Övning: Integrera SQL- och Spark-pooler i Azure Synapse Analytics
I följande övning utforskar vi integreringen av SQL- och Apache Spark-pooler i Azure Synapse Analytics.
Integrera SQL- och Apache Spark-pooler i Azure Synapse Analytics
Du vill skriva till en dedikerad SQL-pool när du har utfört datateknikuppgifter i Spark och sedan referera till SQL-pooldata som en källa för anslutning till Apache Spark DataFrames som innehåller data från andra filer.
Du bestämmer dig för att använda Azure Synapse Apache Spark till Synapse SQL-anslutningsappen för att effektivt överföra data mellan Spark-pooler och SQL-pooler i Azure Synapse.
Överföring av data mellan Apache Spark-pooler och SQL-pooler kan göras med hjälp av JavaDataBaseConnectivity (JDBC). Men med tanke på två distribuerade system som Apache Spark och SQL-pooler tenderar JDBC att vara en flaskhals med seriell dataöverföring.
Azure Synapse Apache Spark-poolen till Synapse SQL-anslutningsappen är en implementering av datakällan för Apache Spark. Den använder Azure Data Lake Storage Gen2 och PolyBase i SQL-pooler för att effektivt överföra data mellan Spark-klustret och Synapse SQL-instansen.
Om vi vill använda Apache Spark-poolen till Synapse SQL Connector (
sqlanalytics) är ett alternativ att skapa en tillfällig vy över data i DataFrame. Kör koden nedan i en ny cell för att skapa en vy med namnettop_purchases:# Create a temporary view for top purchases topPurchases.createOrReplaceTempView("top_purchases")Vi skapade en ny tillfällig vy från dataramen
topPurchasessom vi skapade tidigare och som innehåller de utplattade JSON-användarköpsdata.Vi måste köra kod som använder Apache Spark-poolen till Synapse SQL-anslutningsappen i Scala. För att göra det lägger vi till magin
%%sparki cellen. Kör koden nedan i en ny cell för att läsa fråntop_purchasesvyn:%%spark // Make sure the name of the SQL pool (SQLPool01 below) matches the name of your SQL pool. val df = spark.sqlContext.sql("select * from top_purchases") df.write.sqlanalytics("SQLPool01.wwi.TopPurchases", Constants.INTERNAL)Kommentar
Cellen kan ta över en minut att köra. Om du har kört det här kommandot tidigare får du ett felmeddelande om att "Det finns redan och objektet heter..." eftersom tabellen redan finns.
När cellen har körts tar vi en titt på listan över SQL-pooltabeller för att kontrollera att tabellen har skapats åt oss.
Lämna anteckningsboken öppen och navigera sedan till datahubben (om den inte redan är markerad).
Välj fliken Arbetsyta(1), expandera SQL-poolen, välj ellipserna (...) i Tabeller (2) och välj Uppdatera (3).
wwi.TopPurchasesExpandera tabellen och kolumnerna (4).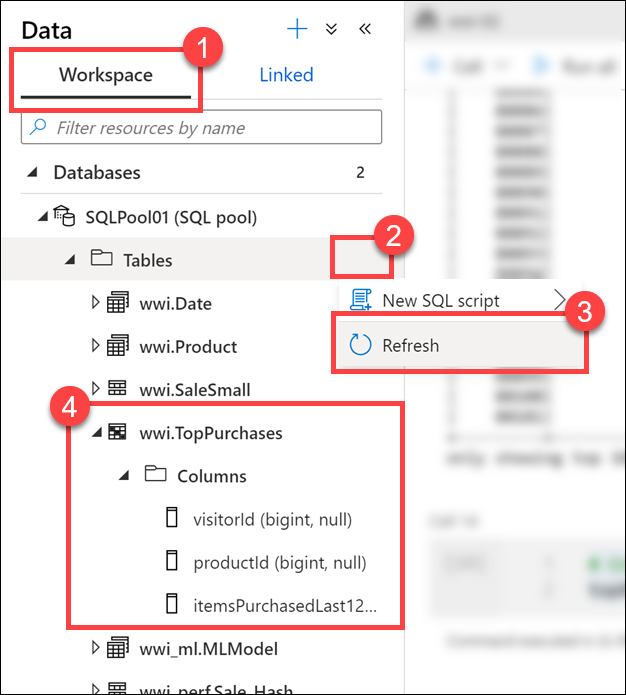
Som du ser
wwi.TopPurchasesskapades tabellen automatiskt åt oss, baserat på det härledda schemat för Apache Spark DataFrame. Apache Spark-poolen till Synapse SQL-anslutningsappen var ansvarig för att skapa tabellen och effektivt läsa in data i den.Gå tillbaka till notebook-filen och kör koden nedan i en ny cell för att läsa försäljningsdata från alla Parquet-filer som finns i
sale-small/Year=2019/Quarter=Q4/Month=12/mappen:dfsales = spark.read.load('abfss://wwi-02@' + datalake + '.dfs.core.windows.net/sale-small/Year=2019/Quarter=Q4/Month=12/*/*.parquet', format='parquet') display(dfsales.limit(10))Kommentar
Det kan ta över 3 minuter innan cellen körs.
Variabeln
datalakesom vi skapade i den första cellen används här som en del av filsökvägen.
Jämför filsökvägen i cellen ovan med filsökvägen i den första cellen. Här använder vi en relativ sökväg för att läsa in alla försäljningsdata för december 2019 från Parquet-filerna som finns i
sale-small, jämfört med bara den 31 december 2010.Nu ska vi läsa in
TopSalesdata från SQL-pooltabellen som vi skapade tidigare i en ny Apache Spark DataFrame och sedan ansluta dem till den nyadfsalesDataFrame. För att göra det måste vi återigen använda magin%%sparki en ny cell eftersom vi använder Apache Spark-poolen till Synapse SQL-anslutningsappen för att hämta data från SQL-poolen. Sedan måste vi lägga till DataFrame-innehållet i en ny tillfällig vy så att vi kan komma åt data från Python.Kör koden nedan i en ny cell för att läsa från SQL-pooltabellen
TopSalesoch spara den i en tillfällig vy:%%spark // Make sure the name of the SQL pool (SQLPool01 below) matches the name of your SQL pool. val df2 = spark.read.sqlanalytics("SQLPool01.wwi.TopPurchases") df2.createTempView("top_purchases_sql") df2.head(10)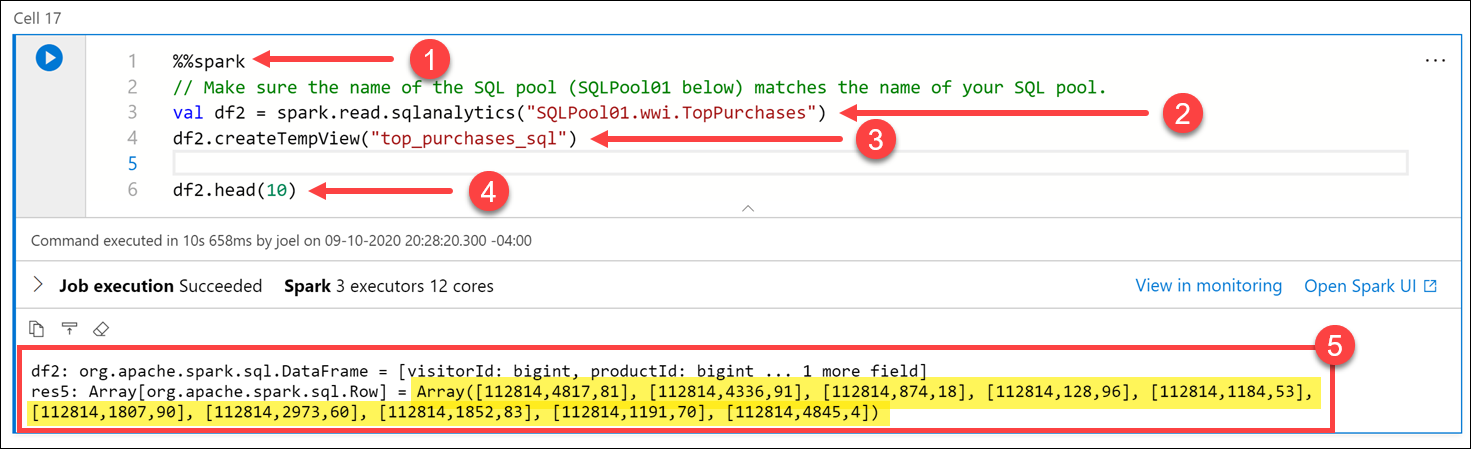
Cellens språk är inställt på
Scalamed hjälp av magin%%spark(1) överst i cellen. Vi deklarerade en ny variabel med namnetdf2som en ny DataFrame som skapats avspark.read.sqlanalyticsmetoden, som läser frånTopPurchasestabellen (2) i SQL-poolen. Sedan fyllde vi i en ny tillfällig vy med namnettop_purchases_sql(3). Slutligen visade vi de första 10 posterna meddf2.head(10))raden (4). Cellutmatningen visar DataFrame-värdena (5).Kör koden nedan i en ny cell för att skapa en ny DataFrame i Python från den
top_purchases_sqltillfälliga vyn och visa sedan de första 10 resultaten:dfTopPurchasesFromSql = sqlContext.table("top_purchases_sql") display(dfTopPurchasesFromSql.limit(10))
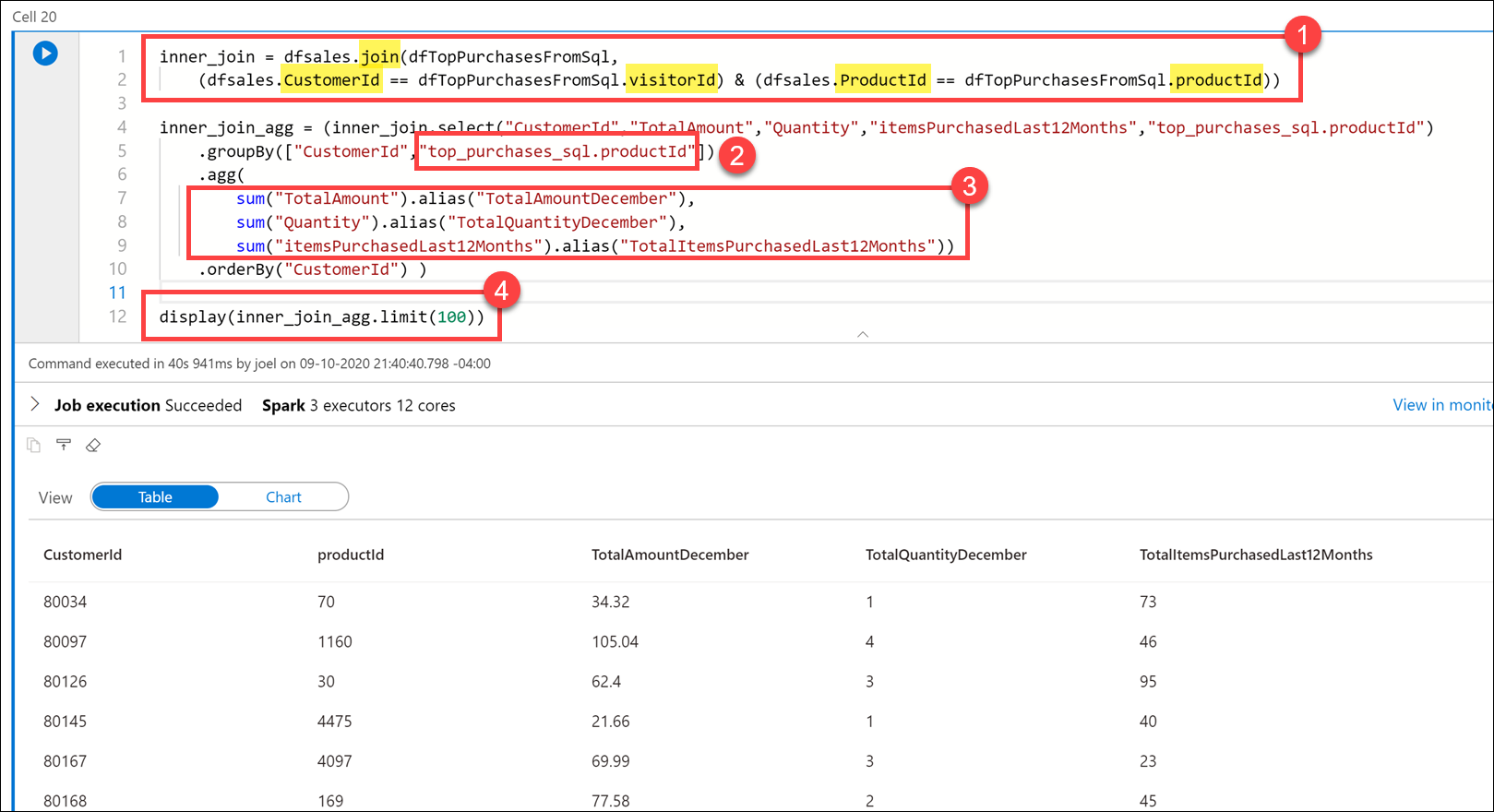
Kör koden nedan i en ny cell för att koppla data från Parquet-försäljningsfilerna
TopPurchasesoch SQL-poolen:inner_join = dfsales.join(dfTopPurchasesFromSql, (dfsales.CustomerId == dfTopPurchasesFromSql.visitorId) & (dfsales.ProductId == dfTopPurchasesFromSql.productId)) inner_join_agg = (inner_join.select("CustomerId","TotalAmount","Quantity","itemsPurchasedLast12Months","top_purchases_sql.productId") .groupBy(["CustomerId","top_purchases_sql.productId"]) .agg( sum("TotalAmount").alias("TotalAmountDecember"), sum("Quantity").alias("TotalQuantityDecember"), sum("itemsPurchasedLast12Months").alias("TotalItemsPurchasedLast12Months")) .orderBy("CustomerId") ) display(inner_join_agg.limit(100))I frågan anslöt vi till
dfsalesdataramarna ochdfTopPurchasesFromSqloch matchade påCustomerIdochProductId. I denna koppling kombineradesTopPurchasesSQL-poolens tabelldata med Parquet-data för försäljning i december 2019 (1).Vi grupperade efter fälten
CustomerIdochProductId.ProductIdEftersom fältnamnet är tvetydigt (det finns i båda DataFrames) var vi tvungna att fullständigt kvalificeraProductIdnamnet för att referera till det iTopPurchasesDataFrame (2).Sedan skapade vi ett aggregat som summerade det totala beloppet som spenderades på varje produkt i december, det totala antalet produktartiklar i december och det totala antalet produktartiklar som köpts under de senaste 12 månaderna (3).
Slutligen visade vi anslutna och aggregerade data i en tabellvy.
Välj kolumnrubrikerna i tabellvyn för att sortera resultatuppsättningen.