ใช้สมุดบันทึกเพื่อโหลดข้อมูลลงในเลคเฮาส์ของคุณ
ในบทช่วยสอนนี้ เรียนรู้วิธีการอ่าน/เขียนข้อมูลลงใน Fabric lakehouse ของคุณด้วยสมุดบันทึก แฟบริคสนับสนุน Spark API และ Pandas API เพื่อบรรลุเป้าหมายนี้
โหลดข้อมูลด้วย Apache Spark API
ในเซลล์โค้ดของสมุดบันทึก ให้ใช้ตัวอย่างโค้ดต่อไปนี้เพื่ออ่านข้อมูลจากแหล่งข้อมูล และโหลดลงใน Files, Tables หรือทั้งสองส่วนของ lakehouse ของคุณ
เมื่อต้องการระบุตําแหน่งที่ตั้งที่จะอ่านจาก คุณสามารถใช้เส้นทางสัมพัทธ์ถ้าข้อมูลมาจากเลคเฮ้าส์เริ่มต้นของสมุดบันทึกปัจจุบันของคุณ หรือถ้าข้อมูลมาจาก lakehouse อื่น คุณสามารถใช้เส้นทาง Azure Blob File System (ABFS) แบบสัมบูรณ์ได้ คัดลอกเส้นทางนี้จากเมนูบริบทของข้อมูล
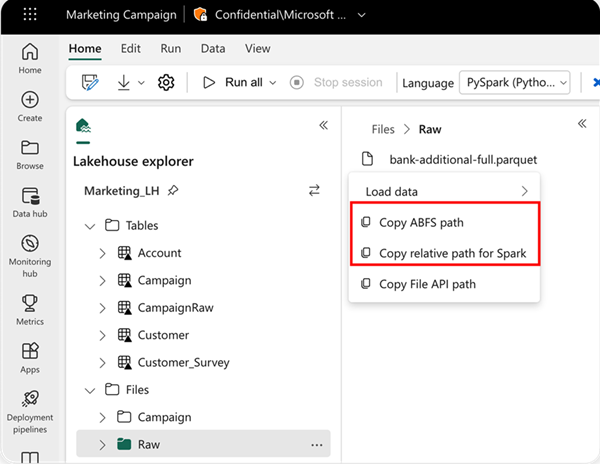
คัดลอกเส้นทาง ABFS: ตัวเลือกนี้จะส่งกลับเส้นทางสัมบูรณ์ของไฟล์
คัดลอกเส้นทางสัมพัทธ์สําหรับ Spark: ตัวเลือกนี้จะส่งกลับเส้นทางสัมพัทธ์ของไฟล์ใน lakehouse ค่าเริ่มต้นของคุณ
df = spark.read.parquet("location to read from")
# Keep it if you want to save dataframe as CSV files to Files section of the default lakehouse
df.write.mode("overwrite").format("csv").save("Files/ " + csv_table_name)
# Keep it if you want to save dataframe as Parquet files to Files section of the default lakehouse
df.write.mode("overwrite").format("parquet").save("Files/" + parquet_table_name)
# Keep it if you want to save dataframe as a delta lake, parquet table to Tables section of the default lakehouse
df.write.mode("overwrite").format("delta").saveAsTable(delta_table_name)
# Keep it if you want to save the dataframe as a delta lake, appending the data to an existing table
df.write.mode("append").format("delta").saveAsTable(delta_table_name)
โหลดข้อมูลด้วย Pandas API
เพื่อสนับสนุน Pandas API ค่าเริ่มต้นของ lakehouse จะถูกติดตั้งลงในสมุดบันทึกโดยอัตโนมัติ จุดที่ติดอยู่คือ '/เลคเฮ้าส์/ค่าเริ่มต้น/' คุณสามารถใช้จุดยึดนี้ในการอ่าน/เขียนข้อมูลจาก/ไปยังเลคเฮ้าส์เริ่มต้นได้ ตัวเลือก "คัดลอกเส้นทาง API ของไฟล์" จากเมนูบริบทส่งกลับเส้นทาง API ไฟล์จากจุดต่อเชื่อมนั้น เส้นทางที่ส่งกลับจากตัวเลือก คัดลอกเส้นทาง ABFS ยังใช้งานได้กับ Pandas API
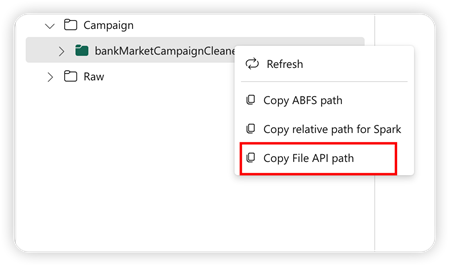
คัดลอกไฟล์เส้นทาง API: ตัวเลือกนี้ส่งกลับเส้นทางภายใต้จุดยึดของ lakehouse ค่าเริ่มต้น
# Keep it if you want to read parquet file with Pandas from the default lakehouse mount point
import pandas as pd
df = pd.read_parquet("/lakehouse/default/Files/sample.parquet")
# Keep it if you want to read parquet file with Pandas from the absolute abfss path
import pandas as pd
df = pd.read_parquet("abfss://DevExpBuildDemo@msit-onelake.dfs.fabric.microsoft.com/Marketing_LH.Lakehouse/Files/sample.parquet")
เคล็ดลับ
สําหรับ Spark API โปรดใช้ตัวเลือกของการ คัดลอกเส้นทาง ABFS หรือ คัดลอกเส้นทางสัมพัทธ์สําหรับ Spark เพื่อรับเส้นทางของไฟล์ สําหรับ Pandas API โปรดใช้ตัวเลือก ของการ คัดลอกเส้นทาง ABFS หรือ คัดลอกไฟล์ API เส้นทาง เพื่อรับเส้นทางของไฟล์
วิธีที่รวดเร็วที่สุดในการมีรหัสเพื่อทํางานกับ Spark API หรือ Pandas API คือการใช้ตัวเลือกของ โหลดข้อมูล และเลือก API ที่คุณต้องการใช้ รหัสจะถูกสร้างขึ้นในเซลล์โค้ดใหม่ของสมุดบันทึกโดยอัตโนมัติ

เนื้อหาที่เกี่ยวข้อง
คำติชม
เร็วๆ นี้: ตลอดปี 2024 เราจะขจัดปัญหา GitHub เพื่อเป็นกลไกคำติชมสำหรับเนื้อหา และแทนที่ด้วยระบบคำติชมใหม่ สำหรับข้อมูลเพิ่มเติม ให้ดู: https://aka.ms/ContentUserFeedback
ส่งและดูข้อคิดเห็นสำหรับ