dem. Kör följande fråga i Cloud Shell för att distribuera dinapayment_eventsochpayment_userstabeller mellan arbetsnoderna:SELECT create_distributed_table('payment_users', 'user_id'); SELECT create_distributed_table('payment_events', 'user_id');Både tabellerna
payment_eventsochpayment_userstilldelades samma distributionskolumn, vilket resulterade i att relaterade data för båda tabellerna samlokaliserades på samma nod. Information om hur du väljer rätt distributionskolumn ligger utanför omfånget för den här utbildningsmodulen. Du kan ändå lära dig mer om det genom att läsa artikeln Välj distributionskolumner i Azure Cosmos DB for PostgreSQL i Microsoft-dokumenten.
Skapa en referenstabell
Sedan använder psql du för att:
- Skapa köpmannatabellen.
- Instruera Citus att distribuera hela tabellen som en referenstabell på varje arbetsnod.
En referenstabell är en distribuerad tabell vars hela innehåll är koncentrerat till en enda shard som replikeras på varje arbetare. Frågor om alla arbetare kan komma åt referensinformationen lokalt utan nätverkskostnaderna för att begära rader från en annan nod. Referenstabeller kräver inte specifikationen av en distributionskolumn eftersom det inte finns något behov av att skilja mellan olika shards per rad. Referenstabeller är vanligtvis små och används för att lagra data som är relevanta för frågor som körs på alla arbetsnoder.
I Cloud Shell kör du följande fråga för att skapa
payment_merchantstabellen:CREATE TABLE payment_merchants ( merchant_id bigint PRIMARY KEY, name text, url text );create_reference_table()Använd sedan funktionen för att distribuera tabellen till varje arbetsnod.SELECT create_reference_table('payment_merchants');
Läsa in data i händelsetabellen
Woodgrove Bank har försett dig med sina historiska händelsedata i en CSV-fil, så du har vissa data att arbeta med när du installerar och testar de begärda tilläggen. De tillhandahåller användardata via ett säkert Azure Blob Storage-konto så att du kan fylla payment_users i tabellen i nästa övning. Filen events.csv är tillgänglig via en offentligt tillgänglig URL.
Du kan använda COPY kommandot för att utföra en engångsinläsning av dessa data i payment_events tabellen.
Kör följande kommando för att ladda ned CSV-filer som innehåller användar- och betalningsinformation och använd
COPYsedan kommandot för att läsa in data från de nedladdade CSV-filerna till de distribuerade tabellerna ochpayment_userspayment_events:SET CLIENT_ENCODING TO 'utf8'; \COPY payment_events FROM PROGRAM 'curl https://raw.githubusercontent.com/MicrosoftDocs/mslearn-create-connect-postgresHyperscale/main/events.csv' WITH CSVI kommandot
COPYsom utfärdasFROM PROGRAMinformerar -satsen koordinatorn om att hämta datafilerna från ett program som körs på koordinatorn, i det här falletcurl. AlternativetWITH CSVinnehåller information om formatet på filen som matas in.Kör följande kommandon för att verifiera att data har lästs in i
payment_eventstabellen med hjälp avCOPYkommandot .SELECT COUNT(*) FROM payment_events;
Visa information om dina distribuerade tabeller
Nu när du har skapat några distribuerade tabeller ska vi använda citus_tables vyn för att inspektera dessa tabeller.
Kör följande fråga för att visa information om dina distribuerade tabeller:
SELECT table_name, citus_table_type, distribution_column, table_size, shard_count FROM citus_tables;Observera utdata från frågan och den information som den innehåller.
table_name | citus_table_type | distribution_column | table_size | shard_count ------------------+------------------+---------------------+------------+------------- payment_events | distributed | user_id | 26 MB | 32 payment_merchants | reference | <none> | 48 kB | 1 payment_users | distributed | user_id | 512 kB | 32Kommentar
shard_countObservera skillnaden och mellan hur många shards som används för distribuerade tabeller jämfört med referenstabeller. Den här skillnaden ger en inblick i hur Citus hanterar fördelningen av data internt. Vyncitus_tableinnehåller också information om storleken på dina tabeller.
Granska tabellsharding
Titta sedan på de shards Citus skapade för att distribuera varje tabells data:
Metadatatabellen
pg_dist_shardinnehåller information om shards i klustret. Kör följande fråga för att visa de shards som skapats för var och en av dina tabeller:SELECT * from pg_dist_shard;Granska utdata från ovanstående fråga. Kom ihåg att tabellen
payment_merchantsfinns i ett enda fragment. Jämför det med tabellernapayment_eventsochpayment_userssom var och en innehåller 32 shards.Om du vill se hur Citus hanterar referenstabeller för horisontell partitionering kan du använda
citus_shardsvyn för att visa platsen för shards på arbetsnoder. Kör följande fråga:SELECT table_name, shardid, citus_table_type, nodename FROM citus_shards WHERE table_name = 'payment_merchants'::regclass;I utdata
payment_merchantsdistribueras tabellens enda fragment över varje nod i klustret.table_name | shardid | citus_table_type | nodename ------------------+---------+------------------+----------------------------------------------------------------- payment_merchants | 102072 | reference | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com payment_merchants | 102072 | reference | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com payment_merchants | 102072 | reference | private-c.learn-cosmosdb-postgresql.postgres.database.azure.comOm du vill jämföra kör du följande fråga för att visa fördelningen av shards för
payment_eventstabellen:SELECT table_name, shardid, citus_table_type, nodename FROM citus_shards WHERE table_name = 'payment_events'::regclass;För
distributedtabeller visas var ochshardiden bara en gång i resultatet och varje shard finns bara på en enda nod.table_name | shardid | citus_table_type | nodename ---------------+---------+------------------+----------------------------------------------------------------- payment_events | 102040 | distributed | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102041 | distributed | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102042 | distributed | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102043 | distributed | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102044 | distributed | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102045 | distributed | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102046 | distributed | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102047 | distributed | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102048 | distributed | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102049 | distributed | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102050 | distributed | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102051 | distributed | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102052 | distributed | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102053 | distributed | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102054 | distributed | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102055 | distributed | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102056 | distributed | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102057 | distributed | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102058 | distributed | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102059 | distributed | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102060 | distributed | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102061 | distributed | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102062 | distributed | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102063 | distributed | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102064 | distributed | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102065 | distributed | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102066 | distributed | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102067 | distributed | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102068 | distributed | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102069 | distributed | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102070 | distributed | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102071 | distributed | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.comGratulerar! Du har skapat en distribuerad databas med flera noder med Hjälp av Azure Cosmos DB for PostgreSQL. Med hjälp av metadatatabeller och vyer utforskade du hur Citus-tillägget distribuerar data och ger ytterligare funktioner till PostgreSQL.
I Cloud Shell kör du följande kommando för att koppla från databasen:
\qDu kan hålla Cloud Shell öppet och gå vidare till nästa enhet.