Skydda AI för en stark grund
AI erbjuder enorma möjligheter – men att låsa upp dess värde kräver en säker grund. När organisationer antar AI står de inför nya risker kring datasekretess, efterlevnad och ansvarsfull användning. Den här lektionen ger praktisk vägledning för beslutsfattare i företag att använda AI på ett säkert sätt genom att implementera styrningsstrategier och säkerhetsåtgärder som skyddar din organisation samtidigt som innovation möjliggörs. Du lär dig hur du identifierar vanliga risker och tillämpar beprövade metoder för att minimera dem, vilket säkerställer att AI-implementering är säkert, etiskt och i linje med affärsprioriteringar.
Förstå ai-affärsrisker
AI låser upp otroliga möjligheter för organisationer, men det medför också nya risker. Några av de viktigaste affärsutmaningarna som varje ledare behöver ta itu med är:
-
Dataläckage och överdelning. 80% av ledare fruktar känslig information som glider genom sprickorna. Utan ordentlig tillsyn kan anställdas användning av icke godkända verktyg (skugg-AI) exponera känslig information och öka risken för överträdelser.
- Efterlevnadsutmaningar. 52% ledare medger att de är osäkra på hur de ska navigera i förändrade AI-regler. Att hålla sig kompatibel är inte bara en ruta att markera– det är viktigt att skydda innovationen och undvika kostsamma motgångar.
Kom igång med en stegvis metod
Riskerna är verkliga , men de är hanterbara med rätt plan. I stället för att rusa in i AI-implementeringen bör organisationer börja med en stark grund och framsteg i faser för att maximera ROI och minimera exponeringen.
Microsofts AI Adoption Framework innehåller en tydlig översikt. Det börjar med AI-strategi och planering – att anpassa affärsmålen till AI-möjligheter. När din strategi har definierats mappar du scenarier för varje område i organisationen. Säkerhets- och affärsteam måste samarbeta för att säkerställa att innovation inte äventyrar efterlevnad eller förtroende.
Därifrån fokuserar du på tre viktiga faser: Styrning, Säker och Hantera.
Reglera AI
Upprätta principer, skyddsräcken och ansvar för ansvarsfull användning. Börja med att skapa styrningsramverk för att styra hur AI används i hela organisationen. I den här fasen ingår att definiera principer för ansvarsfull AI-användning, bedöma risker som är knutna till AI-arbetsbelastningar och tillämpa riktlinjer för att anpassa sig till etiska standarder, regelkrav och affärsmål. Automatisera policytillämpning där det är möjligt inom AI-distributioner för att minska risken för mänskliga misstag. Utvärdera regelbundet var automatisering kan förbättra principefterlevnad.
Säker AI
Skydda data, modeller och arbetsflöden med säkerhet och efterlevnad i företagsklass. Prioritera sedan att skydda AI-system för att skydda känsliga data, upprätthålla modellintegritet och säkerställa tillgänglighet. Organisationer bör implementera robusta säkerhetskontroller, övervaka nya hot och utföra regelbundna riskbedömningar för att skydda AI-lösningar.
Hantera AI
Övervaka prestanda, identifiera drift och upprätthålla transparens när implementeringen skalar. Fokusera slutligen på att hantera AI-arbetsbelastningar effektivt. Den här fasen omfattar underhåll av AI-modeller, övervakning av prestanda och säkerställande av att systemen förblir tillförlitliga över tid. Standardiserade metoder och regelbundna utvärderingar är viktiga för att förhindra problem som dataavvikelse eller prestandaförsämring.
Genom att följa den här stegvisa metoden kan organisationer använda AI på ett säkert sätt – att låsa upp innovation samtidigt som integritet, efterlevnad och affärsintegritet skyddas.

Styrning av AI
AI-styrning handlar inte bara om att uppfylla regelkrav – det är en holistisk strategi som möjliggör ansvarsfull innovation, skapar intressentförtroende och skapar hållbara konkurrensfördelar. Utan stark styrning riskerar organisationer driftsfel, integritetsintrång, ekonomiska förluster och etiska fallgropar som bias.
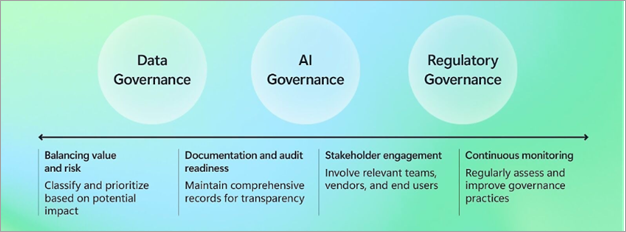
För att lyckas måste styrningen vara enhetlig mellan tre sammankopplade pelare:
- Datastyrning: Säkerställ datakvalitet, säkerhet och efterlevnad i hela dataegendomen.
- AI-styrning: Definiera principer för ansvarsfull utveckling, distribution och övervakning av AI-system.
- Regelstyrning: Fortsätt att utveckla lagar och standarder för att skydda innovation och undvika kostsamma bakslag.
Börja med ett uppifrån och ned-affärsobjektiv. Få reda på problemet du löser och hur framgång ser ut. Börja med "varför" – prioritera AI-investeringar baserat på dina viktigaste affärsmål. Den här metoden säkerställer fokuserade, strategiska initiativ i linje med organisationens mål, vilket gör styrningen till en värdedrivare snarare än ett hinder för innovation.
- Vilken specifik utmaning kommer AI att hantera? Identifiera en specifik affärsutmaning som AI är unikt positionerad att hantera. Förbättrar det kundservicen, automatiserar repetitiva uppgifter, förbättrar cybersäkerheten eller något annat? Var exakt.
- Hur mäter du framsteg och framgång? Definiera tydliga, mätbara mått för att spåra framgången för ai-implementeringen. Vilka nyckeltal (KPI:er) och mål och viktiga resultat (OKR) kommer du att använda för att mäta förloppet? Kommer det att bli ökad effektivitet, minskade kostnader, förbättrad kundnöjdhet eller något annat? Förankra AI-investeringar i affärs-OKR och KPI:er och använd A/B/N-experimenteringsmetoder. Med den här metoden kan du exakt mäta AI:s sanna positiva och sanna negativa inverkan på affärsmålen.
- Vilka konkreta fördelar förväntar du dig att se? Kvantifiera de konkreta fördelar som du förväntar dig att uppnå med AI. Vad är den förväntade avkastningen på investeringen (ROI)? Hur kommer AI att bidra till intäktstillväxt, kostnadsbesparingar eller andra viktiga affärsmål?
Nu när du har en förståelse för dina mål, fördelar och hur du planerar att mäta framgång utvärderar du dina RISKER för AI-organisationen. Riskbedömning omfattar identifiering av potentiella skador, fördomar och säkerhetsrisker.
Datastyrning och säkerhet
Stark datastyrning är avgörande för tillförlitlig AI. Det hjälper till att säkerställa att data aktiveras på ett ansvarsfullt sätt genom principer och processer som upprätthåller kvalitet, säkerhet och efterlevnad under hela livscykeln. Eftersom AI-system bara är lika bra som de data de bygger på kan dålig styrning leda till partiska, felaktiga eller otillförlitliga utdata.
För att skydda din organisation och aktivera ansvarsfull AI prioriterar du dessa principer i hela företaget – som hanteras av dina säkerhets- eller IT-team:
- Respektera åtkomstbehörigheter. AI-verktyg bör endast komma åt data som användaren har behörighet att visa. Åtkomstbehörighet hjälper till att säkerställa att både data som matas in och det innehåll som genereras följer befintliga behörigheter.
- Respektera dataklassificeringar och etiketteringsprinciper. AI-verktyg måste följa åtkomstbegränsningar baserat på dataetiketter. Känsliga eller konfidentiella data bör förbli skyddade enligt organisationens principer.
- Märka AI-genererat innehåll på rätt sätt. Utdata som skapas av AI bör innehålla etiketter som återspeglar källdatas känslighet. Om indata till exempel klassificeras som "konfidentiella" bör det genererade innehållet också märkas som "konfidentiellt".
När du utformar din datasäkerhetsstrategi för AI-implementering bör du ha dessa prioriteringar i centrum:
- Dataklassificering och skydd är inte förhandlingsbara för AI i stor skala.
- Upprätta en stark grund för klassificering och principer som styr hur AI förbrukar data och delar resultat.
- Mandattransparens i ai-leveranskedjan – utdata bör tydligt referera till sina datakällor.
- Anta Zero Trust-principer och robusta datastyrningsprogram som ryggraden i AI-säkerhet.
- Använd avancerade säkerhetsverktyg som slutpunktsidentifiering och svar (EDR) och dataförlustskydd (DLP) för att hantera åtkomst och förhindra intrång.
- Anpassa standarder och principer för AI-system som stöds av hanteringsrapportering, tvärfunktionella team och automatiserade processer för att minska luckor.
- Implementera organisationsomfattande utbildning och principer för dataklassificering och etikettering för att skapa medvetenhet och ansvarsskyldighet.
Skapa en grund för effektiv AI-styrning
AI-styrning tillhandahåller ramverket för principer och processer som vägleder ansvarsfull implementering, distribution och övervakning av AI-program i hela organisationen. Eftersom AI-system kan påverka verksamheten och kundernas upplevelser avsevärt kan rätt styrning säkerställa att de förblir säkra, transparenta och anpassade till organisationens värden.
En lyckad AI-styrning bygger på två grundläggande element: att upprätta grundläggande principer som vägleder alla AI-aktiviteter och ett omfattande implementeringsramverk som hanterar både AI-livscykeln och intressenternas engagemang.
Upprätta och dokumentera tydliga principer med dina IT- och säkerhetsteam och riktlinjer för utveckling och distribution av AI-system. Detta bidrar till att säkerställa datakvalitet, säkerhet och sekretess. Känna till dina datas ägarskap, åtkomst och användning. Använd en datakatalog för att identifiera, klassificera och hantera dina datatillgångar.
När du har dina principer på plats är det dags att skapa ditt styrningsteam. Effektiv AI-styrning kräver indata och samarbete från alla delar av verksamheten för att säkerställa att AI-system utvecklas och distribueras på ett ansvarsfullt sätt. För att underlätta skapar du en dedikerad AI-styrningskommitté med representanter från viktiga avdelningar. Denna kommitté bör omfatta medlemmar från: IT, juridik, efterlevnad, företag, riskhantering och personal. Och slutligen, stärk dina medarbetare. Dina anställda är din största tillgång i AI-eran. Förse dem med de kunskaper, verktyg och den vägledning de behöver för att använda AI på ett ansvarsfullt och effektivt sätt.
Du bör:
- Tillhandahålla riktad utbildning om AI-läs- och skrivkunnighet, ansvarsfulla AI-principer, datahantering och riskerna med skugg-AI. Se till att medarbetarna förstår både fördelarna och potentiella fallgropar med AI-teknik.
- Låt ditt team erbjuda ett urval av godkända AI-verktyg som uppfyller organisationens IT-, säkerhets-, efterlevnads- och etiska standarder. Komplettera med tydliga principer som beskriver acceptabel användning.
- Främja en kultur där anställda känner sig bemyndigade att ge feedback – både positiva och negativa – om AI-system och processer. Använd deras insikter för att förfina verktyg, principer och styrningsramverk över tid.
För att säkerställa att din styrning av AI-programmet förblir effektiv och anpassningsbar över tid övervakar du kontinuerligt AI-system för potentiella risker och justerar dina styrningsprinciper efter behov.
Håll dig i framkant med att uppfylla kraven för regelstyrning
Regelstyrning hjälper till att säkerställa att AI-system följer nya lagar och standarder samtidigt som ansvarsfull innovation demonstreras. När globala regler för AI ändras snabbt är proaktiv efterlevnad avgörande – inte bara för att undvika påföljder, utan för att minska den rättsliga risken och bygga upp intressentförtroende.
För att uppfylla dessa förväntningar krävs en "skift-vänster"-metod för efterlevnad – inbäddning av regelöverväganden tidigt i design- och utvecklingsprocessen i stället för att behandla dem som en eftertanke. Den här strategin hjälper organisationer att röra sig snabbare samtidigt som de håller sig i linje med etiska och juridiska krav.
Att navigera i det här komplexa landskapet är viktigt för långsiktig framgång. Det här avsnittet bygger på grundprinciperna för AI-styrning och utforskar praktiska strategier och insikter för att uppfylla och överskrida regelefterlevnadskrav när du skalar AI på ett ansvarsfullt sätt.
Skapa en stark grund för AI-efterlevnad
Effektiv efterlevnad går utöver kryssrutor – det kräver en holistisk metod som integrerar:
- Datasekretess.
- Algoritmisk rättvisa.
- Genomskinlighet.
- Redovisningsansvar.
- Robusta säkerhetsåtgärder.
Allt börjar med att känna till dina data och förstå de regelkrav som formar ansvarsfull AI.
Ramverk som EU:s AI-lag, allmänna dataskyddsförordningar och sektorsspecifika förordningar som lagen om digital driftsresiliens och direktivet om nätverks- och informationssäkerhet ger viktig vägledning för att skapa AI-system som är säkra, etiska och respekterar grundläggande rättigheter. Att anpassa sig till dessa standarder tidigt hjälper organisationer att förnya sig på ett säkert sätt samtidigt som riskerna minimeras.
Navigera genom AI-efterlevnadsbestämmelser
Det är viktigt att skapa en tydlig, åtgärdsbar plan för att uppfylla regelkraven och skala AI på ett ansvarsfullt sätt. Börja med följande grundläggande steg:
- Fästpunkt i grundläggande föreskrifter. Använd ramverk som EU AI Act och GDPR som baslinje för ditt efterlevnadsprogram. Dessa ramverk ger tydlig vägledning om riskklassificering, dataskydd, transparens och mänsklig tillsyn. Se branschresurser för uppdateringar och metodtips.
- Utför en gapanalys. Utvärdera din nuvarande efterlevnadsstatus och identifiera områden för förbättring – särskilt för högriskdata och AI-projekt. Använd verktyg för efterlevnadshantering för att utvärdera risker och stänga styrningsluckor.
- Odla en förstärkt efterlevnadskultur. Gå längre än minimikraven. Bädda in ansvarsfulla AI-principer i din kultur genom regelbunden utbildning, pågående granskningar och konsekvensbedömningar som utvärderar hur AI-system påverkar människor, organisationer och samhället.
- Välj certifierade verktyg. Välj AI-lösningar som certifierats mot erkända standarder, till exempel ISO 42001. Prioritera verktyg som skapats med säkerhet och sekretess genom design och som är anpassade till ansvarsfulla AI-principer.
- Automatisera efterlevnadsövervakning. Använd AI-drivna plattformar för att kontinuerligt övervaka efterlevnaden av standarder. Fokusera på datahemvist, suveränitet, sekretess och kvarhållning. Genom att automatisera efterlevnaden kan du ligga steget före regeländringar och minska risken.
Att skydda AI är inte bara ett tekniskt krav – det är ett strategiskt imperativ. Genom att hantera risker som dataläckage och efterlevnadsutmaningar, implementera stegvis styrning och bädda in säkerhet i varje lager av AI-implementering kan organisationer förnya sig på ett säkert sätt samtidigt som förtroende och efterlevnad skyddas. En stark grund som bygger på styrning, säkerhet och regelanpassning hjälper till att säkerställa att AI levererar värde utan onödiga risker.
Mer information finns i följande resurser:
- Microsoft-guide för att skydda det AI-baserade företaget: Komma igång med AI-program
- Microsofts guide för att säkra AI-drivna företag: Strategier för AI-styrning
- Microsoft-handbok för att säkerställa säkerheten för AI-driven verksamhet: Strategier för efterlevnad av AI
- Microsoft AI Adoption Framework
Testa sedan dina kunskaper med ett kort test.