What is speaker recognition?
Important
Speaker recognition in Azure AI Speech will be retired on September 30th 2025. Your applications won't be able to use speaker recognition after this date.
This change doesn't affect other Azure AI Speech capabilities such as speech to text, text to speech, and speech translation.
Speaker recognition can help determine who is speaking in an audio clip. The service can verify and identify speakers by their unique voice characteristics, by using voice biometry.
You provide audio training data for a single speaker, which creates an enrollment profile based on the unique characteristics of the speaker's voice. You can then cross-check audio voice samples against this profile to verify that the speaker is the same person (speaker verification). You can also cross-check audio voice samples against a group of enrolled speaker profiles to see if it matches any profile in the group (speaker identification).
Speaker verification
Speaker verification streamlines the process of verifying an enrolled speaker identity with either passphrases or free-form voice input. For example, you can use it for customer identity verification in call centers or contactless facility access.
How does speaker verification work?
The following flowchart provides a visual of how this works:
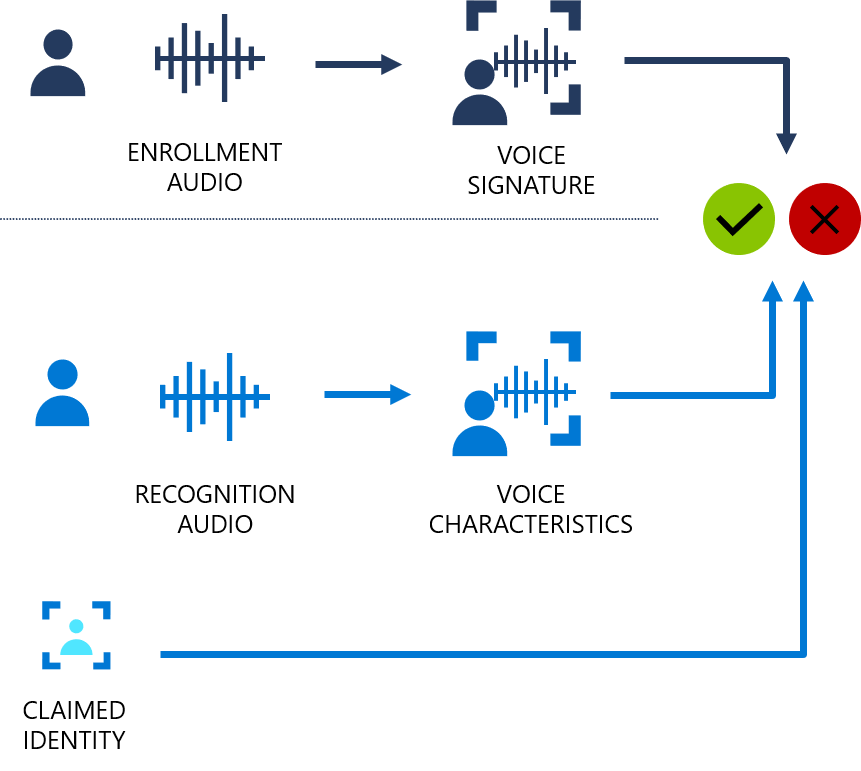
Speaker verification can be either text-dependent or text-independent. Text-dependent verification means that speakers need to choose the same passphrase to use during both enrollment and verification phases. Text-independent verification means that speakers can speak in everyday language in the enrollment and verification phrases.
For text-dependent verification, the speaker's voice is enrolled by saying a passphrase from a set of predefined phrases. Voice features are extracted from the audio recording to form a unique voice signature, and the chosen passphrase is also recognized. Together, the voice signature and the passphrase are used to verify the speaker.
Text-independent verification has no restrictions on what the speaker says during enrollment, besides the initial activation phrase when active enrollment is enabled. It doesn't have any restrictions on the audio sample to be verified, because it only extracts voice features to score similarity.
The APIs aren't intended to determine whether the audio is from a live person, or from an imitation or recording of an enrolled speaker.
Speaker identification
Speaker identification helps you determine an unknown speaker’s identity within a group of enrolled speakers. Speaker identification enables you to attribute speech to individual speakers, and unlock value from scenarios with multiple speakers, such as:
- Supporting solutions for remote meeting productivity.
- Building multi-user device personalization.
How does speaker identification work?
Enrollment for speaker identification is text-independent. There are no restrictions on what the speaker says in the audio, besides the initial activation phrase when active enrollment is enabled. Similar to speaker verification, the speaker's voice is recorded in the enrollment phase, and the voice features are extracted to form a unique voice signature. In the identification phase, the input voice sample is compared to a specified list of enrolled voices (up to 50 in each request).
Data security and privacy
Speaker enrollment data is stored in a secured system, including the speech audio for enrollment and the voice signature features. The speech audio for enrollment is only used when the algorithm is upgraded, and the features need to be extracted again. The service doesn't retain the speech recording or the extracted voice features that are sent to the service during the recognition phase.
You control how long data should be retained. You can create, update, and delete enrollment data for individual speakers through API calls. When the subscription is deleted, all the speaker enrollment data associated with the subscription is also deleted.
As with all of the Azure AI services resources, developers who use the speaker recognition feature must be aware of Microsoft policies on customer data. You should ensure that you received the appropriate permissions from the users. You can find more details in Data and privacy for speaker recognition. For more information, see the Azure AI services page on the Microsoft Trust Center.
Common questions and solutions
| Question | Solution |
|---|---|
| What situations am I most likely to use speaker recognition? | Good examples include call center customer verification, voice-based patient check-in, meeting transcription, and multi-user device personalization. |
| What's the difference between identification and verification? | Identification is the process of detecting which member from a group of speakers is speaking. Verification is the act of confirming that a speaker matches a known, enrolled voice. |
| What languages are supported? | See Speaker recognition language support. |
| What Azure regions are supported? | See Speaker recognition region support. |
| What audio formats are supported? | Mono 16 bit, 16 kHz PCM-encoded WAV. |
| Can you enroll one speaker multiple times? | Yes, for text-dependent verification, you can enroll a speaker up to 50 times. For text-independent verification or speaker identification, you can enroll with up to 300 seconds of audio. |
| What data is stored in Azure? | Enrollment audio is stored in the service until the voice profile is deleted. Recognition audio samples aren't retained or stored. |
Responsible AI
An AI system includes not only the technology, but also the people who use it, the people who are affected by it, and the environment in which it's deployed. Read the transparency notes to learn about responsible AI use and deployment in your systems.
- Transparency note and use cases
- Characteristics and limitations
- Limited access
- General guidelines
- Data, privacy, and security