Felsöka ett nätverk med hjälp av mått och loggar i Network Watcher
Om du vill kunna diagnostisera ett problem snabbt måste du förstå informationen som visas i Azure Network Watcher-loggarna.
I ditt teknikföretag vill du minimera den tid det tar för personalen att diagnostisera och lösa eventuella problem med nätverkskonfigurationen. Du vill se till att de vet vilken information som är tillgänglig i vilka loggar.
I den här modulen fokuserar vi på flödesloggar, diagnostikloggar och trafikanalys. Du får lära dig hur de här verktygen kan hjälpa dig att felsöka Azure-nätverket.
Användning och kvoter
Du kan använda varje Microsoft Azure-resurs upp till dess kvot. Varje prenumeration har separata kvoter och användningen spåras per prenumeration. Du behöver bara en instans av Network Watcher per prenumeration och region. I den här instansen ser du användning och kvoter så att du kan ser om du börjar närma dig en kvot.
Om du vill visa information om användning och kvoter går du till Alla tjänster>Nätverk>Network Watcher och väljer Användning och kvoter. Du ser detaljerade data baserat på användning och resursernas plats. Data för följande mått samlas in:
- Nätverksgränssnitt
- Nätverkssäkerhetsgrupper (NSG:er)
- Virtuella nätverk
- Offentliga IP-adresser
Här är ett exempel som visar användning och kvoter i portalen:

Loggar
Du ser detaljerad information i loggarna med nätverksdiagnostik. Du kan använda dessa data till att få bättre förståelse för problem med anslutningar och prestanda. Det finns tre verktyg för loggvisning i Network Watcher:
- NSG flödesloggar
- Diagnostikloggar
- Trafikanalys
Nu ska vi gå igenom de här verktygen.
NSG flödesloggar
I NSG-flödesloggar kan du visa information om inkommande och utgående IP-trafik i nätverkssäkerhetsgrupper. Flödesloggar visar utgående och inkommande flöden per regel, baserat på det nätverkskort som flödet gäller. NSG-flödesloggar visar om trafiken tillåtits eller nekats baserat på den insamlade 5-tupeln. Denna information omfattar:
- Käll-IP-adress
- Källport
- Mål-IP-adress
- Målport
- Protokoll
I det här diagrammet visas arbetsflödet som NSG:n följer.
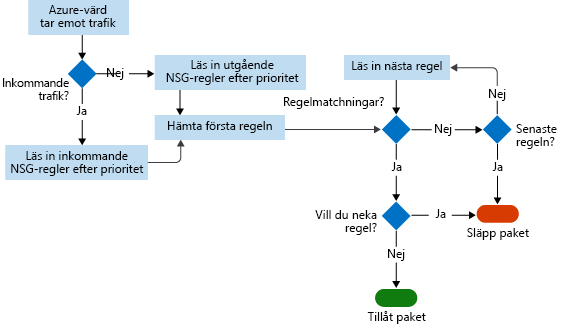
Flödesloggar lagrar data i en JSON-fil. Det kan vara svårt att få insikter om dessa data genom att söka i loggfilerna manuellt, särskilt om den distribuerade infrastrukturen i Azure är stor. Lös problemet genom att använda Power BI.
I Power BI kan du visualisera NSG-flödesloggar på många sätt. Till exempel:
- Främsta kommunikatörer (IP-adress)
- Flöden efter riktning (inkommande och utgående)
- Flöden efter beslut (tillåts och nekas)
- Flöden efter målport
Du kan också använda verktyg med öppen källkod till att analysera dina loggar, som Elastic Stack, Grafana och Graylog.
Kommentar
NSG-flödesloggar har inte stöd för lagringskonton i klassiska Azure Portal.
Diagnostikloggar
I Network Watcher är diagnostikloggar en central plats för att aktivera och inaktivera loggar för Azure-nätverksresurser. Dessa resurser kan innefatta NSG:er, offentliga IP-adresser, lastbalanserare och appgatewayer. När du har aktiverat de loggar du är intresserad av kan du använda verktygen till att köra frågor mot och visa loggposter.
Du kan importera diagnostikloggarna till Power BI och andra verktyg för att analysera dem.
Trafikanalys
Använd trafikanalysen till att undersöka användar- och appaktivitet i dina molnnätverk.
Verktyget ger insikter om nätverksaktiviteten mellan olika prenumerationer. Du kan diagnostisera säkerhetshot som öppna portar, virtuella datorer som kommunicerar med kända skadliga nätverk och mönster i trafikflödena. Trafikanalys analyserar NSG-flödesloggar för flera Azure-regioner och prenumerationer. Du kan använda dessa data till att optimera nätverkets prestanda.
Du behöver Log Analytics för det här verktyget. Log Analytics-arbetsytan måste ligga i en region som stöds.
Användningsfall
Nu ska vi ta en titt på några användningsfall där mått och loggar i Azure Network Watcher kan vara till hjälp.
Kundrapporter om dåliga prestanda
För att kunna lösa dåliga prestanda behöver du fastställa problemets grundorsak:
- Inkommer för mycket trafik så att servern inte hinner med?
- Passar storleken på den virtuella datorn för jobbet?
- Är tröskelvärdena för skalbarhet rätt inställda?
- Sker några skadliga attacker?
- Är den virtuella datorns lagring rätt inställd?
Kontrollera först att storleken på den virtuella datorn är lämplig för jobbet. Aktivera sedan Azure Diagnostics för den virtuella datorn så att du får mer detaljerad information om vissa mått som processoranvändning och minnesanvändning. Om du vill aktivera diagnostik för virtuella datorer via portalen går du till den virtuella datorn, väljer Diagnostikinställningar och aktiverar sedan diagnostiken.
Vi antar att du har en virtuell dator som har körts utan problem. Den virtuella datorns prestanda har emellertid försämrats nyligen. För att kunna identifiera om det finns flaskhalsar bland resurserna måste du granska insamlade data.
Börja med ett tidsintervall för insamlade data före, under och efter det rapporterade problemet för att få en korrekt bild av datorns prestanda. De här diagrammen kan också vara användbara om vi vill göra korsreferenser mellan olika resursers beteenden under samma period. Du söker efter:
- Flaskhalsar som beror på processorer
- Flaskhalsar som beror på minne
- Flaskhalsar som beror på diskar
Flaskhalsar som beror på processorer
När du tittar på prestandaproblem kan du undersöka trender för att förstå om de påverkar servern. Använd övervakningsdiagrammen från portalen för att hitta eventuella trender. Du kan se olika typer av mönster i övervakningsdiagrammet:
- Isolerade toppar. En topp kan bero på en schemalagd aktivitet eller en förväntad händelse. Om du vet vad aktiviteten gäller, körs den på den prestandanivå som krävs? Om prestandan är OK kanske du inte behöver öka kapaciteten.
- Topp som kvarstår. En ny arbetsbelastning kan orsaka den här trenden. Aktivera övervakning för den virtuella datorn och ta reda på vilka processer som orsakar belastningen. Den ökade förbrukningen kan bero på ineffektiv kod eller på den nya arbetsbelastningens normala förbrukning. Om förbrukningen är normal, körs processen på den prestandanivå som krävs?
- Konstant. Har den virtuella datorn körts så här? I så fall bör du identifiera de processer som använder mest resurser och överväga att lägga till kapacitet.
- Stadigt ökande. Ökar förbrukningen konstant? I så fall kan den här trenden tyda på ineffektiv kod eller att en process belastas hårdare av användarna.
Om processoranvändningen är hög kan du antingen:
- Öka storleken på den virtuella datorn så att den skalas med fler kärnor.
- Fortsätt att undersök problemet. Identifiera appen och processen och felsök sedan.
Om du skalar upp den virtuella datorn och processorn fortfarande körs på över 95 procent, är appprestandan bättre eller är appdataflödet högre till en acceptabel nivå? Om inte, kan du felsöka den enskilda appen.
Flaskhalsar som beror på minne
Du kan se hur mycket minne den virtuella datorn använder. Loggarna hjälper dig att förstå trenden och om den kan mappas till den tidpunkt då du ser problemen. Du bör inte ha mindre än 100 MB ledigt minne när som helst. Håll utkik efter följande trender:
- Topp i förbrukningen som kvarstår. Hög minnesförbrukning kanske inte orsakas av dåliga prestanda. En del appar, som t.ex. motorer för relationsdatabaser, är minnesintensiva i sin utformning. Men om det finns flera minneskrävande appar, kan systemets prestanda försämras eftersom minneskonkurrensen orsakar trimning och växling till disk. De här processerna påverkar systemets prestanda negativt.
- Stadigt ökande förbrukning. Trenden kan innebära att en app värmer upp. Det här är vanligt när databasmotorer startar. Men det kan också vara ett tecken på en minnesläcka i en app.
- Användning av växlingsfilen. Kontrollera om du använder växlingsfilen i Windows eller Linux mycket, du hittar den under /dev/sdb.
Du kan överväga följande lösningar om minnesanvändningen är hög:
- Öka storleken på den virtuella datorn och lägg till mer minne om du behöver en snabb lösning på problemen, och fortsätt övervaka.
- Fortsätt att undersök problemet. Leta upp appen eller processen som orsakar flaskhalsen och felsök den. Om du vet vilken app det gäller, kanske du kan begränsa minnesallokeringen.
Flaskhalsar som beror på diskar
Nätverksprestanda kan också gälla den virtuella datorns lagringssystem. Du kan undersöka lagringskontot för den virtuella datorn i portalen. Du kan identifiera problem med lagringen genom att titta på prestandamått från lagringskontots och den virtuella datorns diagnostik. Leta efter trender när problemet inträffar inom ett visst tidsintervall.
- Om du vill kontrollera tidsgränser för Azure Storage använder du måtten ClientTimeOutError, ServerTimeOutError, AverageE2ELatency, AverageServerLatency och TotalRequests. Om du ser värden i TimeOutError-måtten tog en I/O-åtgärd för lång tid och tidsgränsen uppnåddes. Om du ser en ökning av AverageServerLatency samtidigt som TimeOutErrors kan det vara ett plattformsproblem. Öppna ett supportärende hos Microsofts tekniska support.
- Om du vill leta efter begränsningar i Azure Storage du måttet ThrottlingError. Om du ser en begränsning så är IOPS-gränsen för kontot uppnådd. Du kan undersöka det här problemet via måttet TotalRequests.
Så här åtgärdar du problem med hög diskanvändning och långa svarstider:
- Optimera den virtuella datorns I/O för att skala om kring VHD-gränser (virtuell hårddisk).
- Öka dataflödet och minska svarstiden. Om du upptäcker att du har en app som är känsligt för långa svarstider och du behöver hantera stora dataflöden, kan du migrera dina virtuella hårddiskar till Azure Premium Storage.
Brandväggsregler i den virtuella datorn som blockerar trafik
Om du vill felsöka ett NSG-flödesproblem ska du använda Network Watcher-verktyget Kontrollera IP-flöde och NSG-flödesloggar till att avgöra om en nätverkssäkerhetsgrupp eller användardefinierad routning (UDR) stör trafikflödet.
Kör Kontrollera IP-flöde och ange den lokala virtuella datorn och den virtuella fjärrdatorn. När du väljer Kontrollera kör Azure ett logiskt test för de regler som gäller. Om resultatet är att åtkomsten tillåts använder du NSG flödesloggar.
Gå till NSG:erna i portalen. Välj På under flödesloggsinställningarna. Försök nu att ansluta till den virtuella datorn igen. Använd Trafikanalys i Network Watcher till att visualisera data. Om resultatet är att åtkomsten tillåts är det ingen NSG-regel som hindrar.
Om du har kommit ända hit utan att ha lyckats identifiera problemet kan det vara något fel på den virtuella fjärrdatorn. Inaktivera brandväggen på den virtuella fjärrdatorn och testa anslutningen igen. Om du kan ansluta till den virtuella fjärrdatorn när brandväggen är inaktiverad kontrollerar du fjärrdatorns brandväggsinställningar. Aktivera sedan brandväggen igen.
Serverdelens och klientdelens undernät kan inte kommunicera
Som standard kan alla undernät kommunicera i Azure. Om två virtuella datorer i två undernät inte kan kommunicera måste det finnas någon konfiguration som blockerar kommunikationen. Innan du kontrollerar flödesloggarna, kör du verktyget Kontrollera IP-flöde från den virtuella datorn i klientdelen till den virtuella datorn i serverdelen. Det här verktyget kör ett logiskt test för reglerna i nätverket.
Om resultatet är att en NSG i serverdelen blockerar all kommunikation, konfigurerar du om NSG:n. Av säkerhetsskäl måste du blockera en del kommunikation med klientdelen eftersom klientdelen är exponerad för det offentliga internet.
Genom att blockera kommunikation till serverdelen begränsar vi exponeringen mot skadlig kod och säkerhetsattacker. Men om NSG:n däremot blockerar allt är den konfigurerad på fel sätt. Aktivera de protokoll och portar som behövs.