หมายเหตุ
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลอง ลงชื่อเข้าใช้หรือเปลี่ยนไดเรกทอรีได้
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลองเปลี่ยนไดเรกทอรีได้
The Azure SQL trigger uses SQL change tracking functionality to monitor a SQL table for changes and trigger a function when a row is created, updated, or deleted. For configuration details for change tracking for use with the Azure SQL trigger, see Set up change tracking. For information on setup details of the Azure SQL extension for Azure Functions, see the SQL binding overview.
The Azure SQL trigger scaling decisions for the Consumption and Premium plans are done via target-based scaling. For more information, see Target-based scaling and review the Azure Functions hosting options.
Note
Support for Consumption plans requires release v3.1.284 or later of the Azure SQL bindings for Azure Functions.
Functionality Overview
The Azure SQL trigger binding uses a polling loop to check for changes, triggering the user function when changes are detected. At a high level, the loop looks like this:
while (true) {
1. Get list of changes on table - up to a maximum number controlled by the Sql_Trigger_MaxBatchSize setting
2. Trigger function with list of changes
3. Wait for delay controlled by Sql_Trigger_PollingIntervalMs setting
}
Changes are processed in the order that their changes were made, with the oldest changes being processed first. A couple notes about change processing:
- If changes to multiple rows are made at once the exact order that they’re sent to the function is based on the order returned by the CHANGETABLE function
- Changes are "batched" together for a row. If multiple changes are made to a row between each iteration of the loop then only a single change entry exists for that row which will show the difference between the last processed state and the current state
- If changes are made to a set of rows, and then another set of changes are made to half of those same rows, then the half of the rows that weren't changed a second time are processed first. This processing logic is due to the above note with the changes being batched - the trigger will only see the "last" change made and use that for the order it processes them in
Note
Azure SQL change tracking can detect row-level changes in tables that use encryption technologies such as Always Encrypted or Transparent Data Encryption (TDE). However, the Azure SQL trigger doesn’t decrypt or expose encrypted column values in the change payload. The trigger can detect that a change occurred but can’t access the decrypted data for those columns.
For more information on change tracking and how it's used by applications such as Azure SQL triggers, see work with change tracking .
Important
For optimal security, you should use Microsoft Entra ID with managed identities for connections between Functions and Azure SQL Database. Managed identities make your app more secure by eliminating secrets from your application deployments, such as credentials in the connection strings, server names, and ports being used. You can learn how to use managed identities in this tutorial, Connect a function app to Azure SQL with managed identity and SQL bindings.
Example usage
More samples for the Azure SQL trigger are available in the GitHub repository.
The example refers to a ToDoItem class and a corresponding database table:
namespace AzureSQL.ToDo
{
public class ToDoItem
{
public Guid Id { get; set; }
public int? order { get; set; }
public string title { get; set; }
public string url { get; set; }
public bool? completed { get; set; }
}
}
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
Change tracking is enabled on the database and on the table:
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
The SQL trigger binds to a IReadOnlyList<SqlChange<T>>, a list of SqlChange objects each with two properties:
- Item: the item that was changed. The type of the item should follow the table schema as seen in the
ToDoItemclass. - Operation: a value from
SqlChangeOperationenum. The possible values areInsert,Update, andDelete.
The following example shows a C# function that is invoked when there are changes to the ToDo table:
using System;
using System.Collections.Generic;
using Microsoft.Azure.Functions.Worker;
using Microsoft.Azure.Functions.Worker.Extensions.Sql;
using Microsoft.Extensions.Logging;
using Newtonsoft.Json;
namespace AzureSQL.ToDo
{
public static class ToDoTrigger
{
[Function("ToDoTrigger")]
public static void Run(
[SqlTrigger("[dbo].[ToDo]", "SqlConnectionString")]
IReadOnlyList<SqlChange<ToDoItem>> changes,
FunctionContext context)
{
var logger = context.GetLogger("ToDoTrigger");
foreach (SqlChange<ToDoItem> change in changes)
{
ToDoItem toDoItem = change.Item;
logger.LogInformation($"Change operation: {change.Operation}");
logger.LogInformation($"Id: {toDoItem.Id}, Title: {toDoItem.title}, Url: {toDoItem.url}, Completed: {toDoItem.completed}");
}
}
}
}
Example usage
More samples for the Azure SQL trigger are available in the GitHub repository.
The example refers to a ToDoItem class, a SqlChangeToDoItem class, a SqlChangeOperation enum, and a corresponding database table:
In a separate file ToDoItem.java:
package com.function;
import java.util.UUID;
public class ToDoItem {
public UUID Id;
public int order;
public String title;
public String url;
public boolean completed;
public ToDoItem() {
}
public ToDoItem(UUID Id, int order, String title, String url, boolean completed) {
this.Id = Id;
this.order = order;
this.title = title;
this.url = url;
this.completed = completed;
}
}
In a separate file SqlChangeToDoItem.java:
package com.function;
public class SqlChangeToDoItem {
public ToDoItem item;
public SqlChangeOperation operation;
public SqlChangeToDoItem() {
}
public SqlChangeToDoItem(ToDoItem Item, SqlChangeOperation Operation) {
this.Item = Item;
this.Operation = Operation;
}
}
In a separate file SqlChangeOperation.java:
package com.function;
import com.google.gson.annotations.SerializedName;
public enum SqlChangeOperation {
@SerializedName("0")
Insert,
@SerializedName("1")
Update,
@SerializedName("2")
Delete;
}
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
Change tracking is enabled on the database and on the table:
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
The SQL trigger binds to a SqlChangeToDoItem[], an array of SqlChangeToDoItem objects each with two properties:
- item: the item that was changed. The type of the item should follow the table schema as seen in the
ToDoItemclass. - operation: a value from
SqlChangeOperationenum. The possible values areInsert,Update, andDelete.
The following example shows a Java function that is invoked when there are changes to the ToDo table:
package com.function;
import com.microsoft.azure.functions.ExecutionContext;
import com.microsoft.azure.functions.annotation.FunctionName;
import com.microsoft.azure.functions.sql.annotation.SQLTrigger;
import com.function.Common.SqlChangeToDoItem;
import com.google.gson.Gson;
import java.util.logging.Level;
public class ProductsTrigger {
@FunctionName("ToDoTrigger")
public void run(
@SQLTrigger(
name = "todoItems",
tableName = "[dbo].[ToDo]",
connectionStringSetting = "SqlConnectionString")
SqlChangeToDoItem[] todoItems,
ExecutionContext context) {
context.getLogger().log(Level.INFO, "SQL Changes: " + new Gson().toJson(changes));
}
}
Example usage
More samples for the Azure SQL trigger are available in the GitHub repository.
The example refers to a ToDoItem database table:
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
Change tracking is enabled on the database and on the table:
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
The SQL trigger binds to todoChanges, a list of objects each with two properties:
- item: the item that was changed. The structure of the item will follow the table schema.
- operation: the possible values are
Insert,Update, andDelete.
The following example shows a PowerShell function that is invoked when there are changes to the ToDo table.
The following is binding data in the function.json file:
{
"name": "todoChanges",
"type": "sqlTrigger",
"direction": "in",
"tableName": "dbo.ToDo",
"connectionStringSetting": "SqlConnectionString"
}
The configuration section explains these properties.
The following is sample PowerShell code for the function in the run.ps1 file:
using namespace System.Net
param($todoChanges)
# The output is used to inspect the trigger binding parameter in test methods.
# Use -Compress to remove new lines and spaces for testing purposes.
$changesJson = $todoChanges | ConvertTo-Json -Compress
Write-Host "SQL Changes: $changesJson"
Example usage
More samples for the Azure SQL trigger are available in the GitHub repository.
The example refers to a ToDoItem database table:
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
Change tracking is enabled on the database and on the table:
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
The SQL trigger binds todoChanges, an array of objects each with two properties:
- item: the item that was changed. The structure of the item will follow the table schema.
- operation: the possible values are
Insert,Update, andDelete.
The following example shows a JavaScript function that is invoked when there are changes to the ToDo table.
The following is binding data in the function.json file:
{
"name": "todoChanges",
"type": "sqlTrigger",
"direction": "in",
"tableName": "dbo.ToDo",
"connectionStringSetting": "SqlConnectionString"
}
The configuration section explains these properties.
The following is sample JavaScript code for the function in the index.js file:
module.exports = async function (context, todoChanges) {
context.log(`SQL Changes: ${JSON.stringify(todoChanges)}`)
}
Example usage
More samples for the Azure SQL trigger are available in the GitHub repository.
The example refers to a ToDoItem database table:
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
Change tracking is enabled on the database and on the table:
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
The SQL trigger binds to a variable todoChanges, a list of objects each with two properties:
- item: the item that was changed. The structure of the item will follow the table schema.
- operation: the possible values are
Insert,Update, andDelete.
The following example shows a Python function that is invoked when there are changes to the ToDo table.
The following is sample python code for the function_app.py file:
import json
import logging
import azure.functions as func
app = func.FunctionApp()
@app.function_name(name="ToDoTrigger")
@app.sql_trigger(arg_name="todo",
table_name="ToDo",
connection_string_setting="SqlConnectionString")
def todo_trigger(todo: str) -> None:
logging.info("SQL Changes: %s", json.loads(todo))
Attributes
The C# library uses the SqlTrigger attribute to declare the SQL trigger on the function, which has the following properties:
| Attribute property | Description |
|---|---|
| TableName | Required. The name of the table monitored by the trigger. |
| ConnectionStringSetting | Required. The name of an app setting that contains the connection string for the database containing the table monitored for changes. The connection string setting name corresponds to the application setting (in local.settings.json for local development) that contains the connection string to the Azure SQL or SQL Server instance. |
| LeasesTableName | Optional. Name of the table used to store leases. If not specified, the leases table name will be Leases_{FunctionId}_{TableId}. More information on how this is generated can be found here. |
Annotations
In the Java functions runtime library, use the @SQLTrigger annotation (com.microsoft.azure.functions.sql.annotation.SQLTrigger) on parameters whose value would come from Azure SQL. This annotation supports the following elements:
| Element | Description |
|---|---|
| name | Required. The name of the parameter that the trigger binds to. |
| tableName | Required. The name of the table monitored by the trigger. |
| connectionStringSetting | Required. The name of an app setting that contains the connection string for the database containing the table monitored for changes. The connection string setting name corresponds to the application setting (in local.settings.json for local development) that contains the connection string to the Azure SQL or SQL Server instance. |
| LeasesTableName | Optional. Name of the table used to store leases. If not specified, the leases table name will be Leases_{FunctionId}_{TableId}. More information on how this is generated can be found here. |
Configuration
The following table explains the binding configuration properties that you set in the function.json file.
| function.json property | Description |
|---|---|
| name | Required. The name of the parameter that the trigger binds to. |
| type | Required. Must be set to sqlTrigger. |
| direction | Required. Must be set to in. |
| tableName | Required. The name of the table monitored by the trigger. |
| connectionStringSetting | Required. The name of an app setting that contains the connection string for the database containing the table monitored for changes. The connection string setting name corresponds to the application setting (in local.settings.json for local development) that contains the connection string to the Azure SQL or SQL Server instance. |
| LeasesTableName | Optional. Name of the table used to store leases. If not specified, the leases table name will be Leases_{FunctionId}_{TableId}. More information on how this is generated can be found here. |
Optional Configuration
The following optional settings can be configured for the SQL trigger for local development or for cloud deployments.
host.json
This section describes the configuration settings available for this binding in version 2.x and later. Settings in the host.json file apply to all functions in a function app instance. For more information about function app configuration settings, see host.json reference for Azure Functions.
| Setting | Default | Description |
|---|---|---|
| MaxBatchSize | 100 | The maximum number of changes processed with each iteration of the trigger loop before being sent to the triggered function. |
| PollingIntervalMs | 1000 | The delay in milliseconds between processing each batch of changes. (1000 ms is 1 second) |
| MaxChangesPerWorker | 1000 | The upper limit on the number of pending changes in the user table that are allowed per application-worker. If the count of changes exceeds this limit, it might result in a scale-out. The setting only applies for Azure Function Apps with runtime driven scaling enabled. |
Example host.json file
Here is an example host.json file with the optional settings:
{
"version": "2.0",
"extensions": {
"Sql": {
"MaxBatchSize": 300,
"PollingIntervalMs": 1000,
"MaxChangesPerWorker": 100
}
},
"logging": {
"applicationInsights": {
"samplingSettings": {
"isEnabled": true,
"excludedTypes": "Request"
}
},
"logLevel": {
"default": "Trace"
}
}
}
local.setting.json
The local.settings.json file stores app settings and settings used by local development tools. Settings in the local.settings.json file are used only when you're running your project locally. When you publish your project to Azure, be sure to also add any required settings to the app settings for the function app.
Important
Because the local.settings.json may contain secrets, such as connection strings, you should never store it in a remote repository. Tools that support Functions provide ways to synchronize settings in the local.settings.json file with the app settings in the function app to which your project is deployed.
| Setting | Default | Description |
|---|---|---|
| Sql_Trigger_BatchSize | 100 | The maximum number of changes processed with each iteration of the trigger loop before being sent to the triggered function. |
| Sql_Trigger_PollingIntervalMs | 1000 | The delay in milliseconds between processing each batch of changes. (1000 ms is 1 second) |
| Sql_Trigger_MaxChangesPerWorker | 1000 | The upper limit on the number of pending changes in the user table that are allowed per application-worker. If the count of changes exceeds this limit, it might result in a scale-out. The setting only applies for Azure Function Apps with runtime driven scaling enabled. |
Example local.settings.json file
Here is an example local.settings.json file with the optional settings:
{
"IsEncrypted": false,
"Values": {
"AzureWebJobsStorage": "UseDevelopmentStorage=true",
"FUNCTIONS_WORKER_RUNTIME": "dotnet",
"SqlConnectionString": "",
"Sql_Trigger_MaxBatchSize": 300,
"Sql_Trigger_PollingIntervalMs": 1000,
"Sql_Trigger_MaxChangesPerWorker": 100
}
}
Set up change tracking (required)
Setting up change tracking for use with the Azure SQL trigger requires two steps. These steps can be completed from any SQL tool that supports running queries, including Visual Studio Code, Azure Data Studio or SQL Server Management Studio.
Enable change tracking on the SQL database, substituting
your database namewith the name of the database where the table to be monitored is located:ALTER DATABASE [your database name] SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);The
CHANGE_RETENTIONoption specifies the time period for which change tracking information (change history) is kept. The retention of change history by the SQL database might affect trigger functionality. For example, if the Azure Function is turned off for several days and then resumed, the database will contain the changes that occurred in past two days in the above setup example.The
AUTO_CLEANUPoption is used to enable or disable the clean-up task that removes old change tracking information. If a temporary problem that prevents the trigger from running, turning off auto cleanup can be useful to pause the removal of information older than the retention period until the problem is resolved.More information on change tracking options is available in the SQL documentation.
Enable change tracking on the table, substituting
your table namewith the name of the table to be monitored (changing the schema if appropriate):ALTER TABLE [dbo].[your table name] ENABLE CHANGE_TRACKING;The trigger needs to have read access on the table being monitored for changes and to the change tracking system tables. Each function trigger has an associated change tracking table and leases table in a schema
az_func. These tables are created by the trigger if they don't yet exist. More information on these data structures is available in the Azure SQL binding library documentation.
Enable runtime-driven scaling
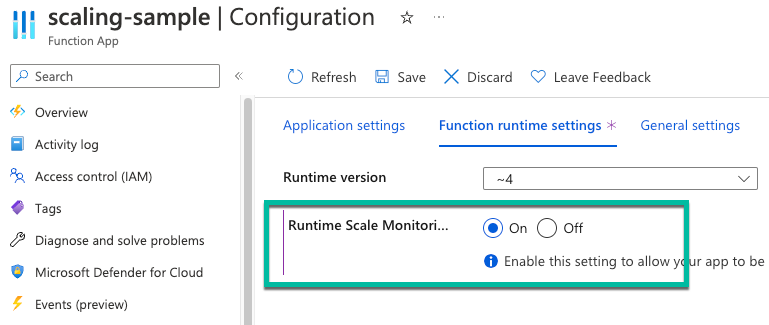
Optionally, your functions can scale automatically based on the number of changes that are pending to be processed in the user table. To allow your functions to scale properly on the Premium plan when using SQL triggers, you need to enable runtime scale monitoring.
In the Azure portal, in your function app, select Configuration.
On the Function runtime settings tab, for Runtime Scale Monitoring, select On.
Retry support
Further information on the SQL trigger retry support and leases tables is available in the GitHub repository.
Startup retries
If an exception occurs during startup then the host runtime automatically attempts to restart the trigger listener with an exponential backoff strategy. These retries continue until either the listener is successfully started or the startup is canceled.
Broken connection retries
If the function successfully starts but then an error causes the connection to break (such as the server going offline) then the function continues to try and reopen the connection until the function is either stopped or the connection succeeds. If the connection is successfully re-established then it picks up processing changes where it left off.
Note that these retries are outside the built-in idle connection retry logic that SqlClient has which can be configured with the ConnectRetryCount and ConnectRetryInterval connection string options. The built-in idle connection retries are attempted first and if those fail to reconnect then the trigger binding attempts to re-establish the connection itself.
Function exception retries
If an exception occurs in the user function when processing changes then the batch of rows currently being processed are retried again in 60 seconds. Other changes are processed as normal during this time, but the rows in the batch that caused the exception are ignored until the timeout period has elapsed.
If the function execution fails five times in a row for a given row then that row is completely ignored for all future changes. Because the rows in a batch aren't deterministic, rows in a failed batch might end up in different batches in subsequent invocations. This means that not all rows in the failed batch will necessarily be ignored. If other rows in the batch were the ones causing the exception, the "good" rows might end up in a different batch that doesn't fail in future invocations.