Förklara Apache Spark i Azure Synapse Analytics
Apache Spark är ett distribuerat system med öppen källkod som används för bearbetning av stordataarbetsbelastningar. Stordataarbetsbelastningar definieras som arbetsbelastningar för att hantera data som är för stora eller komplexa för traditionella databassystem. Apache Spark bearbetar stora mängder data i minnet, vilket ökar prestandan för att analysera stordata mer effektivt, och den här funktionen är tillgänglig i Azure Synapse Analytics och kallas Spark-pooler.
För att uppnå den här funktionen är Spark-poolkluster grupper av datorer som behandlas som en enda dator och hanterar körningen av kommandon som utfärdas från notebook-filer. Klustren gör att bearbetning av data kan parallelliseras mellan många datorer för att förbättra skalning och prestanda. Den består av en Spark-drivrutin och arbetsnoder. Noden Drivrutin skickar arbete till arbetsnoderna och instruerar dem att hämta data från en angiven datakälla. Dessutom kan du konfigurera antalet noder som krävs för att utföra uppgiften.
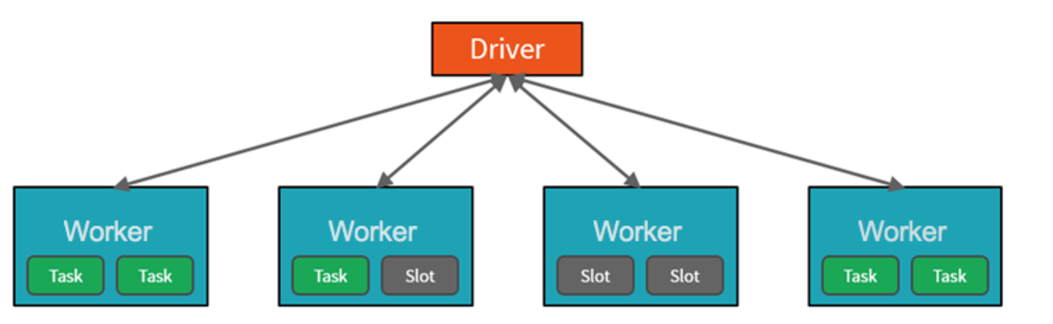
Spark-pooler i Azure Synapse Analytics erbjuder en fullständigt hanterad Spark-tjänst. Fördelarna med att skapa en Spark-pool i Synapse Analytics är bland annat.
Hastighet och effektivitet
Spark-instanser startar på cirka 2 minuter för färre än 60 noder och cirka 5 minuter för fler än 60 noder. Instansen stängs som standard av 5 minuter efter att det senaste jobbet kördes, såvida det inte hålls vid liv av en notebook-anslutning.
Enkelt att skapa
Du kan skapa en ny Spark-pool i Azure Synapse på några minuter med hjälp av Azure-portalen, Azure PowerShell eller Synapse Analytics .NET SDK.
Användarvänlighet
Synapse Analytics innehåller en anpassad notebook-fil som härletts från Nteract. Du kan de här anteckningsböckerna för interaktiv databehandling och visualisering.
Skalbarhet
Apache Spark i Azure Synapse-pooler kan ha automatisk skalning aktiverat, så att pooler skalas genom att lägga till eller ta bort noder efter behov. Dessutom kan Spark-pooler avslutas utan dataförlust eftersom alla data lagras i Azure Storage eller Data Lake Storage.
Stöd för Azure Data Lake Storage Generation 2
Spark-pooler i Azure Synapse kan använda Azure Data Lake Storage Generation 2 och BLOB Storage.
Det primära användningsfallet för Apache Spark för Azure Synapse Analytics är att bearbeta stordataarbetsbelastningar som inte kan hanteras av Azure Synapse SQL och där du inte har någon befintlig Apache Spark-implementering.
Du kanske måste utföra en komplex beräkning på stora mängder data. Att hantera det här kravet i Spark-pooler blir mycket effektivare än i Synapse SQL. Du kan skicka data till Spark-klustret för att utföra beräkningen och sedan skicka tillbaka bearbetade data till informationslagret eller tillbaka till datasjön.
Om du redan har en Spark-implementering på plats kan Azure Synapse Analytics även integreras med andra Spark-implementeringar, till exempel Azure Databricks, så du behöver inte använda funktionen i Azure Synapse Analytics om du redan har en Spark-konfiguration.
Slutligen kommer Spark-pooler i Azure Synapse Analytics med förinstallerade Anaconda-bibliotek. Anaconda innehåller nära 200 bibliotek som gör att du kan använda Spark-poolen för att utföra maskininlärning, dataanalys och datavisualisering. Detta kan göra det möjligt för dataforskare och dataanalytiker att interagera med data med hjälp av Spark-poolen också.