Beskriva integreringsmetoderna mellan SQL- och Spark-pooler i Azure Synapse Analytics
Genom att skapa analyslösningar i Azure Synapse Analytics krävs inte längre behovet av att konfigurera flera tjänster för att ansluta ett Apache Spark-kluster till en SQL-databas. Med Azure Synapse Analytics-miljön kan du använda båda teknikerna inom en integrerad plattform. Med den integrerade plattformsupplevelsen kan du växla mellan Apache Spark- och SQL-baserade datateknikuppgifter som gäller för den expertis du har internt. Därför kan en Apache Spark-orienterad datatekniker enkelt kommunicera och arbeta med en SQL-baserad datatekniker på samma plattform.
Samverkan mellan Apache Spark och SQL hjälper dig att uppnå följande:
- Arbeta med SQL och Apache Spark för att direkt utforska och analysera Parquet-, CSV-, TSV- och JSON-filer som lagras i datasjön.
- Aktivera snabba, skalbara inläsningar för dataöverföring mellan SQL- och Apache Spark-databaser.
- Använd ett delat Hive-kompatibelt metadatasystem som gör att du kan definiera tabeller på filer i datasjön så att de kan användas av antingen Apache Spark eller Hive.
Det väcker frågan om hur SQL- och Apache Spark-integrering fungerar. Det är där Azure Synapse Apache Spark till Synapse SQL-anslutningsappen spelar in.
Azure Synapse Apache Spark till Synapse SQL-anslutningsappen är utformad för att effektivt överföra data mellan serverlösa Apache Spark-pooler och dedikerade SQL-pooler i Azure Synapse. För närvarande fungerar Azure Synapse Apache Spark till Synapse SQL-anslutningsappen endast på dedikerade SQL-pooler, det fungerar inte med serverlösa SQL-pooler.
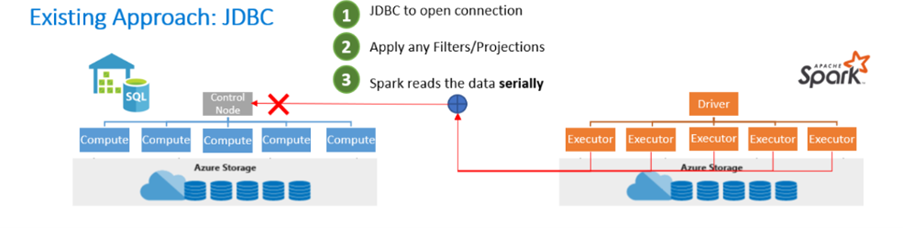
I den befintliga metoden ser du ofta användningen av JavaDataBaseConnectivity (JDBC) Application Programming Interface (API). JDBC-API:et öppnar anslutningen, filtrerar och tillämpar projektioner, och Apache Spark läser data seriellt. Eftersom två distribuerade system som Apache Spark och SQL-pooler används blir JDBC-API:et en flaskhals med seriell dataöverföring.
Därför är en ny metod att använda både JDBC och PolyBase. Först öppnar JDBC en anslutning och utfärdar CETAS-instruktioner (Create External Tables As Select) och skickar filter och projektioner. Filter och projektioner tillämpas sedan på informationslagret och exporterar data parallellt med PolyBase. Apache Spark läser data parallellt baserat på den användartillhandahållna arbetsytan och standarddatasjölagringen.

Därför kan du använda Azure Synapse Apache Spark-poolen till Synapse SQL-anslutningsappen för att överföra data mellan ett Data Lake-lager via Apache Spark och dedikerade SQL-pooler effektivt.