Maskininlärningsmodeller
Anmärkning
Mer information finns på fliken Text och bilder !
Eftersom maskininlärning baseras på matematik och statistik är det vanligt att tänka på maskininlärningsmodeller i matematiska termer. I grunden är en maskininlärningsmodell ett program som kapslar in en funktion för att beräkna ett utdatavärde baserat på ett eller flera indatavärden. Processen för att definiera den funktionen kallas utbildning. När funktionen har definierats kan du använda den för att förutsäga nya värden i en process som kallas slutsatsdragning.
Nu ska vi utforska de steg som ingår i utbildning och slutsatsdragning.
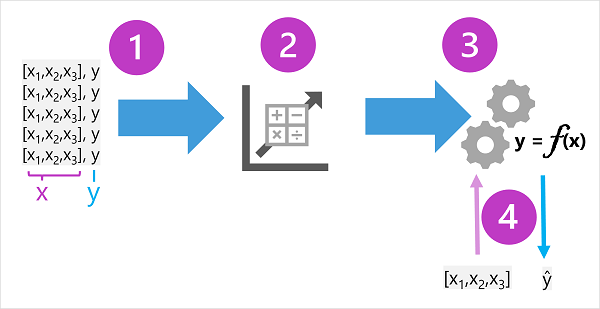
Träningsdata består av tidigare observationer. I de flesta fall inkluderar observationerna de observerade attributen eller egenskaperna i det som observeras och det kända värdet för det du vill träna en modell att förutsäga (kallas etiketten).
I matematiska termer ser du ofta de egenskaper som refereras till med hjälp av det korta variabelnamnet x och etiketten som kallas y. Vanligtvis består en observation av flera egenskapsvärden, så x är faktiskt en vektor (en matris med flera värden), så här: [x1,x2,x3,...].
För att göra detta tydligare ska vi överväga exemplen som beskrevs tidigare:
- I scenariot med glassförsäljning är vårt mål att träna en modell som kan förutsäga antalet glassförsäljningar baserat på vädret. Vädermätningarna för dagen (temperatur, nederbörd, vindhastighet och så vidare) skulle vara funktionerna (x), och antalet glassar som säljs varje dag skulle vara etiketten (y).
- I det medicinska scenariot är målet att förutsäga om en patient löper risk för diabetes baserat på deras kliniska mätningar. Patientens mätningar (vikt, blodsockernivå och så vidare) är egenskaperna (x) och sannolikheten för diabetes (till exempel 1 för risk, 0 för att inte vara i riskzonen) är etiketten (y).
- I forskningsscenariot i Antarktis vill vi förutsäga arten av en pingvin baserat på dess fysiska attribut. De viktigaste mätningarna av pingvinen (längden på dess fenor, bredden på dess näbb och så vidare) är egenskaperna (x) och arten (till exempel 0 för Adelie, 1 för Gentoo eller 2 för Chinstrap) är etiketten (y).
En algoritm tillämpas på data för att försöka fastställa en relation mellan egenskaperna och etiketten och generalisera relationen som en beräkning som kan utföras på x för att beräkna y. Den specifika algoritm som används beror på vilken typ av förutsägande problem du försöker lösa (mer om detta senare), men den grundläggande principen är att försöka anpassa data till en funktion där värdena för egenskaperna kan användas för att beräkna etiketten.
Resultatet av algoritmen är en modell som kapslar in beräkningen som härleds av algoritmen som en funktion – låt oss kalla den f. I matematisk notation:
y = f(x)
Nu när träningsfasen är klar kan den tränade modellen användas för slutsatsdragning. Modellen är i huvudsak ett program som kapslar in funktionen som skapas av träningsprocessen. Du kan ange en uppsättning egenskapsvärden och som utdata ta emot en förutsägelse av motsvarande etikett. Eftersom utdata från modellen är en förutsägelse som beräknades av funktionen, och inte ett observerat värde, ser du ofta utdata från funktionen som visas som ŷ (som är ganska härligt verbaliserad som "y-hat").