Vad är regression?
Regression är en enkel, vanlig och mycket användbar dataanalysteknik, ofta vardagligt kallad "anpassning av en linje". I sin enklaste form passar regression en rät linje mellan en variabel (funktion) och en annan (etikett). I mer komplicerade former kan regression hitta icke-linjära relationer mellan en enskild etikett och flera funktioner.
Enkel linjär regression
Enkel linjär regression modellerar en linjär relation mellan en enskild funktion och en vanligtvis kontinuerlig etikett, vilket gör att funktionen kan förutsäga etiketten. Visuellt kan det se ut ungefär så här:
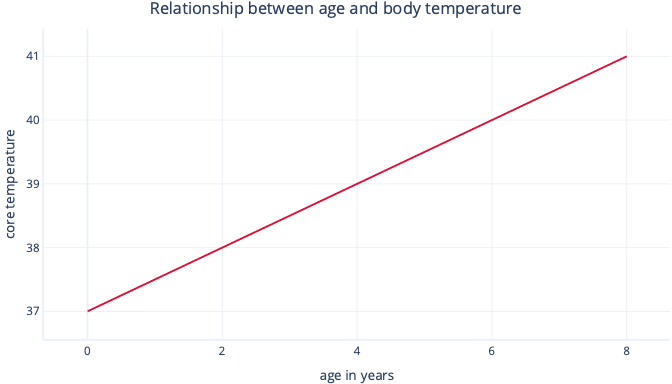
Enkel linjär regression har två parametrar: en skärningspunkt (c), som anger värdet som etiketten är när funktionen är inställd på noll och en lutning (m), som anger hur mycket etiketten kommer att öka för varje enpunktsökning i funktionen.
Om du vill tänka matematiskt är detta helt enkelt:
y=mx+c
Där y är din etikett och x är din funktion.
I vårt scenario skulle vi till exempel ha modellen om vi skulle försöka förutsäga vilka patienter som kommer att få feber – förhöjd kroppstemperatur – baserat på deras ålder:
temperature=m*age+c
Och behöver hitta värdena för m och c under monteringsproceduren. Om vi hittade m = 0,5 och c = 37 kan vi visualisera det så här:
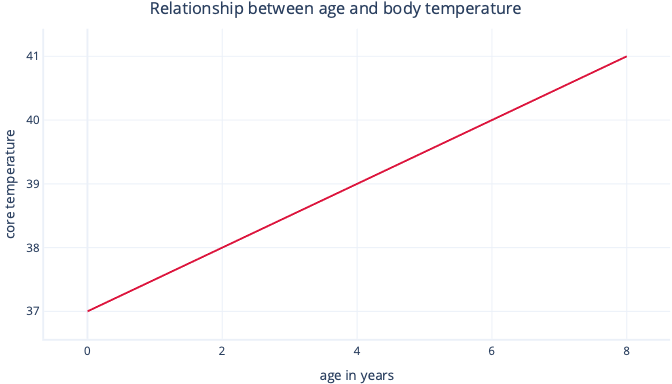
Detta skulle innebära att varje år i ålder är associerad med kroppstemperaturökning på 0,5 °C, med en startpunkt på 37 °C.
Anpassning av linjär regression
Vi använder normalt befintliga bibliotek för att passa regressionsmodeller åt oss. Regression syftar vanligtvis till att hitta den rad som genererar minst antal fel, där felet här innebär skillnaden mellan det faktiska datapunktsvärdet och det förutsagda värdet. I följande bild anger till exempel den svarta linjen felet mellan förutsägelsen (den röda linjen) och ett faktiskt värde (punkten).
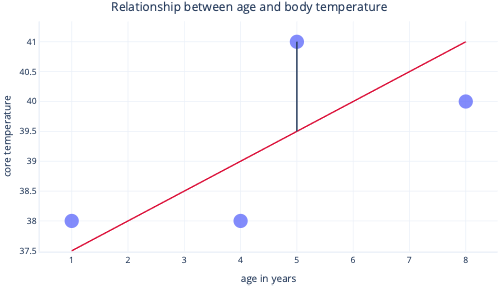
Genom att titta på dessa två punkter på en y-axel kan vi se att förutsägelsen var 39,5, men det faktiska värdet var 41.
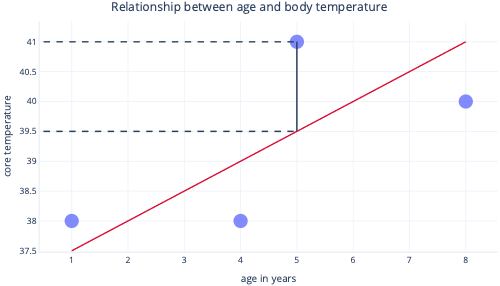
Modellen var alltså fel med 1,5 för den här datapunkten.
Oftast passar vi in i en modell genom att minimera restsumman av rutor. Det innebär att kostnadsfunktionen beräknas så här:
- Beräkna skillnaden mellan de faktiska och förutsagda värdena (som tidigare) för varje datapunkt.
- Kvadratera dessa värden.
- Summera (eller medelvärde) dessa kvadratvärden.
Det här kvadreringssteget innebär att inte alla punkter bidrar jämnt till linjen: avvikande värden – som är punkter som inte förväntas – har oproportionerligt större fel, vilket kan påverka linjens läge.
Styrkor med regression
Regressionstekniker har många styrkor som mer komplexa modeller inte har.
Förutsägbar och lätt att tolka
Regressioner är lätta att tolka eftersom de beskriver enkla matematiska ekvationer, som vi ofta kan diagrammera. Mer komplexa modeller kallas ofta black box-lösningar eftersom det är svårt att förstå hur de gör förutsägelser eller hur de kommer att bete sig med vissa indata.
Lätt att extrapolera
Regressioner gör det enkelt att extrapolera; för att göra förutsägelser för värden utanför datamängdens intervall. Till exempel är det enkelt att uppskatta i vårt tidigare exempel att en nioårig hund kommer att ha en temperatur på 40,5 °C. Du bör alltid vara försiktig med extrapolering: den här modellen skulle förutsäga att en 90-åring skulle ha en temperatur som nästan är tillräckligt varm för att koka vatten.
Optimal montering garanteras vanligtvis
De flesta maskininlärningsmodeller använder gradient descent för att passa modeller, vilket innebär att justera gradient-descent-algoritmen och ger ingen garanti för att en optimal lösning hittas. Linjär regression som använder summan av kvadrater som en kostnadsfunktion behöver däremot inte en iterativ gradient-descent-procedur. I stället kan vi använda smart matematik för att beräkna den optimala platsen för linjen som ska placeras. Matematiken ligger utanför omfånget för den här modulen, men det är bra att veta att linjär regression (så länge urvalsstorleken inte är för stor) inte behöver särskild uppmärksamhet för anpassningsprocessen, och den optimala lösningen garanteras.