กิจกรรม
17 มี.ค. 21 - 21 มี.ค. 10
แอปอัจฉริยะ เข้าร่วมชุด meetup เพื่อสร้างโซลูชัน AI ที่ปรับขนาดได้ตามกรณีการใช้งานจริงกับนักพัฒนาและผู้เชี่ยวชาญร่วมกัน
ลงทะเบียนตอนนี้เบราว์เซอร์นี้ไม่ได้รับการสนับสนุนอีกต่อไป
อัปเกรดเป็น Microsoft Edge เพื่อใช้ประโยชน์จากคุณลักษณะล่าสุด เช่น การอัปเดตความปลอดภัยและการสนับสนุนด้านเทคนิค
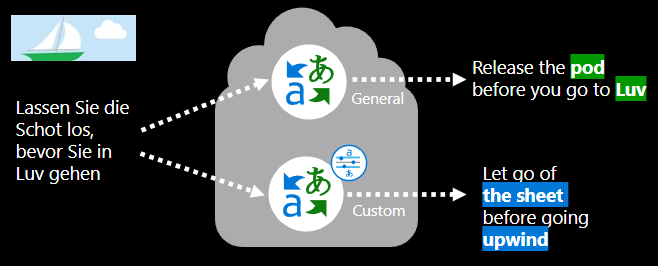
Azure AI Custom Translator enables you to a build translation system that reflects your business, industry, and domain-specific terminology and style. Training and deploying a custom system is easy and doesn't require any programming skills. The customized translation system seamlessly integrates into your existing applications, workflows, and websites and is available on Azure through the same cloud-based Microsoft Text Translation API service that powers billions of translations every day.
The platform enables users to build and publish custom translation systems to and from English. The Custom Translator supports more than 60 languages that map directly to the languages available for Neural machine translation (NMT). For a complete list, see Translator language support.
A well-trained custom translation model provides more accurate domain-specific translations because it relies on previously translated in-domain documents to learn preferred translations. Translator uses these terms and phrases in context to produce fluent translations in the target language while respecting context-dependent grammar.
Training a full custom translation model requires a substantial amount of data. If you don't have at least 10,000 sentences of previously trained documents, you can't train a full-language translation model. However, you can either train a dictionary-only model or use the high-quality, out-of-the-box translations available with the Text Translation API.
Building a custom translation model requires:
Understanding your use-case.
Obtaining in-domain translated data (preferably human translated).
Assessing translation quality or target language translations.
Having clarity on your use-case and what success looks like is the first step towards sourcing proficient training data. Here are a few considerations:
Is your desired outcome specified and how is it measured?
Is your business domain identified?
Do you have in-domain sentences of similar terminology and style?
Does your use-case involve multiple domains? If yes, should you build one translation system or multiple systems?
Do you have requirements impacting regional data residency at-rest and in-transit?
Are the target users in one or multiple regions?
Finding in-domain quality data is often a challenging task that varies based on user classification. Here are some questions you can ask yourself as you evaluate what data is available to you:
Does your company have previous translation data available that you can use? Enterprises often have a wealth of translation data accumulated over many years of using human translation.
Do you have a vast amount of monolingual data? Monolingual data is data in only one language. If so, can you get translations for this data?
Can you crawl online portals to collect source sentences and synthesize target sentences?
| Source | What it does | Rules to follow |
|---|---|---|
| Bilingual training documents | Teaches the system your terminology and style. | Be liberal. Any in-domain human translation is better than machine translation. Add and remove documents as you go and try to improve the BLEU score. |
| Tuning documents | Trains the Neural Machine Translation parameters. | Be strict. Compose them to be optimally representative of what you are going to translate in the future. |
| Test documents | Calculate the BLEU score. | Be strict. Compose test documents to be optimally representative of what you plan to translate in the future. |
| Phrase dictionary | Forces the given translation 100% of the time. | Be restrictive. A phrase dictionary is case-sensitive and any word or phrase listed is translated in the way you specify. In many cases, it's better to not use a phrase dictionary and let the system learn. |
| Sentence dictionary | Forces the given translation 100% of the time. | Be strict. A sentence dictionary is case-insensitive and good for common in domain short sentences. For a sentence dictionary match to occur, the entire submitted sentence must match the source dictionary entry. If only a portion of the sentence matches, the entry doesn't match. |
BLEU (Bilingual Evaluation Understudy) is an algorithm for evaluating the precision or accuracy of text that is machine translated from one language to another. Azure AI Custom Translator uses the BLEU metric as one way of conveying translation accuracy.
A BLEU score is a number between zero and 100. A score of zero indicates a low quality translation where nothing in the translation matched the reference. A score of 100 indicates a perfect translation that is identical to the reference. It's not necessary to attain a score of 100 - a BLEU score between 40 and 60 indicates a high-quality translation.
Tuning and test sentences are optimally representative of what you plan to translate in the future. If you don't submit any tuning or testing data, Azure AI Custom Translator automatically excludes sentences from your training documents to use as tuning and test data.
| System-generated | Manual-selection |
|---|---|
| Convenient. | Enables fine-tuning for your future needs. |
| Good, if you know that your training data is representative of what you are planning to translate. | Provides more freedom to compose your training data. |
| Easy to redo when you grow or shrink the domain. | Allows for more data and better domain coverage. |
| Changes each training run. | Remains static over repeated training runs |
To prepare for training, documents undergo a series of processing and filtering steps. Knowledge of the filtering process can help with understanding the sentence count displayed as well as the steps you can take to prepare training documents for training with Azure AI Custom Translator. The filtering steps are as follows:
If your document isn't in XLIFF, XLSX, TMX, or ALIGN format, Azure AI Custom Translator aligns the sentences of your source and target documents to each other, sentence-by-sentence. Translator doesn't perform document alignment—it follows your naming convention for the documents to find a matching document in the other language. Within the source text, Azure AI Custom Translator tries to find the corresponding sentence in the target language. It uses document markup like embedded HTML tags to help with the alignment.
If you see a large discrepancy between the number of sentences in the source and target documents, your source document can't be parallel, or couldn't be aligned. The document pairs with a large difference (>10%) of sentences on each side warrant a second look to make sure they're indeed parallel.
Tuning and testing data is optional. If you don't provide it, the system removes an appropriate percentage from your training documents to use for tuning and testing. The removal happens dynamically as part of the training process. Since this step occurs as part of training, your uploaded documents aren't affected. You can see the final used sentence counts for each category of data—training, tuning, testing, and dictionary—on the Model details page after training succeeds.
Replaces multiple sentence-end punctuation characters with a single instance. Japanese character normalization.
Converts full width letters and digits to half-width characters.
Transforms unescaped tags into escaped tags:
| Tag | Becomes |
|---|---|
| < | &lt; |
| > | &gt; |
| & | &amp; |
Azure AI Custom Translator removes sentences that contain Unicode character U+FFFD. The character U+FFFD indicates a failed encoding conversion.
After your model is successfully trained, you can view the model's BLEU score and baseline model BLEU score on the model details page. We use the same set of test data to generate both the model's BLEU score and the baseline BLEU score. This data helps you make an informed decision regarding which model would be better for your use-case.
กิจกรรม
17 มี.ค. 21 - 21 มี.ค. 10
แอปอัจฉริยะ เข้าร่วมชุด meetup เพื่อสร้างโซลูชัน AI ที่ปรับขนาดได้ตามกรณีการใช้งานจริงกับนักพัฒนาและผู้เชี่ยวชาญร่วมกัน
ลงทะเบียนตอนนี้การฝึกอบรม
โมดูล
ตัวแปลเป็นบริการระบบคลาวด์ที่ใช้ AI เพื่อแปลข้อความและเอกสารระหว่างภาษาในแบบใกล้เคียงเวลาจริงอย่างเชื่อถือได้ คุณสามารถเพิ่มประสบการณ์ผู้ใช้หลายภาษาในแอปของคุณใน 90 ภาษาและภาษาเฉพาะพร้อมกับการแปลข้อความฟรีด้วยระบบปฏิบัติการใด ๆ นักแปลยังมีรูปแบบการแปลที่สามารถปรับแต่งได้ซึ่งสามารถทําความเข้าใจคําศัพท์หรือคําสรรพนามเฉพาะของอุตสาหกรรมได้ดีขึ้น
ใบรับรอง
ได้รับการรับรองจาก Microsoft: Azure Data Scientist Associate - Certifications
จัดการการนําเข้าข้อมูลและเตรียมการ การฝึกอบรมแบบจําลองและการปรับใช้ และการตรวจสอบโซลูชันการเรียนรู้ของเครื่องด้วย Python, Azure Machine Learning และ MLflow
เอกสาร
Quickstart: Build, deploy, and use a custom model - Azure AI Custom Translator - Azure AI services
A step-by-step guide to building a translation system using the Azure AI Custom Translator portal v2.
Train an Azure AI Custom Translator model - Azure AI services
How to train a custom model
Frequently asked questions - Azure AI Custom Translator - Azure AI services
This article contains answers to frequently asked questions about the Azure AI Custom Translator.