DevOps för maskininlärning
DevOps och MLOps
DevOps beskrivs som union av personer, processer och produkter för att möjliggöra kontinuerlig leverans av värde till våra slutanvändare, av Donovan Brown i Vad är DevOps?.
För att förstå hur det används när du arbetar med maskininlärningsmodeller ska vi utforska några viktiga DevOps-principer ytterligare.
DevOps är en kombination av verktyg och metoder som hjälper utvecklare att skapa robusta och reproducerbara program. Målet med att använda DevOps-principer är att snabbt leverera värde till slutanvändaren.
Om du enklare vill leverera värde genom att integrera maskininlärningsmodeller i pipelines för datatransformering eller realtidsprogram kan du använda DevOps-principer. Genom att lära dig mer om DevOps kan du organisera och automatisera ditt arbete.
Att skapa, distribuera och övervaka robusta och reproducerbara modeller för att leverera värde till slutanvändaren är målet med maskininlärningsåtgärder (MLOps).
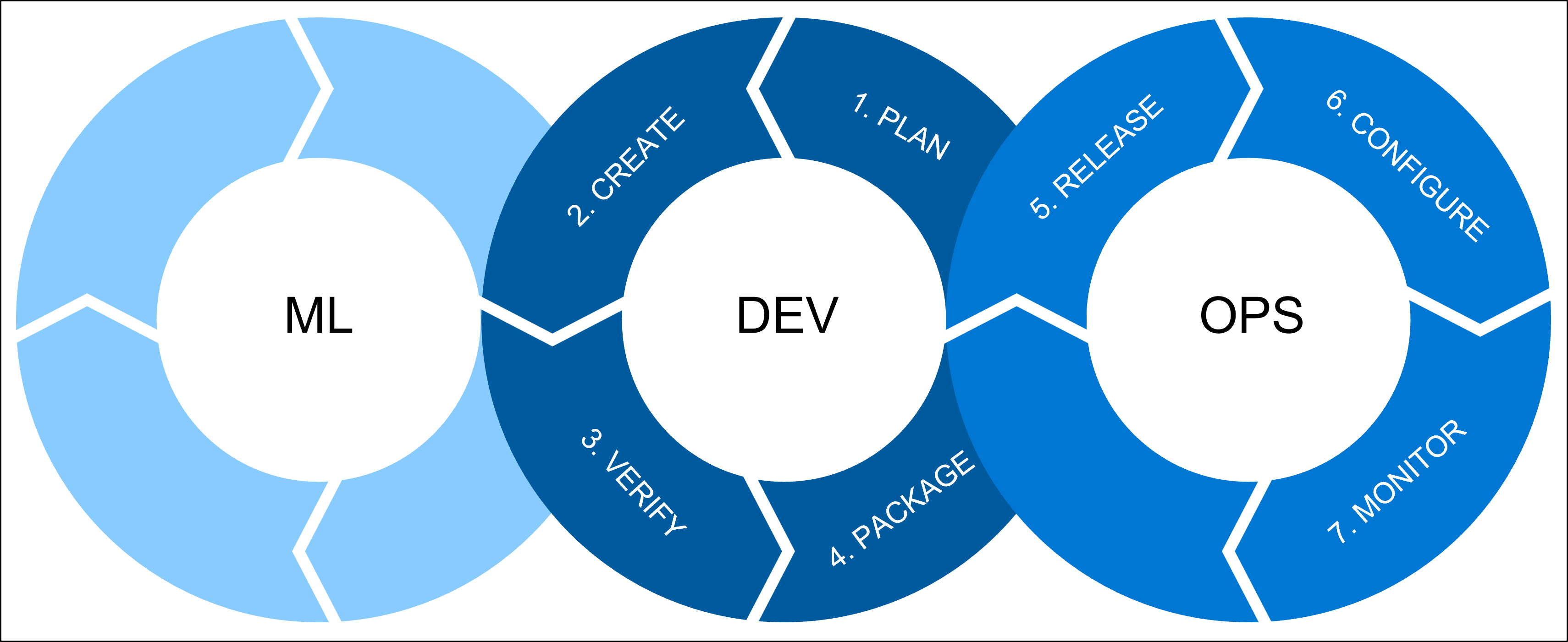
Det finns tre processer som vi vill kombinera när vi pratar om maskininlärningsåtgärder (MLOps):
ML- innehåller alla maskininlärningsarbetsbelastningar som en dataexpert ansvarar för. En dataexpert kommer att göra:
- Undersökande dataanalys (EDA)
- Funktionsutveckling
- Modellträning och justering
DEV- avser programvaruutveckling, som omfattar:
- Plan: Definiera modellens krav och prestandamått.
- Skapa: Skapa modelltränings- och bedömningsskripten.
- Verifiera: Kontrollera kod- och modellkvaliteten.
- Package: Gör dig redo för distribution genom att mellanlagra lösningen.
OPS- avser åtgärder och omfattar:
- Release: Distribuera modellen till produktion.
- Konfigurera: Standardisera infrastrukturkonfigurationer med Infrastruktur som Kod (IaC).
- Övervaka: Spåra mått och se till att modellen och infrastrukturen fungerar som förväntat.
Låt oss gå över några DevOps-principer som är viktiga för MLOps.
DevOps-principer
En av huvudprinciperna i DevOps är automation. Genom att automatisera uppgifter strävar vi efter att få nya modeller distribuerade till produktion snabbare. Genom att automatisera skapar du även reproducerbara modeller som är tillförlitliga och konsekventa i olika miljöer.
Särskilt när du vill förbättra din modell regelbundet över tid kan du med automatisering snabbt utföra alla nödvändiga aktiviteter för att säkerställa att modellen i produktion alltid är den modell som fungerar bäst.
Ett nyckelkoncept för automatisering är CI/CD-, som står för kontinuerlig integrering och kontinuerlig leverans.
Kontinuerlig integrering
Kontinuerlig integrering omfattar aktiviteterna skapa och verifiera. Målet är att skapa koden och att verifiera kvaliteten på både koden och modellen genom automatiserad testning.
Med MLOps kan kontinuerlig integrering omfatta:
- Omstrukturera undersökande kod i Jupyter Notebooks till Python- eller R-skript.
- Linting för att söka efter programmeringsmässiga eller stilistiska fel i skript för Python eller R. Kontrollera till exempel om en rad i skriptet innehåller färre än 80 tecken.
- Enhetstestning för att kontrollera prestanda för innehållet i skripten. Kontrollera till exempel om modellen genererar korrekta förutsägelser på en testdatauppsättning.
Tips
Lär dig hur du konverterar maskininlärningsexperiment till produktionsklar Python-kod
Om du vill utföra lintning och enhetstestning kan du använda automatiseringsverktyg som Azure Pipelines i Azure DevOpseller GitHub Actions.
Kontinuerlig leverans
När du har verifierat kodkvaliteten för Python- eller R-skripten som används för att träna modellen vill du ta modellen till produktion. Kontinuerlig leverans omfattar de steg du behöver vidta för att distribuera en modell till produktion, helst automatisera så mycket som möjligt.
Om du vill distribuera en modell till produktion vill du först paketera den och distribuera den till en förproduktionsmiljö. Genom att etablera modellen i en förproduktionsmiljö kan du kontrollera om allt fungerar som förväntat.
När distributionen av modellen till mellanlagringsfasen lyckas och utan fel kan du godkänna att modellen distribueras till produktionsmiljö.
Om du vill samarbeta med Python- eller R-skripten för att träna modellen och eventuell nödvändig kod för att distribuera modellen till varje miljö använder du källkontroll.
Källkontroll
Källkontroll (eller versionskontroll) uppnås oftast genom att arbeta med en Git-baserad lagringsplats. En lagringsplats refererar till platsen där alla relevanta filer till ett programvaruprojekt kan lagras.
Med maskininlärningsprojekt har du förmodligen en lagringsplats för varje projekt du har. Lagringsplatsen innehåller bland annat Jupyter-notebook-filer, träningsskript, bedömningsskript och pipelinedefinitioner.
Not
Helst bör du inte lagra träningsdata i ditt arkiv. I stället lagras träningsdata i en databas eller datasjö och Azure Machine Learning hämtar data direkt från datakällan med hjälp av datalager.
Git-baserade lagringsplatser är tillgängliga med hjälp av Azure Repos i Azure DevOps eller en GitHub-lagringsplats.
Genom att vara värd för all relevant kod på en lagringsplats kan du enkelt samarbeta med kod och spåra eventuella ändringar som en gruppmedlem gör. Varje medlem kan arbeta med sin egen version av koden. Du kommer att kunna se alla tidigare ändringar och du kan granska ändringarna innan de checkas in på huvudlagringsplatsen.
För att avgöra vem som arbetar med vilken del av projektet rekommenderar vi att du använder flexibel planering.
Agil planering
Eftersom du vill att en modell snabbt ska distribueras till produktion är flexibel planering idealisk för maskininlärningsprojekt.
agil planering innebär att du isolerar arbetet till sprintar. Sprints är korta tidsperioder under vilka du vill uppnå en del av projektets mål.
Syftet är att planera sprintar för att snabbt förbättra någon av koden. Oavsett om det är kod som används för data- och modellutforskning eller för att distribuera en modell till produktion.
Att träna en maskininlärningsmodell kan vara en aldrig sinande process. Som dataexpert kan du till exempel behöva förbättra modellens prestanda på grund av dataavvikelse. Eller så måste du justera modellen så att den bättre överensstämmer med nya affärskrav.
För att undvika att lägga för mycket tid på modellträning kan flexibel planering hjälpa till att begränsa projektet och hjälpa alla att anpassa sig genom att komma överens om kortsiktiga resultat.
Om du vill planera ditt arbete kan du använda ett verktyg som Azure Boards i Azure DevOps eller GitHub-problem.
Infrastruktur som kod (IaC)
Att tillämpa DevOps-principer på maskininlärningsprojekt innebär att du vill skapa robusta reproducerbara lösningar. Med andra ord, allt du gör eller skapar bör du kunna upprepa och automatisera.
Om du vill upprepa och automatisera infrastrukturen som behövs för att träna och distribuera din modell använder teamet infrastruktur som Code (IaC). När du tränar och distribuerar modeller i Azure innebär IaC att du definierar alla Azure-resurser som behövs i processen i koden och att koden lagras på en lagringsplats.
Tips
Bekanta dig mer med DevOps genom att utforska Microsoft Learn-modulerna på DevOps-omvandlingsresan