Djupinlärning
Anmärkning
Mer information finns på fliken Text och bilder !
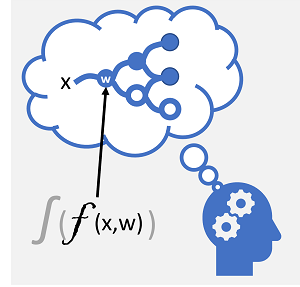
Djupinlärning är en avancerad form av maskininlärning som försöker efterlikna hur den mänskliga hjärnan lär sig. Nyckeln till djupinlärning är skapandet av ett artificiellt neuralt nätverk som simulerar elektrokemisk aktivitet i biologiska neuroner med hjälp av matematiska funktioner, som visas här.
| Biologiskt neuralt nätverk | Artificiellt neuralt nätverk |
|---|---|

|
|
| Neuroner avfyras som svar på elektrokemiska stimuli. När den utlöses skickas signalen till anslutna neuroner. | Varje neuron är en funktion som fungerar på ett indatavärde (x) och en vikt (w). Funktionen är insvept i en aktiveringsfunktion som avgör om utdata ska skickas vidare. |
Artificiella neurala nätverk består av flera lager av neuroner - vilket i huvudsak definierar en djupt kapslad funktion. Den här arkitekturen är anledningen till att tekniken kallas djupinlärning och de modeller som skapas av den kallas ofta för djupa neurala nätverk (DNN). Du kan använda djupa neurala nätverk för många typer av maskininlärningsproblem, inklusive regression och klassificering, samt mer specialiserade modeller för bearbetning av naturligt språk och visuellt innehåll.
Precis som andra maskininlärningstekniker som beskrivs i den här modulen handlar djupinlärning om att anpassa träningsdata till en funktion som kan förutsäga en etikett (y) baserat på värdet för en eller flera funktioner (x). Funktionen (f(x)) är det yttre lagret i en kapslad funktion där varje lager i det neurala nätverket kapslar in funktioner som fungerar på x och de viktvärden (w) som är associerade med dem. Algoritmen som används för att träna modellen innebär att iterativt mata in funktionsvärdena (x) i träningsdata framåt genom lagren för att beräkna utdatavärden för ŷ, validera modellen för att utvärdera hur långt ifrån de beräknade ŷ värdena är från de kända y-värdena (som kvantifierar felnivån eller förlusten i modellen), och sedan ändra vikterna (w) för att minska förlusten. Den tränade modellen innehåller de slutliga viktvärdena som resulterar i de mest exakta förutsägelserna.
Exempel – Använda djupinlärning för klassificering
För att bättre förstå hur en djup neural nätverksmodell fungerar ska vi utforska ett exempel där ett neuralt nätverk används för att definiera en klassificeringsmodell för pingvinarter.
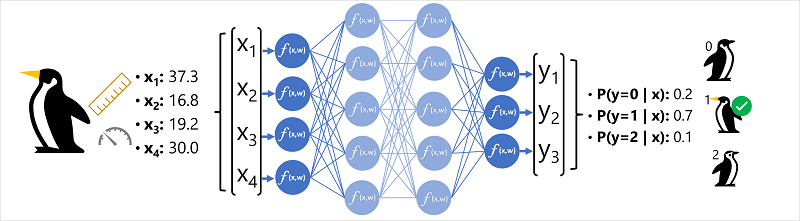
Funktionsdata (x) består av vissa mätningar av en pingvin. Mer specifikt är måtten:
- Längden på pingvinens räkning.
- Djupet av pingvinens räkning.
- Längden på pingvinens simfötter.
- Pingvinens vikt.
I det här fallet är x en vektor med fyra värden, eller matematiskt x=[x1,x2,x3,x4].
Etiketten vi försöker förutsäga (y) är pingvinarten, och att det finns tre möjliga arter det kan vara:
- Adelie
- Gentoo
- Chinstrap
Det här är ett exempel på ett klassificeringsproblem, där maskininlärningsmodellen måste förutsäga den mest sannolika klass som en observation tillhör. En klassificeringsmodell åstadkommer detta genom att förutsäga en etikett som består av sannolikheten för varje klass. Med andra ord är y en vektor med tre sannolikhetsvärden; en för var och en av de möjliga klasserna: [P(y=0|x), P(y=1|x), P(y=2|x)].
Processen för att härleda en förutsagd pingvinklass med det här nätverket är:
- Funktionsvektorn för en pingvinobservation matas in i indataskiktet i det neurala nätverket, som består av en neuron för varje x-värde . I det här exemplet används följande x-vektor som indata: [37.3, 16.8, 19.2, 30.0]
- Funktionerna för det första lagret av neuron beräknar var och en en viktad summa genom att kombinera x-värdet och w-vikten och skicka den till en aktiveringsfunktion som avgör om den uppfyller tröskelvärdet för att överföras till nästa lager.
- Varje neuron i ett lager är ansluten till alla neuroner i nästa lager (en arkitektur som ibland kallas ett helt anslutet nätverk) så resultatet av varje lager matas framåt genom nätverket tills de når utdataskiktet.
- Utdataskiktet genererar en vektor med värden. i detta fall, med hjälp av en softmax eller liknande funktion för att beräkna sannolikhetsfördelningen för de tre möjliga klasserna av pingvin. I det här exemplet är utdatavektorn: [0.2, 0.7, 0.1]
- Elementen i vektorn representerar sannolikheterna för klasserna 0, 1 och 2. Det andra värdet är det högsta, så modellen förutsäger att pingvinarten är 1 (Gentoo).
Hur lär sig ett neuralt nätverk?
Vikterna i ett neuralt nätverk är centrala för hur de beräknar förutsagda värden för etiketter. Under träningsprocessen lär sig modellen de vikter som resulterar i de mest exakta förutsägelserna. Nu ska vi utforska träningsprocessen lite mer detaljerat för att förstå hur den här inlärningen sker.
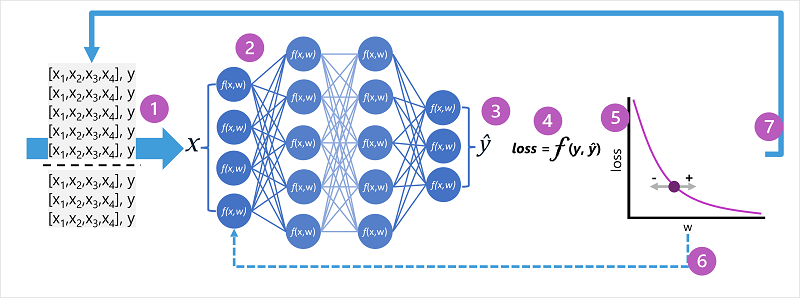
- Tränings- och valideringsdatauppsättningarna definieras och träningsfunktionerna matas in i indataskiktet.
- Neuronerna i varje lager i nätverket tillämpar sina vikter (som ursprungligen tilldelas slumpmässigt) och matar data via nätverket.
- Utdataskiktet producerar en vektor som innehåller de beräknade värdena för ŷ. Till exempel kan utdata för en pingvinklassförutsägelse vara [0.3. 0.1. 0.6].
- En förlustfunktion används för att jämföra de förutsagda ŷ värdena med de kända y-värdena och aggregera skillnaden (som kallas förlust). Om den kända klassen för fallet som returnerade utdata i föregående steg till exempel är Chinstrap, bör y-värdet vara [0.0, 0.0, 1.0]. Den absoluta skillnaden mellan detta och ŷ-vektorn är [0.3, 0.1, 0.4]. I verkligheten beräknar förlustfunktionen den aggregerade variansen för flera fall och sammanfattar den som ett enda förlustvärde .
- Eftersom hela nätverket i stort sett är en stor kapslad funktion kan en optimeringsfunktion använda differentiell kalkyl för att utvärdera påverkan av varje vikt i nätverket på förlusten och bestämma hur de kan justeras (upp eller ner) för att minska mängden total förlust. Den specifika optimeringstekniken kan variera, men omfattar vanligtvis en gradient descent-metod där varje vikt ökas eller minskas för att minimera förlusten.
- Ändringarna av vikterna backpropageras till lagren i nätverket och ersätter tidigare använda värden.
- Processen upprepas över flera iterationer (kallas epoker) tills förlusten minimeras och modellen förutsäger acceptabelt korrekt.
Anmärkning
Även om det är lättare att tänka på varje fall i träningsdata som skickas via nätverket en i taget, batchas data i matriser och bearbetas med linjära algebraiska beräkningar. Därför utförs neural nätverksträning bäst på datorer med grafiska bearbetningsenheter (GPU:er) som är optimerade för vektor- och matrismanipulering.