Testa modeller på Lekplatser i Azure OpenAI Studio
Lekplatser är användbara gränssnitt i Azure OpenAI Studio som du kan använda för att experimentera med dina distribuerade modeller utan att behöva utveckla ett eget klientprogram. Azure OpenAI Studio erbjuder flera lekplatser med olika alternativ för parameterjustering.
Lekplats för slutföranden
Med lekplatsen Completions kan du göra anrop till dina distribuerade modeller via ett text-in-, text-out-gränssnitt och justera parametrar. Du måste välja distributionsnamnet för din modell under Distributioner. Du kan också använda de angivna exemplen för att komma igång och sedan kan du ange dina egna frågor.
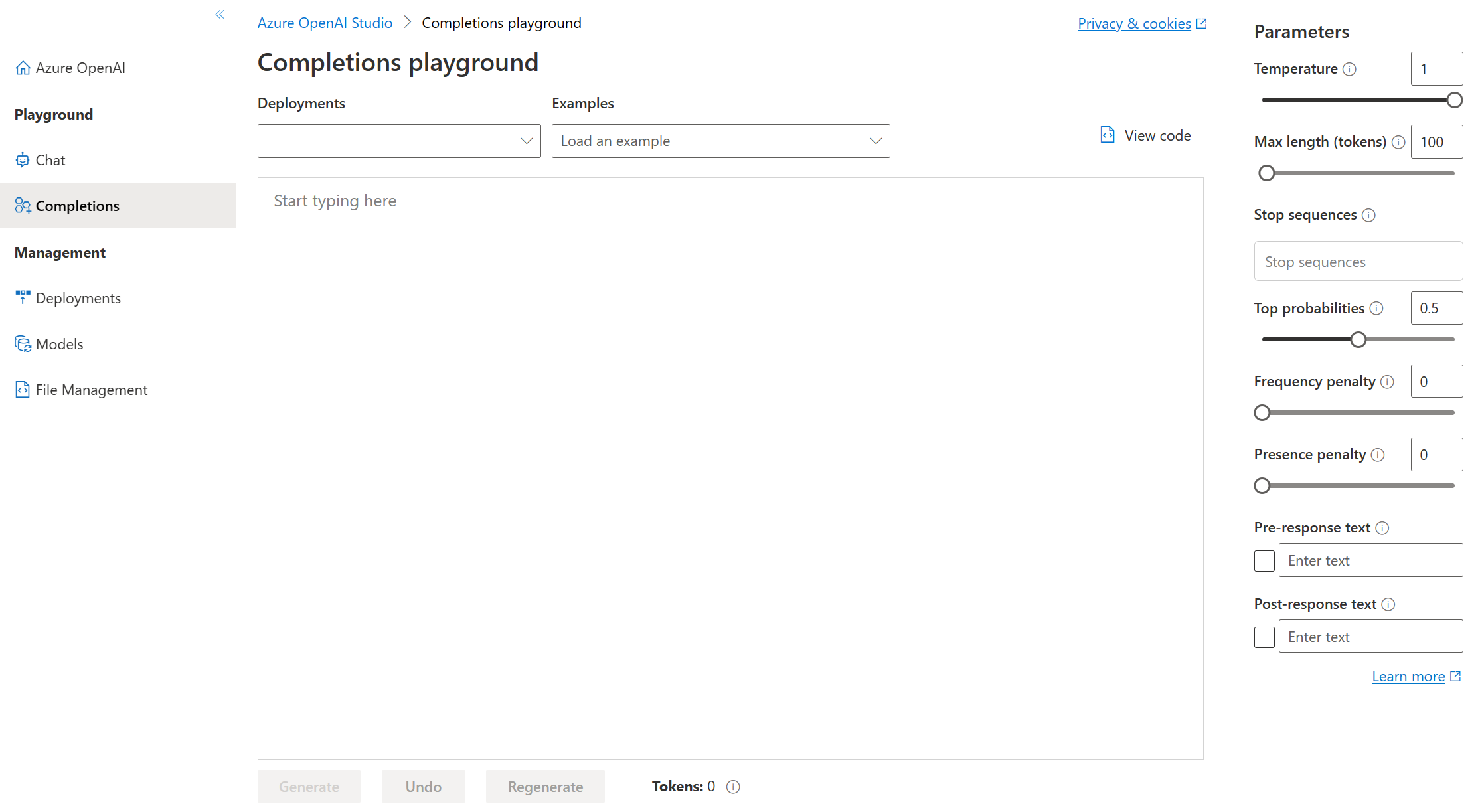
Parametrar för Completions Playground
Det finns många parametrar som du kan justera för att ändra modellens prestanda:
- Temperatur: Styr slumpmässighet. Att sänka temperaturen innebär att modellen ger mer repetitiva och deterministiska svar. Att öka temperaturen resulterar i mer oväntade eller kreativa svar. Prova att justera temperaturen eller Top P men inte båda.
- Maximal längd (token): Ange en gräns för antalet token per modellsvar. API:et stöder högst 4 000 token som delas mellan prompten (inklusive systemmeddelande, exempel, meddelandehistorik och användarfråga) och modellens svar. En token är ungefär fyra tecken för typisk engelsk text.
- Stoppsekvenser: Gör så att svaren stoppas vid en önskad punkt, till exempel slutet av en mening eller lista. Ange upp till fyra sekvenser där modellen slutar generera ytterligare token i ett svar. Den returnerade texten innehåller inte stoppsekvensen.
- Top probabilities (Top P): Liknar temperatur, detta styr slumpmässighet men använder en annan metod. Om du sänker top P begränsas modellens tokenval till likelier-token. Om du ökar topp P kan modellen välja mellan token med både hög och låg sannolikhet. Prova att justera temperaturen eller Top P men inte båda.
- Frekvensstraff: Minska risken för att upprepa en token proportionellt baserat på hur ofta den har dykt upp i texten hittills. Detta minskar sannolikheten för att upprepa exakt samma text i ett svar.
- Närvarostraff: Minska risken för att upprepa alla token som har dykt upp i texten hittills. Detta ökar sannolikheten för att introducera nya ämnen i ett svar.
- Text före svar: Infoga text efter användarens indata och före modellens svar. Detta kan hjälpa dig att förbereda modellen för ett svar.
- Text efter svar: Infoga text efter modellens genererade svar för att uppmuntra ytterligare användarindata, som när du modellerar en konversation.
Chattlekplats
Chattlekplatsen baseras på ett gränssnitt för konversation in och ut med meddelanden. Du kan initiera sessionen med ett systemmeddelande för att konfigurera chattkontexten.
I chattlekplatsen kan du lägga till exempel med några bilder. Termen few-shot syftar på att tillhandahålla några exempel som hjälper modellen att lära sig vad den behöver göra. Du kan tänka på det i motsats till nollskott, som refererar till att inte ge några exempel.
I assistentkonfigurationen kan du ge några exempel på vad användarens indata kan vara och vad assistentsvaret ska vara. Assistenten försöker efterlikna de svar som du tar med här i ton, regler och format som du har definierat i systemmeddelandet.
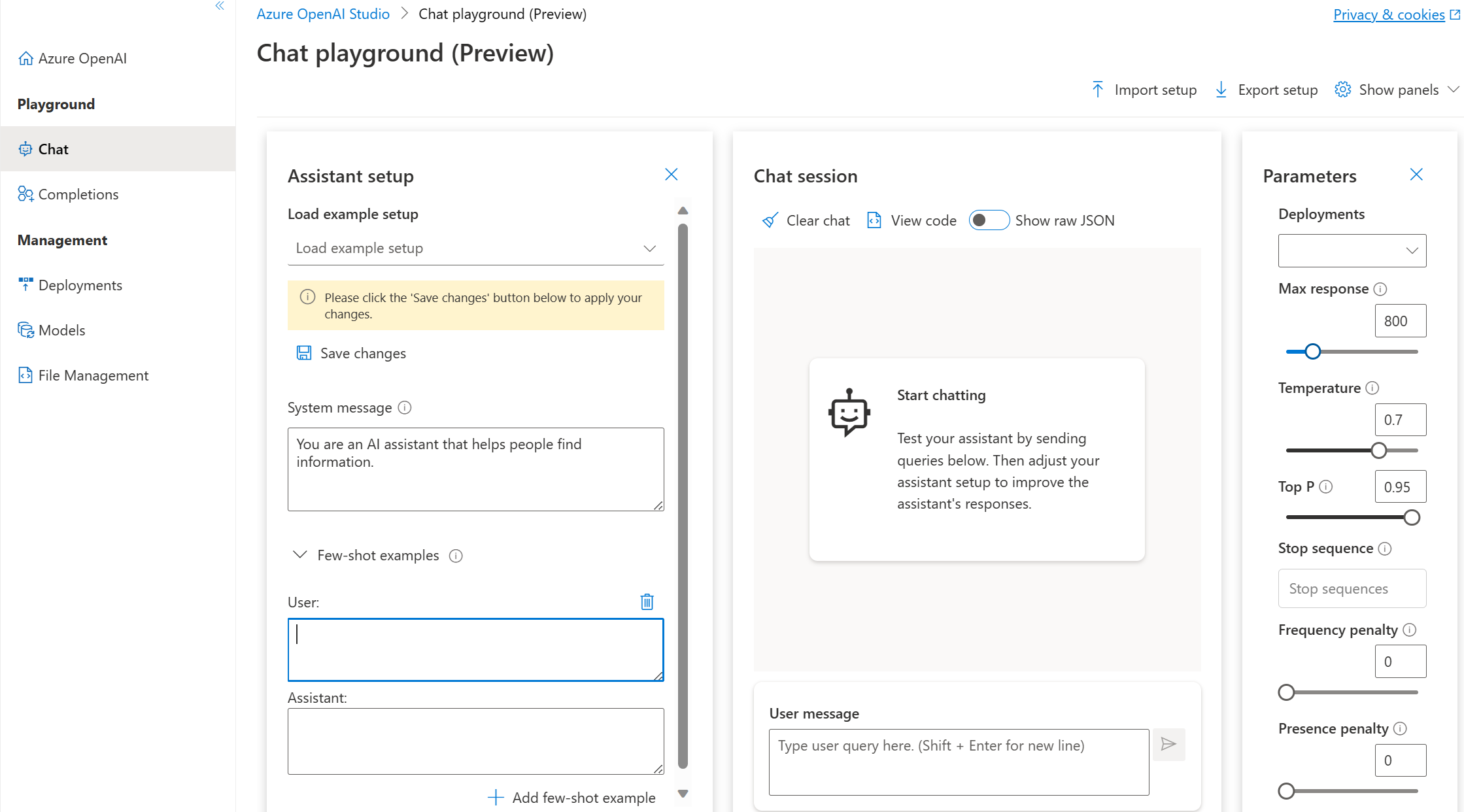
Parametrar för chattlekplats
Chattlekplatsen, som lekplatsen Completions, innehåller även parametern Temperature. Chattlekplatsen stöder även andra parametrar som inte är tillgängliga i Lekplatsen För slutföranden. Dessa kan vara:
- Maximalt svar: Ange en gräns för antalet token per modellsvar. API:et stöder högst 4 000 token som delas mellan prompten (inklusive systemmeddelande, exempel, meddelandehistorik och användarfråga) och modellens svar. En token är ungefär fyra tecken för typisk engelsk text.
- Topp P: Liknar temperatur, detta styr slumpmässighet men använder en annan metod. Om du sänker top P begränsas modellens tokenval till likelier-token. Om du ökar topp P kan modellen välja mellan token med både hög och låg sannolikhet. Prova att justera temperaturen eller Top P men inte båda.
- Tidigare meddelanden som ingår: Välj antalet tidigare meddelanden som ska inkluderas i varje ny API-begäran. Att inkludera tidigare meddelanden hjälper till att ge modellkontexten för nya användarfrågor. Om du anger det här numret till 10 ingår fem användarfrågor och fem systemsvar.
Antalet aktuella token kan visas från chattlekplatsen. Eftersom API-anropen prissätts efter token och det är möjligt att ange en maxgräns för svarstoken vill du hålla utkik efter det aktuella antalet token för att se till att konversationen inte överskrider det maximala antalet svarstoken.