Chaos experiments
In Azure Chaos Studio, you create and run chaos experiments. A chaos experiment is an Azure resource that describes the faults that should be run and the resources those faults should be run against.
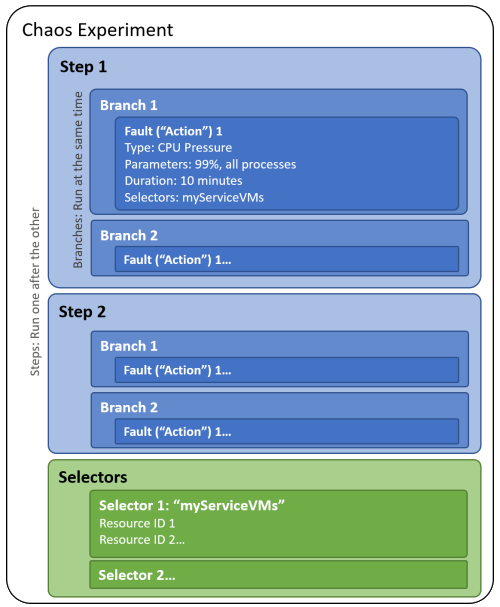
An experiment is divided into two sections:
Selectors: Selectors are groups of target resources that have faults or other actions run against them. A selector allows you to logically group resources for reuse across multiple actions.
For example, you might have a selector named
AllNonProdEastUSVMs, in which you've added all the nonproduction virtual machines in East US. You could then apply CPU pressure followed by virtual memory pressure to those virtual machines by referencing the selector.Logic: The rest of the experiment describes how and when to run faults. An experiment is organized into steps that run one after the other. Each step has one or more branches that run at the same time. Steps and branches allow you to inject multiple faults across resources in your environment in parallel.
Each branch has one or more actions, which are either the faults you want to run or time delays. Faults are actions that cause some disruption. Most faults take one or more parameters, such as the duration to run the fault or the amount of stress to apply.
Cross-subscription and cross-tenant experiments
A chaos experiment is an Azure resource deployed to a subscription, resource group, and region. You can use the Azure portal or the Chaos Studio REST API to create, update, start, cancel, and view the status of an experiment.
Chaos experiments can target resources in a different subscription than the experiment if the subscription is within the same Azure tenant. Chaos experiments can target resources in a different region than the experiment if the region is a supported region for Chaos Studio.
Documenting chaos experiments
There are several key aspects of your chaos experimentation process you can track and modify over time. One approach is to use work items in Azure Boards or in GitHub Projects. By creating dedicated work items for each experiment, you can track the details, progress, and outcomes of your experiments in a structured manner. This documentation can include information such as the purpose of the experiment, the expected outcomes, the steps followed, the resources involved, and any observations or learnings from the experiment.
| Item | Details |
|---|---|
| Hypothesis | Define the objective and expected outcomes of the experiment |
| Target Scope | Identify which part of the system will be subjected to chaos experiments (e.g., network, database, application layer). |
| Duration | Specify the time frame for the chaos experiment. |
| Target | Determine the specific targets or components within the system. |
| Environment | Define whether the experiment will be conducted in a production, staging, or development environment. |
| Observations | Record any data or behavior observed during the experiment. |
| Results | Summarize the findings and outcomes of the experiment. |
| Action Items | List any action items or steps to be taken based on the results. |
The hypothesis is a crucial aspect of a chaos experiment as it defines the objective and expected outcomes of the experiment. It helps in testing the system's ability to handle unexpected disruptions effectively. By formulating a clear hypothesis, you can focus your experiment on specific areas of the system and gather meaningful data to evaluate its resilience. By leveraging the features of Azure Boards or GitHub Projects, you can collaborate with your team, assign tasks, set due dates, and track the overall progress of your chaos engineering initiatives.
Next steps
Now that you understand what a chaos experiment is you're ready to: