Spara berikade data i ett kunskapslager
Ett kunskapslager är beständig lagring av berikat innehåll. Syftet med ett kunskapslager är att lagra data som genereras från AI-berikning i en container. Du kanske till exempel vill spara resultatet av en AI-kompetensuppsättning som genererar bildtext från bilder.
Kom ihåg att kunskapsuppsättningar flyttar ett dokument genom en sekvens med berikningar som anropar transformeringar, till exempel att känna igen entiteter eller översätta text. Resultatet kan vara ett sökindex eller projektioner i ett kunskapslager. De två utdata, sökindex och kunskapslager, är ömsesidigt uteslutande produkter av samma pipeline. härleds från samma indata, men resulterar i utdata som är strukturerade, lagrade och används i olika program.
Fokus för en Azure AI Search-lösning är vanligtvis att skapa ett sökbart index, men du kan också dra nytta av dess funktioner för extrahering och berikande av data för att bevara berikade data i ett kunskapslager för vidare analys eller bearbetning.
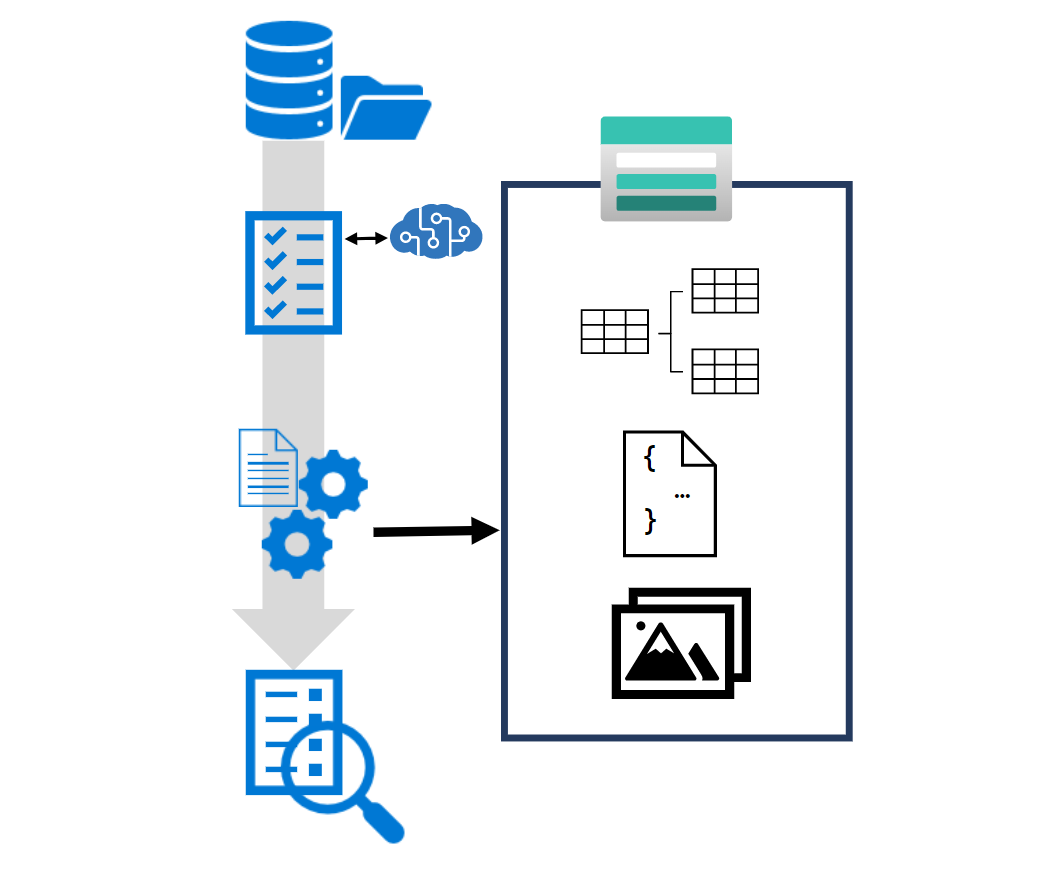
Ett kunskapslager kan innehålla en eller flera av tre typer av projektion av extraherade data:
- Tabellprojektioner används för att strukturera extraherade data i ett relationsschema för frågor och visualisering
- Objektprojektioner är JSON-dokument som representerar varje dataentitet
- Filprojektioner används för att lagra extraherade bilder i JPG-format