Utföra nodunderhåll
Contosos aktuella standardrutiner utformades för äldre arbetsbelastningar, som främst körs på Windows Server 2012 R2 och äldre versioner av Linux-distributioner. De tar inte hänsyn till de överväganden som gäller för Azure Stack HCI-virtualiserings- och klustertekniker. Som en del av utvärderingen av Azure Stack HCI bestämmer du dig för att testa och dokumentera vanliga underhållsaktiviteter som innebär att starta om enskilda Azure Stack HCI-klusternoder eller tillfälligt ta dem offline för underhåll.
Översikt över underhållsaktiviteter för Azure Stack HCI-kluster
Azure Stack HCI erbjuder inbyggd återhämtning och skyddar sina arbetsbelastningar från effekten av maskinvarufel för enskilda komponenter, inklusive upp till två klusternoder. Det finns dock specifika riktlinjer som du bör följa när du avsiktligt startar om klusternoder eller tar dem offline för planerat underhåll.
Behovet av de specifika riktlinjerna beror på att varje nod i ett Azure Stack HCI-kluster inte bara tillhandahåller beräkningsresurser, utan även är värd för lagringsvolymer som distribueras och synkroniseras över flera klusternoder. Om du stänger av en klusternod störs den här synkroniseringen. Därför måste alla ändringar av lokala repliker av klustrade volymer som sker medan noden är offline synkroniseras om när nodens operativsystem börjar köras igen.
Ett annat viktigt övervägande är det maximala antalet klusternoder som kan vara offline samtidigt utan att orsaka dataförlust. Som beskrivs tidigare i den här modulen tolererar Lagringsdirigering högst två samtidiga nodfel för fyra eller fler noder med vittne, oavsett klusterstorlek.
Om du vill utföra ett klusternodunderhåll på ett ordnat sätt med minimal påverkan på övergripande återhämtning och prestanda bör du använda följande stegsekvens:
Kontrollera att alla klusterlagringsdiskar är online och att alla klusterlagringsvolymer rapporterar felfri status.
Pausa noden för att utlösa direktmigrering av alla virtuella datorer som körs på noden till andra klusternoder.
Kommentar
Den här processen kallas för tömning. När tömningsprocessen har startat går det inte att lägga till roller i noden förrän noden återupptas.
Stäng av operativsystemet på klusternoden.
Utför de planerade underhållsaktiviteterna medan operativsystemet är offline.
Starta operativsystemet och vänta tills startprocessen har slutförts.
Återuppta klusternoden.
Kommentar
Om du återupptar klusternoden startas lagringssynkroniseringen om (kallas ofta för omsynkronisering. Kontrollera att klusterlagringsvolymerna rapporterar felfri status igen för att avgöra om om omsynkronisering har slutförts.
Kommentar
Du bör vänta tills omsynkronisering har slutförts innan du tar andra klusternoder offline.
Utföra underhållsuppgifter för Azure Stack HCI-kluster med hjälp av Windows Admin Center
Windows Administrationscenter gör det enklare att initiera och slutföra underhållsaktiviteter för klusternoder genom att tillhandahålla ett grafiskt gränssnitt för att implementera de steg som krävs:
När du har anslutit till målklustret för att kontrollera att alla diskar visas med onlinestatus (märkt OK) använder du menyn Verktyg för att bläddra till fönstret Lagring för att visa inventeringen av diskar.
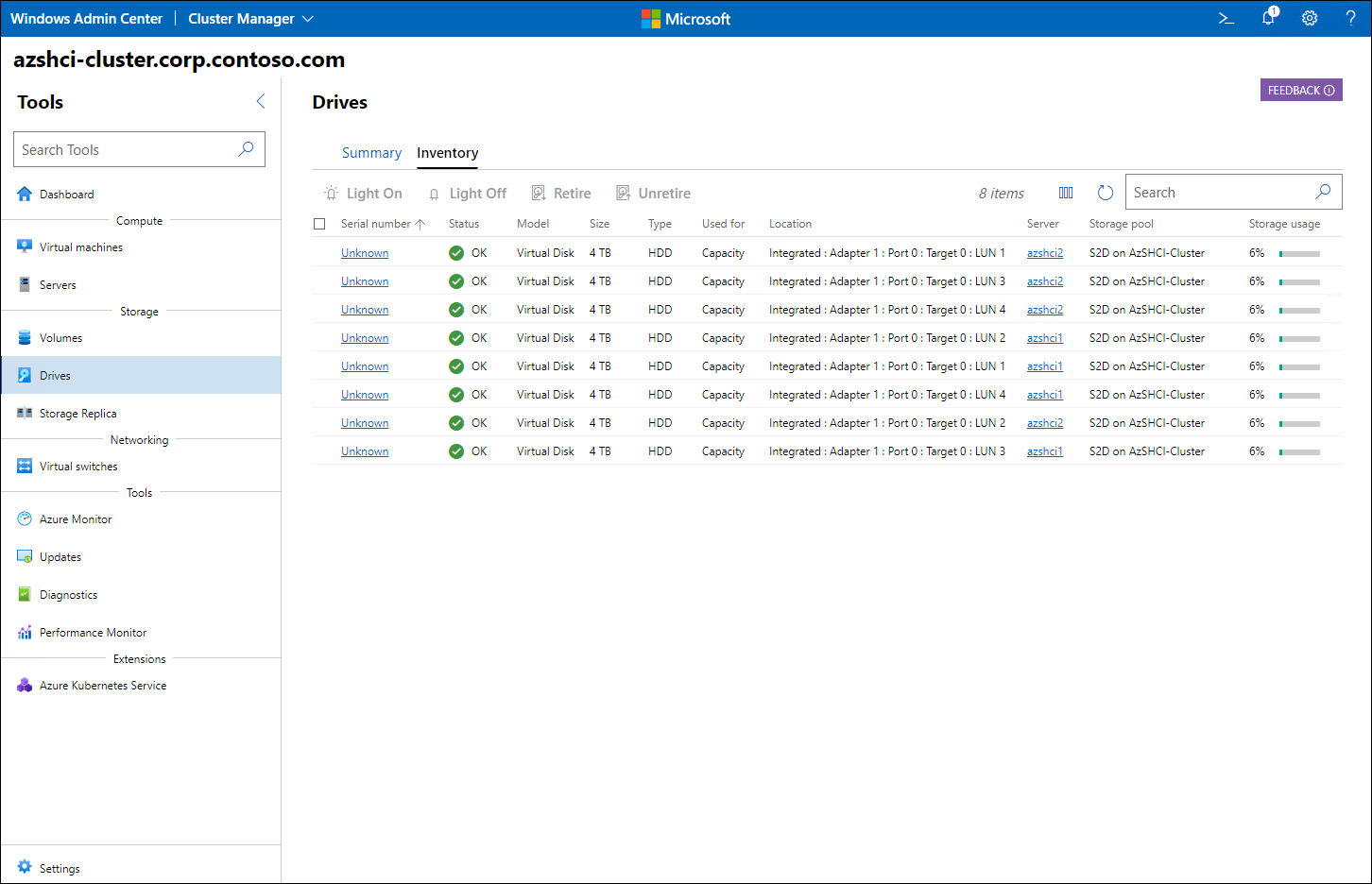
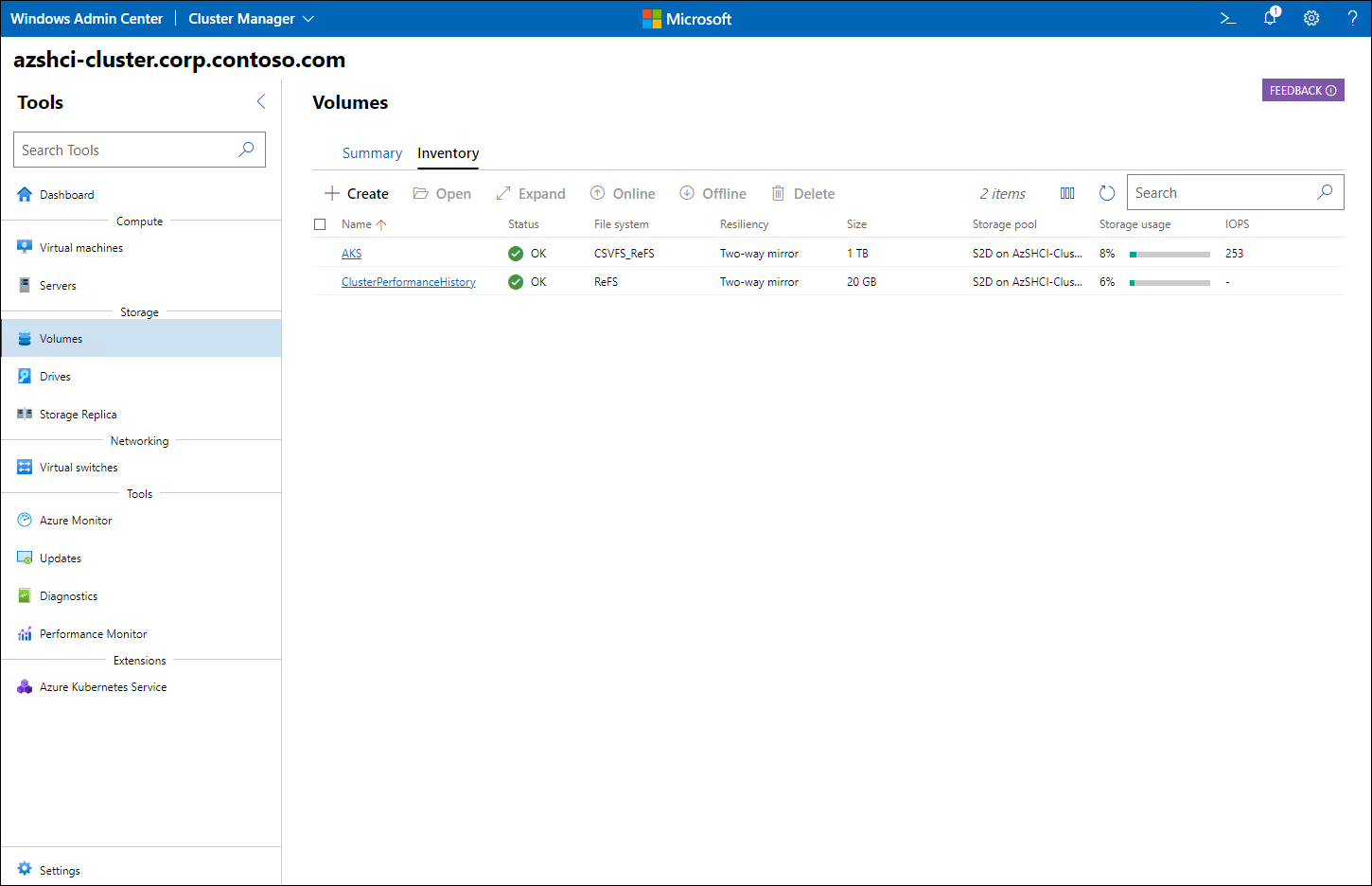
I fönstret Lagring kan du komma åt listan med volymer för att kontrollera att varje volym visas med felfri status (märkt OK).
Från Cluster Manager-gränssnittet i Windows Administrationscenter kan du bläddra till fönstret Beräkning , visa serverinventeringen och pausa någon av klusternoderna för att initiera tömningsprocessen.
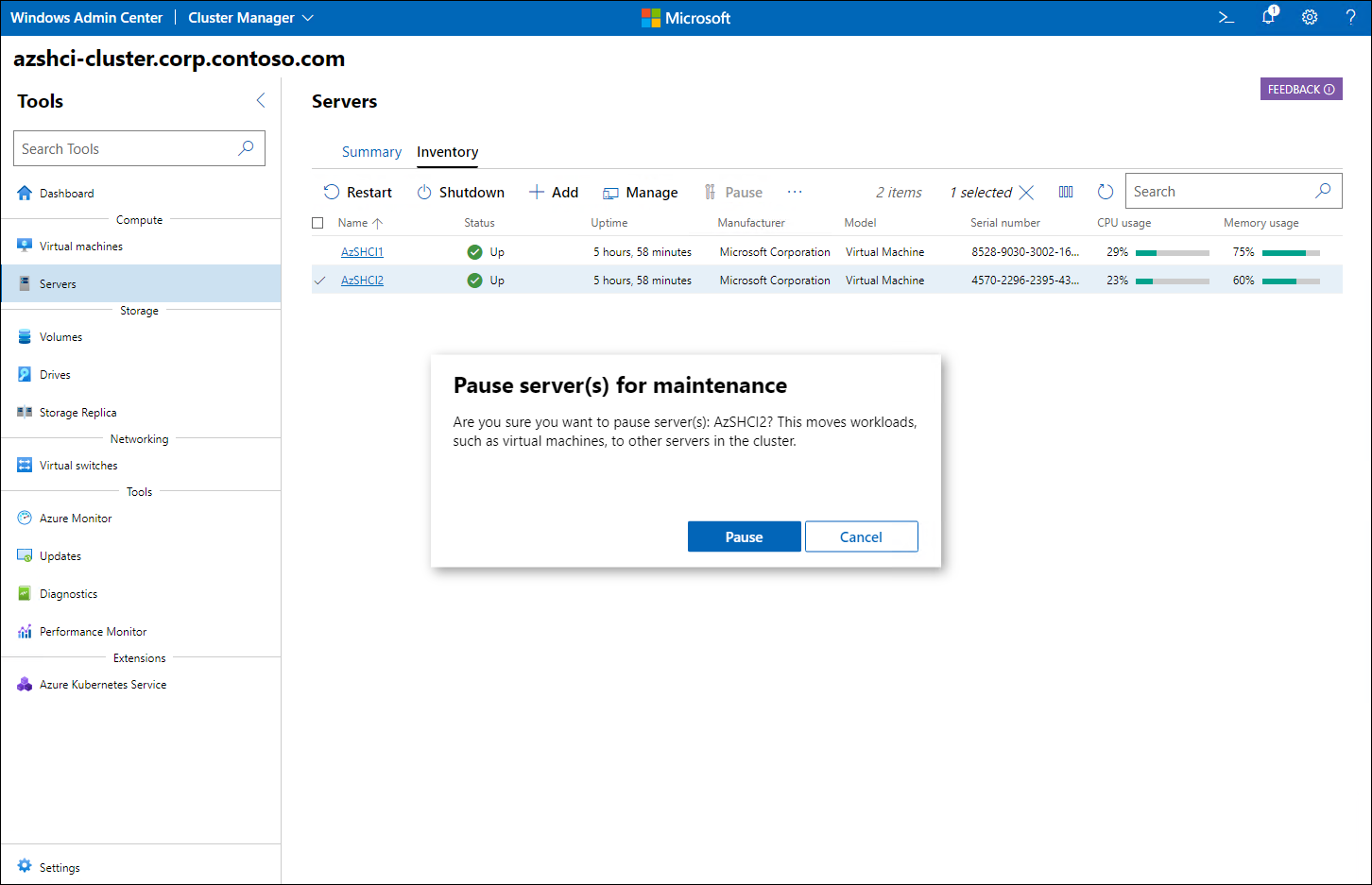
Kommentar
Under pausning av en klusternod övergår nodstatusen från Under underhåll, Tömning till Under underhåll slutförs Tömning.
Kommentar
Azure Stack HCI genererar en avisering och stoppar tömningsprocessen om statusen för någon av klusterlagringsvolymerna ändras till felaktig.
Du kan återuppta klusternoden från samma gränssnitt som du använde för att pausa den.