Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Kommentar
Information om hur du automatiserar den manuella analysen som beskrivs i den här artikeln finns i Använda AGDiag för att diagnostisera hälsohändelser för tillgänglighetsgrupper.
Den här artikeln innehåller felsökningssteg som hjälper dig att avgöra varför tillgänglighetsgruppen redväxade.
Effekter av Always On-hälsotillstånd eller redundans
AlwaysOn implementerar robust hälsoövervakning via olika mekanismer för att säkerställa hälsotillståndet för den Microsoft SQL Server-instans som är värd för den primära repliken, det underliggande klustret och systemets hälsotillstånd. Produktionsarbetsbelastningen avbryts tillfälligt när ett Windows-kluster eller AlwaysOn-hälsoproblem identifieras.
När ett hälsotillstånd identifieras inträffar vanligtvis följande sekvens av händelser. I den här felsökaren nämns hälsohändelser som referens till följande händelser:
Tillgänglighetsgrupprepliker och databaser övergår från primär roll till att matcha roll.
Tillgänglighetsgruppdatabaser övergår till offline och är inte längre tillgängliga.
Windows-kluster markerar tillgänglighetsgruppens klustrade resurs som misslyckad.
Windows-klustret försöker återansluta tillgänglighetsgrupprollen (på den ursprungliga eller automatiska redundanspartnerrepliken).
Tillgänglighetsgruppens roll är online om den identifieras vara felfri av Hälsoövervakning av AlwaysOn och Windows-kluster.
Om det lyckas övergår tillgänglighetsgruppens repliker och databaser till den primära rollen och tillgänglighetsgruppens databaser är online och är tillgängliga för ditt program.
Program kan inte komma åt tillgänglighetsgruppens databaser
När ett hälsotillstånd identifieras övergår tillgänglighetsgruppens replik och databaser till rollen Matchning och tillgänglighetsgruppens databaser kopplas från. När repliken är online i den primära rollen (på den ursprungliga replikservern eller replikservern för redundanspartner) övergår repliken och databaserna igen till online. Medan repliken och databaserna löser och är offline, misslyckas alla program som försöker komma åt dessa tillgänglighetsgruppdatabaser och genererar meddelandet "Fel 983": Unable to access availability database.... Det här felet registreras också i Microsoft SQL Server-felloggen om SQL Server har konfigurerats för att registrera misslyckade inloggningsförsök:
Logon Error: 983, Severity: 14, State: 1.
Logon Unable to access availability database '<databasename>' because the database replica is not in the PRIMARY or SECONDARY role. Connections to an availability database is permitted only when the database replica is in the PRIMARY or SECONDARY role. Try the operation again later.
Den period under vilken tillgänglighetsgruppen finns i matchningsrollen innan den kommer tillbaka online i den primära rollen varar vanligtvis bara några sekunder eller till och med mindre än en sekund.
Identifiera och diagnostisera hälsohändelser för AlwaysOn-tillgänglighetsgruppen eller redundans
1. Identifiera Alltid på hälsotrender
Du kan undersöka en enskild AlwaysOn-hälsohändelse, eller så kan det finnas en ny eller pågående trend med hälsoproblem som tillfälligt avbryter produktionen. Följande frågor kan hjälpa dig att begränsa och korrelera de senaste ändringarna i produktionsmiljön som kan vara relaterade till dessa hälsoproblem:
- När började trenden för AlwaysOn- eller klusterhälsa?
- Inträffar hälsohändelserna en viss dag?
- Inträffar hälsohändelserna vid en viss tidpunkt på dagen?
- Inträffar hälsohändelserna en viss dag eller vecka i månaden?
Om du upptäcker en trend kontrollerar du det schemalagda underhållet på systemet (värdsystemet i en virtuell miljö), ETL-batchar och andra jobb som kan korrelera med dessa hälsohändelser. Om systemet är en virtuell dator undersöker du värdsystemet för ändringar som eventuellt infördes vid tidpunkten för avbrotten.
Överväg upptagna ad hoc-produktionsarbetsbelastningar som kan korrelera med tidpunkten för hälsoproblemen (till exempel när användarna först loggar in på systemet eller efter att användarna har återvänt från lunch).
Kommentar
Det här är ett bra tillfälle att överväga en plan för att samla in prestandadata under veckan och månaden. För att bättre förstå när systemet är som mest upptaget kan du mäta räknare för Windows-prestandaövervakare, till exempel Processor Information::% Processor Time, Memory::Available MBytesoch MSSQLServer:SQL Statistics::Batch Requests/sec.
2. Granska klusterloggen
Windows-klusterloggen är den mest omfattande loggen som ska användas för att identifiera typen av AlwaysOn- eller klusterhälsohändelse och även det identifierade hälsotillståndet som orsakade händelsen. Följ dessa steg för att generera och öppna klusterloggen:
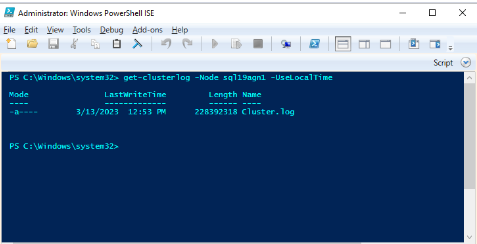
Använd Windows PowerShell för att generera Windows-klusterloggen på klusternoden som är värd för den primära repliken vid tidpunkten för hälsohändelsen. Kör till exempel följande cmdlet i ett upphöjt PowerShell-fönster med hjälp av "sql19agn1" som DET SQL Server-baserade servernamnet:
get-clusterlog -Node sql19agn1 -UseLocalTime
Kommentar
Som standard skapas loggfilen i %WINDIR%\cluster\reports.
3. Hitta hälsohändelsen i klusterloggen
AlwaysOn använder flera mekanismer för hälsoövervakning för att övervaka tillgänglighetsgruppens hälsa. Förutom en windowsklusterhälsohändelse (där Windows-kluster identifierar ett hälsoproblem bland klusternoderna) har AlwaysOn fyra olika typer av hälsokontroller:
- SQL Server-tjänsten körs inte
- Tidsgräns för ett SQL Server-lån
- Tidsgräns för en SQL Server-hälsokontroll
- Ett internt problem med SQL Server-hälsotillstånd
Du kan hitta någon av dessa AlwaysOn-specifika hälsohändelser genom att söka i klusterloggen efter strängen, [hadrag] Resource Alive result 0. Den här strängen sparas i klusterloggen när någon av dessa händelser identifieras. Till exempel:
00001334.00002ef4::2019/06/24-18:24:36.153 ERR [RES] SQL Server Availability Group : [hadrag] Resource Alive result 0.
Du kan använda ett verktyg för att hitta alla hälsohändelser i klusterloggen så att du kan generera en sammanfattningsrapport över AlwaysOn-hälsoproblem. Detta kan vara användbart för att identifiera kronologiska trender och avgöra om ett visst AlwaysOn-hälsotillstånd är återkommande. Följande skärmbild visar hur du använder en textredigerare (NotePad++, i det här fallet) för att hitta alla rader i klusterloggen som innehåller strängen [hadrag] Resource Alive result 0 :

Identifiera och lösa hälsoproblemet som utlöste redundansväxlingen
Om du vill identifiera hälsoproblemen i klusterloggen för den primära repliken jämför du dem med de problem som beskrivs i följande avsnitt. Vanliga orsaker till redundansväxling i tillgänglighetsgruppen är:
- Händelse för klusterhälsa
- SQL Server-tjänsten är nere (en AlwaysOn-hälsohändelse)
- Tidsgräns för lån (en AlwaysOn-hälsohändelse)
- Tidsgräns för hälsokontroll (en AlwaysOn-hälsohändelse)
- SQL Server-hälsa (en AlwaysOn-hälsohändelse)
Hälsohändelser för kluster
Microsoft Windows-kluster övervakar hälsotillståndet för medlemsservrarna i klustret. Om ett hälsoproblem upptäcks kan en klustermedlemsserver tas bort från klustret. Dessutom flyttas klusterresurserna (inklusive den tillgänglighetsgrupproll som finns på den borttagna klustermedlemsservern) till partnerrepliken för tillgänglighetsgruppens redundans om den är konfigurerad för automatisk redundans.
Symptom
Här är ett exempel på en klusterhälsohändelse i klusterloggen. För att hitta den kan du söka Lost quorum efter eller Cluster service has terminated på grund av att antingen kan finnas under ändringen av tillgänglighetsgruppens roll eller redundans.
00000fe4.00001628::2022/12/15-14:26:02.654 WARN [QUORUM] Node 1: Lost quorum (1)
00000fe4.00001628::2022/12/15-14:26:02.654 WARN [QUORUM] Node 1: goingAway: 0, core.IsServiceShutdown: 0
00000fe4.00001628::2022/12/15-14:26:02.654 WARN lost quorum (status = 5925)
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [NETFT] Cluster Service preterminate succeeded.
00000fe4.00001628::2022/12/15-14:26:02.654 WARN lost quorum (status = 5925), executing OnStop
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [DM]: Shutting down, so unloading the cluster database.
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [DM] Shutting down, so unloading the cluster database (waitForLock: false).
000019cc.000019d0::2022/12/15-14:26:02.654 WARN [RHS] Cluster service has terminated. Cluster.Service.Running.Event got signaled.
Ett annat sätt att identifiera den här händelsen är att söka i händelseloggen för Windows-systemet:
Critical SQL19AGN1.CSSSQL 1135 Microsoft-Windows-FailoverClusterin Node Mgr NT AUTHORITY\SYSTEM Cluster node 'SQL19AGN2' was removed from the active failover cluster membership. The Cluster service on this node may have stopped. This could also be due to the node having lost communication with other active nodes in the failover cluster. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapters on this node. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Critical SQL19AGN1.CSSSQL 1177 Microsoft-Windows-FailoverClusterin Quorum Manager NT AUTHORITY\SYSTEM The Cluster service is shutting down because quorum was lost. This could be due to the loss of network connectivity between some or all nodes in the cluster, or a failover of the witness disk. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapter. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Diagnostisera en klusterhälsohändelse
Felen i Windows-händelseloggen (händelser 1135 och 1177) tyder på att nätverksanslutningen är en orsak till händelsen. Det här är den vanligaste orsaken till att ett problem med klusterhälsa identifieras. I följande exempel visas att andra klustermedlemsservrar inte kunde kommunicera med den här servern som är värd för den primära repliken för tillgänglighetsgruppen och att det här problemet utlöste borttagningen av klusternoden från klustret:
00000fe4.00001edc::2022/12/14-22:44:36.870 INFO [NODE] Node 1: New join with n3: stage: 'Attempt Initial Connection' status (10060) reason: 'Failed to connect to remote endpoint <endpoint address>'
00000fe4.00001620::2022/12/15-14:26:02.050 INFO [IM] got event: Remote endpoint <endpoint address> unreachable from <endpoint address>
00000fe4.00001620::2022/12/15-14:26:02.050 WARN [NDP] All routes for route (virtual) local <local address> to remote <remote address> are down
00000fe4.0000179c::2022/12/15-14:26:02.053 WARN [NODE] Node 1: Connection to Node 2 is broken. Reason GracefulClose(1226)' because of 'channel to remote endpoint <endpoint address> is closed'
Du kan söka i klusterloggen efter bevis på ett anslutningsfel till noden. Från platsen i klusterloggen där du hittade Lost quorumsöker du bakåt efter strängar som Failed to connect to remote endpoint, unreachableoch is broken.
Åtgärd
Kontrollera att klusterhälsoövervakning är lämplig för värdmiljön. Mer information om SQL Server AlwaysOn-tillgänglighetsgrupper som finns i Microsoft Azure finns i Översikt över Windows Server-redundanskluster – SQL Server på virtuella Azure-datorer.
Om det är nödvändigt kan du kontakta Microsoft Windows-supporten för hög tillgänglighet för att öppna en supportincident.
SQL Server-tjänsten är nere: En AlwaysOn-hälsohändelse
AlwaysOn-hälsoövervakning kan identifiera om DEN SQL Server-tjänst som är värd för den primära repliken för tillgänglighetsgruppen inte längre körs.
Symptom
Här är ett exempel på klusterloggrapporten för tillgänglighetsgrupprollen ag som anger ett fel eftersom QueryServiceStatusEx ett process-ID 0returnerades:
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] QueryServiceStatusEx returned a process id 0
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] SQL server service is not alive
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] Resource Alive result 0.
00001898.0000185c::2023/02/27-13:27:41.121 WARN [RHS] Resource ag IsAlive has indicated failure.
Diagnostisera sql service-avstängningshändelser
Kontrollera händelseloggen för Windows-systemet och SQL Server-felloggen för en oväntad SQL Server-avstängning.
Om SQL Server stängdes av av en systemavstängning eller en administrativ avstängning skulle du se följande post i SQL Server-felloggen:
2023-03-10 09:38:46.73 spid9s SQL Server is terminating in response to a 'stop' request from Service Control Manager. This is an informational message only. No user action is required.
Händelseloggen för Windows-systemet visar följande felpost:
Information 3/10/2023 9:41:06 AM Service Control Manager 7036 None The SQL Server (MSSQLSERVER) service entered the stopped state.
Händelseloggen för Windows-systemet visar följande felpost om SQL Server oväntat stängs av:
Error 3/10/2023 8:37:46 AM Service Control Manager 7034 None The SQL Server (MSSQLSERVER) service terminated unexpectedly. It has done this 1 time(s).
Leta efter ledtrådar i slutet av SQL Server-felloggen. Om felloggen slutar plötsligt innebär det att den stängdes av med våld. Om SQL Server till exempel avslutades med Hjälp av Aktivitetshanteraren skulle SQL Server-felrapporten inte avslöja någon information om några interna problem som kan ha orsakat att processen stängdes av.
Åtgärd
Se till att auktoriserade databas- och systemadministratörer har åtkomst till systemet för att minimera oväntade avslutningar av SQL Server-tjänsten. När du har granskat händelseloggarna undersöker du varför en tjänst oväntat måste avslutas.
Om ett internt problem med SQL Server-hälsotillståndet gjorde att SQL Server oväntat avslutades kan det finnas ledtrådar om ett eventuellt allvarligt undantag (inklusive en minnesdumpdiagnostikfil som genereras) i slutet av SQL-felloggen. Granska ledtrådarna och vidta nödvändiga åtgärder. Om du hittar en dumpfil kan du kontakta Microsoft SQL Server-supporten och ange SQL Server-felloggen och dumpfilinnehållet för ytterligare undersökning.
Tidsgräns för lån: En AlwaysOn-hälsohändelse
AlwaysOn använder en "lease"-mekanism för att övervaka hälsotillståndet för den dator där SQL Server är installerat. Standardtidsgränsen för lån är 20 sekunder.
Symptom
Här är ett exempel på utdata från tidsgränsen för AlwaysOn-lån från klusterloggen. Du kan söka i dessa strängar för att hitta en tidsgräns för lån i klusterloggen.
00001a0c.00001c5c::2023/01/04-15:36:54.762 ERR [RES] SQL Server Availability Group : [hadrag] Availability Group lease is no longer valid
00001a0c.00001c5c::2023/01/04-15:36:54.762 ERR [RES] SQL Server Availability Group : [hadrag] Resource Alive result 0.
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] Lease timeout detected, logging perf counter data collected so far
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] Date/Time, Processor time(%), Available memory(bytes), Avg disk read(secs), Avg disk write(secs)
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:35:57.0, 98.068572, 509227008.000000, 0.000395, 0.000350 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:7.0, 12.314941, 451817472.000000, 0.000278, 0.000266 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:17.0, 17.270742, 416096256.000000, 0.000376, 0.000292 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:27.0, 38.399895, 416301056.000000, 0.000446, 0.000304 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:37.0, 100.000000, 417517568.000000, 0.001292, 0.000666
Mer information om tidsgränser för lån finns i avsnittet Lånemekanism i Mekanik och riktlinjer för tidsgränser för lån, kluster och hälsokontroll för AlwaysOn-tillgänglighetsgrupper.
Diagnostisera och lösa tidsgränshändelser för AlwaysOn-lån
Det finns två huvudsakliga problem som kan utlösa en tidsgräns för lån:
SQL Server-minnesdumpning: När SQL Server identifierar vissa interna hälsohändelser, till exempel en åtkomstöverträdelse, ett intyg eller ett scheduler-dödläge, genererar den en diagnostikdumpfil (.mdmp) i mappen SQL Server \LOG . Processen med att generera en minnesdump pausar SQL Server-körningen under en kort period. Under den perioden kan lånemekanismen identifiera brist på tjänstsvar och utlösaråtgärd. Mer information finns i Effekten av dumpgenerering.
Ett problem med systemomfattande prestanda: En tidsgräns för lån indikerar inte nödvändigtvis ett problem med SQL Server-hälsotillståndet. I stället kan det tyda på ett systemomfattande hälsoproblem som också påverkar hälsotillståndet för den SQL Server-baserade servern.
- Hög CPU-användning i systemet (nära 100 %).
- Out-of-memory-villkor – lågt virtuellt minne och/eller någon av processerna håller på att bläddras ut.
- WSFC går offline på grund av kvorumförlust
- Begränsning av virtuella datorer som påverkar prestanda och orsakar förfallotid för lån.
Åtgärd
Detaljerade felsökningssteg finns i MSSQLSERVER_19407. Här är de två vanligaste problemen:
1. SQL Server dumpfildiagnostik
SQL Server kan identifiera ett internt hälsoproblem, till exempel en åtkomstöverträdelse, kontroll eller låsta schemaläggare. I det här fallet genererar programmet en minidumpfil (.mdmp) i MAPPEN SQL Server \LOG i SQL Server-processen för diagnos. SQL Server-processen är låst i flera sekunder medan minidumpfilen skrivs till disk. Under den här tiden är alla trådar i SQL Server-processen i ett låst tillstånd, vilket inkluderar lånetråden som övervakas av AlwaysOn-hälsoövervakning. Därför kan AlwaysOn identifiera en tidsgräns för lån.
**Dump thread - spid = 0, EC = 0x0000000000000000
***Stack Dump being sent to C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\LOG\SQLDump0001.txt
* *******************************************************************************
*
* BEGIN STACK DUMP:
* 11/02/14 21:21:10 spid 1920
*
* Deadlocked Schedulers
*
* *******************************************************************************
* -------------------------------------------------------------------------------
* Short Stack Dump
Stack Signature for the dump is 0x00000000000002BA
Error: 19407, Severity: 16, State: 1.
The lease between availability group 'ag' and the Windows Server Failover Cluster has expired. A connectivity issue occurred between the instance of SQL Server and the Windows Server Failover Cluster. To determine whether the availability group is failing over correctly, check the corresponding availability group resource in the Windows Server Failover Cluster.
För att lösa det här problemet måste diagnostiken för minnesdumpfilen undersökas för rotorsaken. Överväg att kontakta Microsoft SQL Server-supporten för att tillhandahålla SQL Server-felloggen och dumpfilinnehållet för ytterligare undersökning.
2. Problem med hög CPU-användning eller andra systemprestanda
En tidsgräns för lån anger ett prestandaproblem som påverkar hela systemet, inklusive SQL Server. För att diagnostisera systemproblemet rapporterar AlwaysOn-hälsodiagnostik prestandaövervakningsdata i klusterloggen och inkluderar tidsgränshändelsen för lån. Prestandadata sträcker sig över cirka 50 sekunder fram till tidsgränsen för lån, rapportering om processoranvändning, ledigt minne och diskfördröjning.
Här är ett exempel på rapporterade prestandadata som visar en tidsgräns för lån i klusterloggen. I det här exemplet utdata, hög övergripande CPU-användning som kan vara relaterad till tidsgränsen för lån.
00000f90.000015c0::2020/08/07-14:16:41.378 WARN [RES] SQL Server Availability Group: [hadrag] Lease timeout detected, logging perf counter data collected so far
00000f90.000015c0::2020/08/07-14:16:41.382 WARN [RES] SQL Server Availability Group: [hadrag] Date/Time, Processor time(%), Available memory(bytes), Avg disk read(secs), Avg disk write(secs)
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:20.0, 83.266073, 31700828160.000000, 0.018094, 0.015752
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:30.0, 93.653224, 31697063936.000000, 0.038590, 0.026897
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:40.0, 94.270691, 31696265216.000000, 0.166000, 0.038962
00000f90.000015c0::2020/08/07-14:16:41.434 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:50.0, 90.272016, 31695409152.000000, 0.215141, 0.106084
00000f90.000015c0::2020/08/07-14:16:41.434 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:16:1.0, 99.991336, 31695892480.000000, 0.046983, 0.035440
Om prestandadata visar hög CPU-användning, ett lågt minnestillstånd eller hög diskfördröjning vid tidpunkten för en tidsgräns för lån börjar du samla in Prestandaövervakardata för hela dagen på den primära repliken för att undersöka dessa symtom. Genom att samla in prestandaövervakningsdata under en längre period kan du bättre identifiera baslinje- och toppvärden för dessa resurser och övervaka ändringar i dessa resurser när tidsgränsen för lån inträffar. När du samlar in dessa data bör du överväga om det finns vissa schemalagda eller ad hoc-arbetsbelastningar i SQL Server som korrelerar med tidpunkten för dessa resursproblem och hälsohändelser.
Du bör också samla in räknare som rapporterar samma systemresursanvändning, inklusive följande:
Processor Information::% Processor TimeMemory::Available MBytesLogical Disk::Avg. Disk sec/ReadLogical Disk::Avg. Disk sec/WriteLogical Disk::Avg. Disk Read Queue LengthLogical Disk::Avg. Disk Write Queue LengthMSSQLServer:SQL Statistics::Batch Requests/sec
Tidsgräns för hälsokontroll: En AlwaysOn-hälsohändelse
AlwaysOn använder en hälsokontrollmekanism för att övervaka hälsotillståndet för SQL Server och möjligheten för klientprogram att ansluta.
Symptom
När en tillgänglighetsgruppreplik övergår till den primära rollen upprättar AlwaysOn-hälsoövervakning en lokal ODBC-anslutning till SQL Server-instansen. Även om AlwaysOn är anslutet och övervakar, om SQL Server inte svarar över ODBC-anslutningen inom den period som har angetts för tillgänglighetsgruppens tidsgräns för hälsokontroll (standardvärdet är 30 sekunder), utlöses en timeout-händelse för hälsokontroll. I den här situationen övergår tillgänglighetsgruppen från den primära rollen till rollen Lösa och initierar redundans, om den är konfigurerad för att göra detta.
Mer information om tidsgränser för hälsokontroll finns i avsnittet "Tidsgräns för hälsokontroll" i Mekanik och riktlinjer för tidsgränser för lån, kluster och hälsokontroll för AlwaysOn-tillgänglighetsgrupper.
Här är tidsgränsen för AlwaysOn-hälsokontrollen enligt rapporten i klusterloggen:
0000211c.00002d70::2021/02/24-02:50:01.890 WARN [RES] SQL Server Availability Group: [hadrag] Failed to retrieve data column. Return code -1
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <AG>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <AG>: [hadrag] Resource Alive result 0.
0000211c.00002594::2021/02/24-02:50:02.453 WARN [RHS] Resource AG IsAlive has indicated failure.
00001278.00002ed8::2021/02/24-02:50:02.453 INFO [RCM] HandleMonitorReply: FAILURENOTIFICATION for 'AG', gen(0) result 1/0.
Diagnostisera och lösa timeout-händelsen för AlwaysOn-hälsokontroll
Följande avsnitt hjälper dig att granska SQL Server-loggarna för "brödsmulhändelser" som du kan hitta och som korrelerar med tidsgränser för AlwaysOn-hälsokontroll som identifieras och rapporteras. Loggarna som granskas här inkluderar klusterloggen (där tidsgränsen för hälsokontrollen bekräftas), de system_health utökade händelseloggarna och SQL Server-felloggarna (båda finns i MAPPEN SQL Server \LOG ) och Händelseloggen för Windows-systemet. Använd dessa och andra loggar för att leta efter korrelerande händelser som kan hjälpa dig att begränsa orsaken till tidsgränsen för hälsokontrollen.
1. Sök efter icke-givande scheduler-händelser
Tidsgränsen för AlwaysOn-hälsokontroll orsakas ofta av "icke-givande" händelser i SQL Server. När SQL Server upptäcker att en tråd inte har gett resultat i en schemaläggare rapporterar den att en icke-givande scheduler-händelse har inträffat. Om du ser andra uppgifter i samma schemaläggare som inte tar emot CPU-tid är detta det primära tecknet på en icke-avkastningsschemaläggare. Det här beteendet kan orsaka en fördröjd körning av de uppgifter och "svälta" arbetsbelastningar som har tilldelats till en viss schemaläggare av CPU-tid.
Följ dessa steg för att söka efter icke-avkastningsbaserade scheduler-händelser:
Kontrollera de utökade händelseloggarna för SQL Server
system_healthför att avgöra om en icke-givande scheduler-händelse av något slag rapporterades vid tidpunkten för tidsgränsen för alwayson-hälsokontrollen. Icke-avkastningshändelser som du kan hitta inkluderar följande:scheduler_monitor_non_yielding_ring_buffer_recordedscheduler_monitor_non_yielding_iocp_ring_buffer_recordedscheduler_monitor_stalled_dispatcher_ring_buffer_recordedscheduler_monitor_non_yielding_rm_ring_buffer_recorded
Öppna SQL Server-systemets utökade händelseloggar för systemhälsa på den primära repliken till tidpunkten för tidsgränsen för den misstänkta hälsokontrollen.
I SQL Server Management Studio (SSMS) går du till Öppna fil och väljer Sammanfoga utökade händelsefiler.>
Välj knappen Lägg till.
I dialogrutan Öppna fil navigerar du till filerna i KATALOGEN SQL Server \LOG.
Tryck på och håll kontroll och välj sedan de filer vars namn börjar med
system_health_xxx.xel.Välj Öppna>OK.
Filtrera resultatet. Högerklicka på en händelse under namnkolumnen och välj Filtrera efter det här värdet.
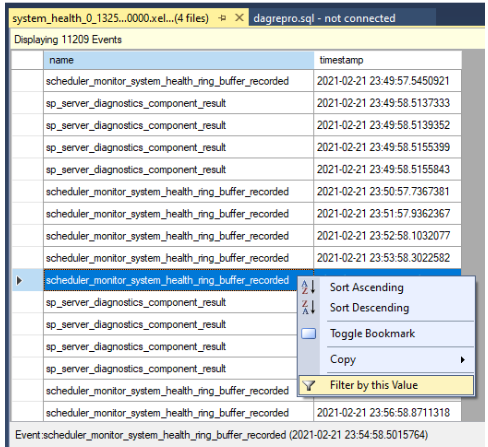
Definiera ett filter för att sortera rader där värdena i namnkolumnen innehåller
yield, enligt följande skärmbild. Detta returnerar alla typer av icke-avkastningshändelser som kan ha registrerats i loggarnasystem_health.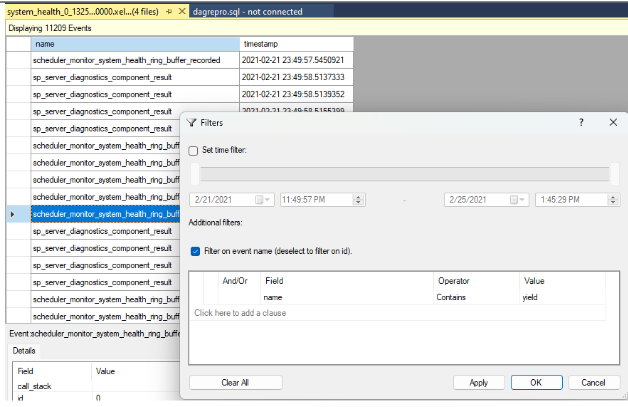
Jämför tidsstämplarna för att se om det fanns icke-avkastningshändelser vid tidpunkten för tidsgränsen för hälsokontrollen. Här är tidsgränsen för hälsokontrollen enligt rapporten i klusterloggen:
0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost 0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group < SQL19AGN1>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel 0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group < SQL19AGN1: [hadrag] Resource Alive result 0.Du kan se att det fanns icke-avkastningshändelser som inträffade vid tidpunkten för tidsgränsen för hälsokontrollen.
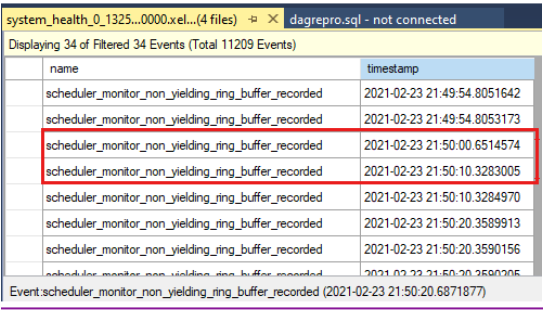
Om icke-avkastningshändelser identifieras kontrollerar du orsaken till den icke-avkastningshändelsen. Överväg att kontakta SQL Server-supportteamet för att undersöka händelser som inte ger resultat.
2. Kontrollera SQL Server-felloggen
Kontrollera SQL Server-felloggen för korrelering av händelser vid tidpunkten för tidsgränsen för hälsokontrollen. Dessa händelser kan ge "brödsmulor" som föreslår ytterligare steg för att begränsa rotorsaken till tidsgränserna för hälsokontrollen.
Följande loggpost visar till exempel att tidsgränsen för hälsokontrollen inträffade i klusterloggen:
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <SQL19AGN1>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <SQL19AGN1>: [hadrag] Resource Alive result 0.
I SQL Server-felloggen rapporterar SQL Server inom några sekunder efter tidsgränsen för hälsokontrollen att den har identifierat allvarlig I/O-svarstid:
2021-02-23 20:49:54.64 spid12s SQL Server has encountered 1 occurrence(s) of I/O requests taking longer than 15 seconds to complete on file [C:\Program Files\Microsoft SQL Server\MSSQL15.MSSQLSERVER\MSSQL\DATA\agdb_log.ldf] in database id 12. The OS file handle is 0x0000000000001594. The offset of the latest long I/O is: 0x000030435b0000. The duration of the long I/O is: 26728 ms.
Granska systemhändelseloggen för att hitta möjliga system ledtrådar som kan vara relaterade till timeout-händelsen för hälsokontrollen. När du granskar händelseloggen för Windows-systemet kan du hitta ett I/O-problem som rapporteras samtidigt för samma tidsgräns för hälsokontroll:
02/23/2021,08:50:16 PM,Warning,SQL19AGN1.CSSSQL.local.local,<...>,"Reset to device, \Device\<device ID>, was issued."
02/23/2021,08:50:16 PM,Warning,SQL19AGN1.CSSSQL.local.local,<...>,"The IO operation at logical block address <block address> for Disk 6 (PDO name: \Device\<device ID>) was retried."
SQL Server-hälsa: En AlwaysOn-hälsohändelse
AlwaysOn övervakar olika typer av SQL Server-hälsohändelser. Sql Server är värd för en primär replik för tillgänglighetsgruppen, men körs kontinuerligt sp_server_diagnostics som rapporterar om SQL Server-hälsa med hjälp av olika komponenter. När eventuella hälsoproblem identifieras sp_server_diagnostics rapporterar du ett fel för den specifika komponenten och skickar sedan resultaten tillbaka till alwayson-hälsoidentifieringsprocessen. När ett fel rapporteras visar rollen Tillgänglighetsgrupp det misslyckade tillståndet och eventuell redundansväxling om tillgänglighetsgruppen har konfigurerats för att göra detta.
Symptom
Här är ett exempel på ett PROBLEM med SQL Server-hälsotillstånd som rapporteras av sp_server_diagnostics i klusterloggen. SQL Server rapporterar ett "fel"-tillstånd i systemkomponenten till AlwaysOn-hälsoövervakning, och tillgänglighetsgruppen "contoso-ag" övergår till ett misslyckat tillstånd.
Kommentar
Ett problem med SQL Server-hälsotillstånd genererar en liknande rapport som tidsgränsen för hälsokontroll. Båda hälsohändelserna rapporterar Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel. Skillnaden för en SQL Server-hälsohändelse är att den rapporterar att SQL Server-komponenten har ändrats från "varning" till "fel".
INFO [RES] SQL Server Availability Group: [hadrag] SQL Server component 'system' health state has been changed from 'warning' to 'error' at 2019-06-20 15:05:52.330
ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, the state of system component is error
ERR [RES] SQL Server Availability Group <contoso-ag>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
ERR [RES] SQL Server Availability Group <contoso-ag>: [hadrag] Resource Alive result 0.
ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, the state of system component is error
WARN [RHS] Resource contoso-ag IsAlive has indicated failure.
INFO [RCM] HandleMonitorReply: FAILURENOTIFICATION for 'contoso-ag', gen(0) result 1/0.
Diagnostisera SQL Server-hälsohändelser
Den typ av hälsoproblem som rapporteras av SQL Server-hälsan bör styra riktningen för rotorsaksanalysen.
När du distribuerar en tillgänglighetsgrupp FAILURE_CONDITION_LEVEL anges som standard som tre. Detta aktiverar övervakning av vissa, men inte alla SQL Server-hälsoprofiler. På standardnivå utlöser AlwaysOn en hälsohändelse när SQL Server genererar för många dumpfiler, en överträdelse av skrivåtkomst eller en överbliven spinlock. Om du ställer in tillgänglighetsgruppen på nivå fyra eller fem utökas de typer av PROBLEM med SQL Server-hälsotillstånd som övervakas. Mer information om ÖVERVAKARe av SQL Server-hälsotillståndet AlwaysOn finns i Konfigurera en flexibel princip för automatisk redundans för en tillgänglighetsgrupp – SQL Server AlwaysOn.
Följ dessa steg för att identifiera problemet med AlwaysOn-specifika hälsotillstånd:
Öppna sql Server-klusterdiagnostikens utökade händelseloggar på den primära repliken till den tidpunkt då den misstänkta SQL Server-hälsohändelsen inträffade.
I SSMS går du till Öppna fil>och väljer sedan Sammanfoga utökade händelsefiler.
Markera Lägga till.
I dialogrutan Öppna fil navigerar du till filerna i KATALOGEN SQL Server \LOG.
Tryck på Kontroll, välj de filer vars namn matchar
<servername>_<instance>_SQLDIAG_xxx.xeloch välj sedan Öppna>OK.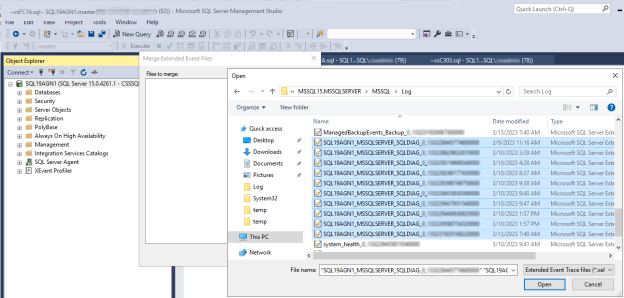
Du ser ett nytt fönster med flikar i SSMS som innehåller de utökade händelserna, enligt följande skärmbild.
Om du vill undersöka ett problem med SQL Server-hälsotillståndet letar du reda på
component_health_resultvarsstate_descvärde ärerror. Här är ett exempel på en systemkomponenthändelse som rapporterade ett fel tillbaka till AlwaysOn-hälsoövervakning: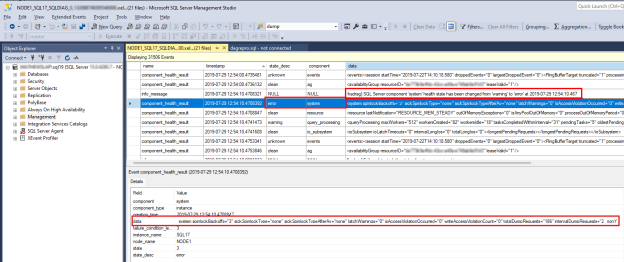
Dubbelklicka på datakolumnen i det nedre fönstret. Då öppnas detaljerade komponentdata i ett nytt fönsterfönster för SSMS för granskning. Så här ser systemkomponentdata ut:

Observera att "totalDumprequests=186"-data indikerar att det har genererats för många diagnostikhändelser för dumpfiler på denna SQL Server. Det här är orsaken till att systemkomponenten rapporterade ett feltillstånd. När AlwaysOn-hälsoövervakning tar emot det här feltillståndet utlöser den en hälsohändelse för tillgänglighetsgruppen. Du kan också kontrollera att inga överträdelser av skrivåtkomst eller överblivna spinlocks har identifierats från de data som anges i systemkomponentdata.



Åtgärd
Beroende på vilken typ av problem du upptäcker måste du åtgärda det i enlighet med detta. Som artikeln Konfigurera en flexibel automatisk redundansprincip för en tillgänglighetsgrupp – SQL Server AlwaysOn diskuterar kan det finnas olika problem som leder till detta. Exempel:
- SQL Server-tjänsten är nere.
- Tidsgräns för lån.
- Tillgänglighetsrepliken är i fel tillstånd.
- Minnesdumpar som genereras av överblivna spinlocks, åtkomstöverträdelser eller för många minnesdumpar som genererats på kort tid.
- Beständiga out-of-memory-villkor i den interna SQL Server-resurspoolen.
- Identifiering av Scheduler-dödläge.
- Identifiering av ett olösbart dödläge.
Om det behövs kontaktar du SQL Server-supporten för att öppna en supportincident för ytterligare hjälp med att hitta rotorsaken till dessa interna SQL Server-hälsoproblem