Typer av maskininlärningsmodell
Anmärkning
Mer information finns på fliken Text och bilder !
Det finns flera typer av maskininlärning och du måste använda lämplig typ beroende på vad du försöker förutsäga. En uppdelning av vanliga typer av maskininlärning visas i följande diagram.
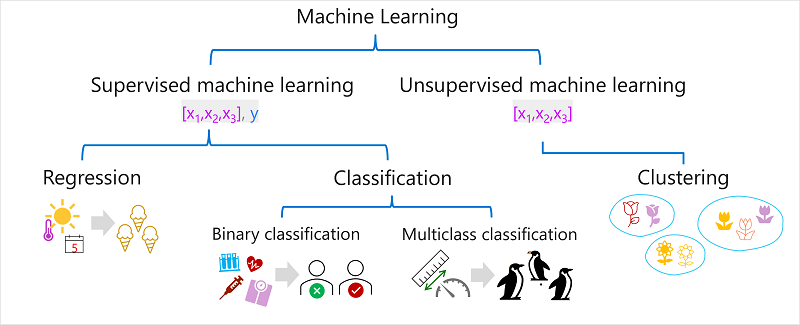
Övervakad maskininlärning
Övervakad maskininlärning är en allmän term för maskininlärningsalgoritmer där träningsdata innehåller både funktionsvärden och kända etikettvärden . Övervakad maskininlärning används för att träna modeller genom att fastställa en relation mellan funktioner och etiketter i tidigare observationer, så att okända etiketter kan förutsägas för funktioner i framtida fall.
Tillbakagång
Regression är en form av övervakad maskininlärning där etiketten som förutsägs av modellen är ett numeriskt värde. Till exempel:
- Antalet glassar som säljs en viss dag, baserat på temperaturen, nederbörden och vindarna.
- Försäljningspriset för en fastighet baserat på dess storlek i kvadratmeter, antalet sovrum det innehåller och socioekonomiska mått för dess plats.
- Bränsleeffektiviteten (i miles per gallon) för en bil baserat på motorns storlek, vikt, bredd, höjd och längd.
Omdöme
Klassificering är en form av övervakad maskininlärning där etiketten representerar en kategorisering eller klass. Det finns två vanliga klassificeringsscenarier.
Binär klassificering
I binär klassificering avgör etiketten om det observerade objektet är (eller inte) är en instans av en specifik klass. Eller med andra metoder förutsäger binära klassificeringsmodeller ett av två ömsesidigt uteslutande resultat. Till exempel:
- Om en patient är i riskzonen för diabetes baserat på kliniska mått som vikt, ålder, blodsockernivå och så vidare.
- Om en bankkund kommer att försumma ett lån baserat på inkomst, kredithistorik, ålder och andra faktorer.
- Om en e-postlistekund svarar positivt på ett marknadsföringserbjudande baserat på demografiska attribut och tidigare inköp.
I alla dessa exempel förutsäger modellen en binär true/false eller positiv/negativ förutsägelse för en enda möjlig klass.
Klassificering med flera klasser
Multiklassklassificering utökar binär klassificering för att förutsäga en etikett som representerar en av flera möjliga klasser. Ett exempel:
- Arten av en pingvin (Adelie, Gentoo eller Chinstrap) baserat på dess fysiska mätningar.
- Genren av en film (komedi, skräck, romantik, äventyr eller science fiction) baserat på dess rollbesättning, regissör och budget.
I de flesta scenarier som omfattar en känd uppsättning av flera klasser används multiklassklassificering för att förutsäga ömsesidigt uteslutande etiketter. Till exempel kan en pingvin inte vara både en Gentoo och en Adelie. Det finns dock även vissa algoritmer som du kan använda för att träna klassificeringsmodeller med flera etiketter, där det kan finnas fler än en giltig etikett för en enda observation. En film kan till exempel potentiellt kategoriseras som både science fiction och komedi.
Oövervakad maskininlärning
Oövervakad maskininlärning omfattar träningsmodeller som använder data som endast består av funktionsvärden utan några kända etiketter. Oövervakade maskininlärningsalgoritmer avgör relationerna mellan funktionerna i observationerna i träningsdata.
Klustring
Den vanligaste formen av oövervakad maskininlärning är klustring. En klustringsalgoritm identifierar likheter mellan observationer baserat på deras funktioner och grupperar dem i diskreta kluster. Till exempel:
- Gruppera liknande blommor baserat på deras storlek, antal blad och antal kronblad.
- Identifiera grupper av liknande kunder baserat på demografiska attribut och köpbeteende.
På sätt och vis liknar klustring klassificering i flera klasser. i det att den kategoriserar observationer i diskreta grupper. Skillnaden är att när du använder klassificering känner du redan till de klasser som observationerna i träningsdata tillhör. så algoritmen fungerar genom att fastställa relationen mellan funktionerna och den kända klassificeringsetiketten. I klustring finns det ingen tidigare känd klusteretikett och algoritmen grupperar dataobservationer baserat enbart på likheter med funktioner.
I vissa fall används klustring för att fastställa vilken uppsättning klasser som finns innan du tränar en klassificeringsmodell. Du kan till exempel använda klustring för att segmentera dina kunder i grupper och sedan analysera dessa grupper för att identifiera och kategorisera olika kundklasser (högt värde – låg volym, frekvent liten inköpare och så vidare). Du kan sedan använda kategoriseringarna för att märka observationerna i klustringsresultatet och använda etiketterade data för att träna en klassificeringsmodell som förutsäger vilken kundkategori en ny kund kan tillhöra.