กิจกรรม
17 มี.ค. 21 - 21 มี.ค. 10
แอปอัจฉริยะ เข้าร่วมชุด meetup เพื่อสร้างโซลูชัน AI ที่ปรับขนาดได้ตามกรณีการใช้งานจริงกับนักพัฒนาและผู้เชี่ยวชาญร่วมกัน
ลงทะเบียนตอนนี้เบราว์เซอร์นี้ไม่ได้รับการสนับสนุนอีกต่อไป
อัปเกรดเป็น Microsoft Edge เพื่อใช้ประโยชน์จากคุณลักษณะล่าสุด เช่น การอัปเดตความปลอดภัยและการสนับสนุนด้านเทคนิค
APPLIES TO: ![]() NoSQL
NoSQL
While schema-free databases, like Azure Cosmos DB, make it super easy to store and query unstructured and semi-structured data, you should spend some time thinking about your data model to get the most of the service in terms of performance and scalability and lowest cost.
How is data going to be stored? How is your application going to retrieve and query data? Is your application read-heavy, or write-heavy?
After reading this article, you'll be able to answer the following questions:
Azure Cosmos DB saves documents in JSON. Which means it's necessary to carefully determine whether it's necessary to convert numbers into strings before storing them in json or not. All numbers should ideally be converted into a String, if there's any chance that they are outside the boundaries of double precision numbers according to IEEE 754 binary64. The Json specification calls out the reasons why using numbers outside of this boundary in general is a bad practice in JSON due to likely interoperability problems. These concerns are especially relevant for the partition key column, because it's immutable and requires data migration to change it later.
When you start modeling data in Azure Cosmos DB try to treat your entities as self-contained items represented as JSON documents.
For comparison, let's first see how we might model data in a relational database. The following example shows how a person might be stored in a relational database.
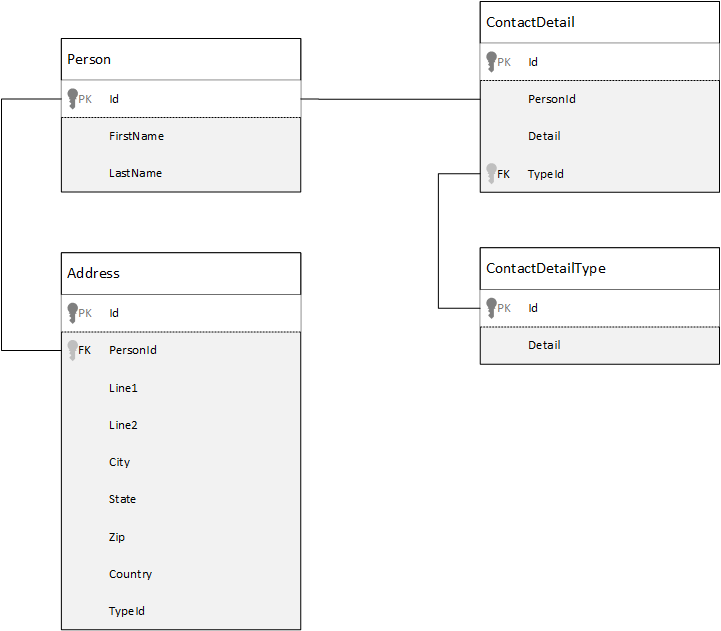
The strategy, when working with relational databases, is to normalize all your data. Normalizing your data typically involves taking an entity, such as a person, and breaking it down into discrete components. In the example, a person might have multiple contact detail records, and multiple address records. Contact details can be further broken down by further extracting common fields like a type. The same applies to address, each record can be of type Home or Business.
The guiding premise when normalizing data is to avoid storing redundant data on each record and rather refer to data. In this example, to read a person, with all their contact details and addresses, you need to use JOINS to effectively compose back (or denormalize) your data at run time.
SELECT p.FirstName, p.LastName, a.City, cd.Detail
FROM Person p
JOIN ContactDetail cd ON cd.PersonId = p.Id
JOIN ContactDetailType cdt ON cdt.Id = cd.TypeId
JOIN Address a ON a.PersonId = p.Id
Write operations across many individual tables are required to update a single person's contact details and addresses.
Now let's take a look at how we would model the same data as a self-contained entity in Azure Cosmos DB.
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"addresses": [
{
"line1": "100 Some Street",
"line2": "Unit 1",
"city": "Seattle",
"state": "WA",
"zip": 98012
}
],
"contactDetails": [
{"email": "thomas@andersen.com"},
{"phone": "+1 555 555-5555", "extension": 5555}
]
}
Using this approach we've denormalized the person record, by embedding all the information related to this person, such as their contact details and addresses, into a single JSON document. In addition, because we're not confined to a fixed schema we have the flexibility to do things like having contact details of different shapes entirely.
Retrieving a complete person record from the database is now a single read operation against a single container and for a single item. Updating the contact details and addresses of a person record is also a single write operation against a single item.
By denormalizing data, your application might need to issue fewer queries and updates to complete common operations.
In general, use embedded data models when:
หมายเหตุ
Typically denormalized data models provide better read performance.
While the rule of thumb in Azure Cosmos DB is to denormalize everything and embed all data into a single item, this can lead to some situations that should be avoided.
Take this JSON snippet.
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"comments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
…
{"id": 100001, "author": "jane", "comment": "and on we go ..."},
…
{"id": 1000000001, "author": "angry", "comment": "blah angry blah angry"},
…
{"id": ∞ + 1, "author": "bored", "comment": "oh man, will this ever end?"},
]
}
This might be what a post entity with embedded comments would look like if we were modeling a typical blog, or CMS, system. The problem with this example is that the comments array is unbounded, meaning that there's no (practical) limit to the number of comments any single post can have. This might become a problem as the size of the item could grow infinitely large so is a design you should avoid.
As the size of the item grows the ability to transmit the data over the wire and reading and updating the item, at scale, will be impacted.
In this case, it would be better to consider the following data model.
Post item:
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"recentComments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
{"id": 3, "author": "jane", "comment": "....."}
]
}
Comment items:
[
{"id": 4, "postId": "1", "author": "anon", "comment": "more goodness"},
{"id": 5, "postId": "1", "author": "bob", "comment": "tails from the field"},
...
{"id": 99, "postId": "1", "author": "angry", "comment": "blah angry blah angry"},
{"id": 100, "postId": "2", "author": "anon", "comment": "yet more"},
...
{"id": 199, "postId": "2", "author": "bored", "comment": "will this ever end?"}
]
This model has a document for each comment with a property that contains the post identifier. This allows posts to contain any number of comments and can grow efficiently. Users wanting to see more than the most recent comments would query this container passing the postId, which should be the partition key for the comments container.
Another case where embedding data isn't a good idea is when the embedded data is used often across items and will change frequently.
Take this JSON snippet.
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{
"numberHeld": 100,
"stock": { "symbol": "zbzb", "open": 1, "high": 2, "low": 0.5 }
},
{
"numberHeld": 50,
"stock": { "symbol": "xcxc", "open": 89, "high": 93.24, "low": 88.87 }
}
]
}
This could represent a person's stock portfolio. We have chosen to embed the stock information into each portfolio document. In an environment where related data is changing frequently, like a stock trading application, embedding data that changes frequently is going to mean that you're constantly updating each portfolio document every time a stock is traded.
Stock zbzb might be traded many hundreds of times in a single day and thousands of users could have zbzb on their portfolio. With a data model like the example, we would have to update many thousands of portfolio documents many times every day leading to a system that won't scale well.
Embedding data works nicely for many cases but there are scenarios when denormalizing your data cause more problems than it's worth. So what do we do now?
Relational databases aren't the only place where you can create relationships between entities. In a document database, you might have information in one document that relates to data in other documents. We don't recommend building systems that would be better suited to a relational database in Azure Cosmos DB, or any other document database, but simple relationships are fine and might be useful.
In the JSON we chose to use the example of a stock portfolio from earlier but this time we refer to the stock item on the portfolio instead of embedding it. This way, when the stock item changes frequently throughout the day the only document that needs to be updated is the single stock document.
Person document:
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{ "numberHeld": 100, "stockId": 1},
{ "numberHeld": 50, "stockId": 2}
]
}
Stock documents:
{
"id": "1",
"symbol": "zbzb",
"open": 1,
"high": 2,
"low": 0.5,
"vol": 11970000,
"mkt-cap": 42000000,
"pe": 5.89
},
{
"id": "2",
"symbol": "xcxc",
"open": 89,
"high": 93.24,
"low": 88.87,
"vol": 2970200,
"mkt-cap": 1005000,
"pe": 75.82
}
An immediate downside to this approach though is if your application is required to show information about each stock that is held when displaying a person's portfolio; in this case you would need to make multiple trips to the database to load the information for each stock document. Here we've made a decision to improve the efficiency of write operations, which happen frequently throughout the day, but in turn compromised on the read operations that potentially have less impact on the performance of this particular system.
หมายเหตุ
Normalized data models can require more round trips to the server.
Because there's currently no concept of a constraint, foreign-key or otherwise, any inter-document relationships that you have in documents are effectively "weak links" and won't be verified by the database itself. If you want to ensure that the data a document is referring to actually exists, then you need to do this in your application, or by using server-side triggers or stored procedures on Azure Cosmos DB.
In general, use normalized data models when:
หมายเหตุ
Typically normalizing provides better write performance.
The growth of the relationship helps determine in which document to store the reference.
If we observe the JSON that models publishers and books.
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press",
"books": [ 1, 2, 3, ..., 100, ..., 1000]
}
Book documents:
{"id": "1", "name": "Azure Cosmos DB 101" }
{"id": "2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "3", "name": "Taking over the world one JSON doc at a time" }
...
{"id": "100", "name": "Learn about Azure Cosmos DB" }
...
{"id": "1000", "name": "Deep Dive into Azure Cosmos DB" }
If the number of the books per publisher is small with limited growth, then storing the book reference inside the publisher document might be useful. However, if the number of books per publisher is unbounded, then this data model would lead to mutable, growing arrays, as in the example publisher document.
Switching things around a bit would result in a model that still represents the same data but now avoids these large mutable collections.
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press"
}
Book documents:
{"id": "1","name": "Azure Cosmos DB 101", "pub-id": "mspress"}
{"id": "2","name": "Azure Cosmos DB for RDBMS Users", "pub-id": "mspress"}
{"id": "3","name": "Taking over the world one JSON doc at a time", "pub-id": "mspress"}
...
{"id": "100","name": "Learn about Azure Cosmos DB", "pub-id": "mspress"}
...
{"id": "1000","name": "Deep Dive into Azure Cosmos DB", "pub-id": "mspress"}
In this example, we've dropped the unbounded collection on the publisher document. Instead we just have a reference to the publisher on each book document.
In a relational database many-to-many relationships are often modeled with join tables, which just join records from other tables together.
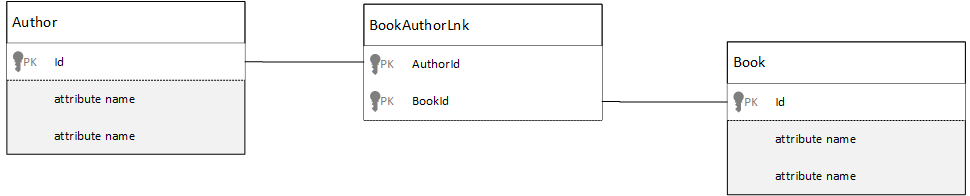
You might be tempted to replicate the same thing using documents and produce a data model that looks similar to the following.
Author documents:
{"id": "a1", "name": "Thomas Andersen" }
{"id": "a2", "name": "William Wakefield" }
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101" }
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "b3", "name": "Taking over the world one JSON doc at a time" }
{"id": "b4", "name": "Learn about Azure Cosmos DB" }
{"id": "b5", "name": "Deep Dive into Azure Cosmos DB" }
Joining documents:
{"authorId": "a1", "bookId": "b1" }
{"authorId": "a2", "bookId": "b1" }
{"authorId": "a1", "bookId": "b2" }
{"authorId": "a1", "bookId": "b3" }
This would work. However, loading either an author with their books, or loading a book with its author, would always require at least two extra queries against the database. One query to the joining document and then another query to fetch the actual document being joined.
If this join is only gluing together two pieces of data, then why not drop it completely? Consider the following example.
Author documents:
{"id": "a1", "name": "Thomas Andersen", "books": ["b1", "b2", "b3"]}
{"id": "a2", "name": "William Wakefield", "books": ["b1", "b4"]}
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101", "authors": ["a1", "a2"]}
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users", "authors": ["a1"]}
{"id": "b3", "name": "Learn about Azure Cosmos DB", "authors": ["a1"]}
{"id": "b4", "name": "Deep Dive into Azure Cosmos DB", "authors": ["a2"]}
Now, if I had an author, I immediately know which books they've written, and conversely if I had a book document loaded I would know the IDs of the authors. This saves that intermediary query against the join table reducing the number of server round trips your application has to make.
We've now looked at embedding (or denormalizing) and referencing (or normalizing) data. Each approach has upsides and compromises.
It doesn't always have to be either-or, don't be scared to mix things up a little.
Based on your application's specific usage patterns and workloads there might be cases where mixing embedded and referenced data makes sense and could lead to simpler application logic with fewer server round trips while still maintaining a good level of performance.
Consider the following JSON.
Author documents:
{
"id": "a1",
"firstName": "Thomas",
"lastName": "Andersen",
"countOfBooks": 3,
"books": ["b1", "b2", "b3"],
"images": [
{"thumbnail": "https://....png"}
{"profile": "https://....png"}
{"large": "https://....png"}
]
},
{
"id": "a2",
"firstName": "William",
"lastName": "Wakefield",
"countOfBooks": 1,
"books": ["b1"],
"images": [
{"thumbnail": "https://....png"}
]
}
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
{"id": "a2", "name": "William Wakefield", "thumbnailUrl": "https://....png"}
]
},
{
"id": "b2",
"name": "Azure Cosmos DB for RDBMS Users",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
]
}
Here we've (mostly) followed the embedded model, where data from other entities are embedded in the top-level document, but other data is referenced.
If you look at the book document, we can see a few interesting fields when we look at the array of authors. There's an id field that is the field we use to refer back to an author document, standard practice in a normalized model, but then we also have name and thumbnailUrl. We could have stuck with id and left the application to get any additional information it needed from the respective author document using the "link", but because our application displays the author's name and a thumbnail picture with every book displayed we can save a round trip to the server per book in a list by denormalizing some data from the author.
Sure, if the author's name changed or they wanted to update their photo we'd have to update every book they ever published but for our application, based on the assumption that authors don't change their names often, this is an acceptable design decision.
In the example, there are pre-calculated aggregates values to save expensive processing on a read operation. In the example, some of the data embedded in the author document is data that is calculated at run-time. Every time a new book is published, a book document is created and the countOfBooks field is set to a calculated value based on the number of book documents that exist for a particular author. This optimization would be good in read heavy systems where we can afford to do computations on writes in order to optimize reads.
The ability to have a model with precalculated fields is made possible because Azure Cosmos DB supports multi-document transactions. Many NoSQL stores can't do transactions across documents and therefore advocate design decisions, such as "always embed everything," due to this limitation. With Azure Cosmos DB, you can use server-side triggers, or stored procedures that insert books and update authors all within an ACID transaction. Now you don't have to embed everything into one document just to be sure that your data remains consistent.
In some scenarios, you might want to mix different document types in the same collection; this is usually the case when you want multiple, related documents to sit in the same partition. For example, you could put both books and book reviews in the same collection and partition it by bookId. In such situation, you usually want to add to your documents with a field that identifies their type in order to differentiate them.
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"bookId": "b1",
"type": "book"
}
Review documents:
{
"id": "r1",
"content": "This book is awesome",
"bookId": "b1",
"type": "review"
},
{
"id": "r2",
"content": "Best book ever!",
"bookId": "b1",
"type": "review"
}
Azure Synapse Link for Azure Cosmos DB is a cloud-native hybrid transactional and analytical processing (HTAP) capability that enables you to run near real-time analytics over operational data in Azure Cosmos DB. Azure Synapse Link creates a tight seamless integration between Azure Cosmos DB and Azure Synapse Analytics.
This integration happens through Azure Cosmos DB analytical store, a columnar representation of your transactional data that enables large-scale analytics without any impact to your transactional workloads. This analytical store is suitable for fast, cost-effective queries on large operational data sets, without copying data and impacting the performance of your transactional workloads. When you create a container with analytical store enabled, or when you enable analytical store on an existing container, all transactional inserts, updates, and deletes are synchronized with analytical store in near real time, no Change Feed or ETL jobs are required.
With Azure Synapse Link, you can now directly connect to your Azure Cosmos DB containers from Azure Synapse Analytics and access the analytical store, at no Request Units (request units) costs. Azure Synapse Analytics currently supports Azure Synapse Link with Synapse Apache Spark and serverless SQL pools. If you have a globally distributed Azure Cosmos DB account, after you enable analytical store for a container, it will be available in all regions for that account.
While Azure Cosmos DB transactional store is considered row-oriented semi-structured data, analytical store has columnar and structured format. This conversion is automatically made for customers, using the schema inference rules for the analytical store. There are limits in the conversion process: maximum number of nested levels, maximum number of properties, unsupported data types, and more.
หมายเหตุ
In the context of analytical store, we consider the following structures as property:
: ".{ and }.[ and ].You can minimize the impact of the schema inference conversions, and maximize your analytical capabilities, by using following techniques.
Normalization becomes meaningless since with Azure Synapse Link you can join between your containers, using T-SQL or Spark SQL. The expected benefits of normalization are:
These last two factors, fewer properties and fewer levels, help in the performance of your analytical queries but also decrease the chances of parts of your data not being represented in the analytical store. As described in the article on automatic schema inference rules, there are limits to the number of levels and properties that are represented in analytical store.
Another important factor for normalization is that SQL serverless pools in Azure Synapse support result sets with up to 1,000 columns, and exposing nested columns also counts towards that limit. In other words, both analytical store and Synapse SQL serverless pools have a limit of 1,000 properties.
But what to do since denormalization is an important data modeling technique for Azure Cosmos DB? The answer is that you must find the right balance for your transactional and analytical workloads.
Your Azure Cosmos DB partition key (PK) isn't used in analytical store. And now you can use analytical store custom partitioning to copies of analytical store using any PK that you want. Because of this isolation, you can choose a PK for your transactional data with focus on data ingestion and point reads, while cross-partition queries can be done with Azure Synapse Link. Let's see an example:
In a hypothetical global IoT scenario, device id is a good PK since all devices have a similar data volume and with that you won't have a hot partition problem. But if you want to analyze the data of more than one device, like "all data from yesterday" or "totals per city," you might have problems since those are cross-partition queries. Those queries can hurt your transactional performance since they use part of your throughput in request units to run. But with Azure Synapse Link, you can run these analytical queries at no request units costs. Analytical store columnar format is optimized for analytical queries and Azure Synapse Link applies this characteristic to allow great performance with Azure Synapse Analytics runtimes.
The automatic schema inference rules article lists what are the supported data types. While unsupported data type blocks the representation in analytical store, supported datatypes might be processed differently by the Azure Synapse runtimes. One example is: When using DateTime strings that follow the ISO 8601 UTC standard, Spark pools in Azure Synapse will represent these columns as string and SQL serverless pools in Azure Synapse will represent these columns as varchar(8000).
Another challenge is that not all characters are accepted by Azure Synapse Spark. While white spaces are accepted, characters like colon, grave accent, and comma aren't. Let's say that your document has a property named "First Name, Last Name". This property is represented in analytical store and Synapse SQL serverless pool can read it without a problem. But since it is in analytical store, Azure Synapse Spark can't read any data from analytical store, including all other properties. At the end of the day, you can't use Azure Synapse Spark when you have one property using the unsupported characters in their names.
All properties in the root level of your Azure Cosmos DB data will be represented in analytical store as a column and everything else that is in deeper levels of your document data model will be represented as JSON, also in nested structures. Nested structures demand extra processing from Azure Synapse runtimes to flatten the data in structured format, what might be a challenge in big data scenarios.
The document will have only two columns in analytical store, id and contactDetails. All other data, email and phone, will require extra processing through SQL functions to be individually read.
{
"id": "1",
"contactDetails": [
{"email": "thomas@andersen.com"},
{"phone": "+1 555 555-5555"}
]
}
The document will have three columns in analytical store, id, email, and phone. All data is directly accessible as columns.
{
"id": "1",
"email": "thomas@andersen.com",
"phone": "+1 555 555-5555"
}
Azure Synapse Link allows you to reduce costs from the following perspectives:
This is a great alternative for situations when a data model already exists and can't be changed. And the existing data model doesn't fit well into analytical store due to automatic schema inference rules like the limit of nested levels or the maximum number of properties. If this is your case, you can use Azure Cosmos DB Change Feed to replicate your data into another container, applying the required transformations for an Azure Synapse Link friendly data model. Let's see an example:
Container CustomersOrdersAndItems is used to store on-line orders including customer and items details: billing address, delivery address, delivery method, delivery status, items price, etc. Only the first 1,000 properties are represented and key information isn't included in analytical store, blocking Azure Synapse Link usage. The container has PBs of records it's not possible to change the application and remodel the data.
Another perspective of the problem is the big data volume. Billions of rows are constantly used by the Analytics Department, what prevents them to use tttl for old data deletion. Maintaining the entire data history in the transactional database because of analytical needs forces them to constantly increase request units provisioning, impacting costs. Transactional and analytical workloads compete for the same resources at the same time.
What to do?
Customers, Orders, and Items. With Change Feed they're normalizing and flattening the data. Unnecessary information is removed from the data model and each container has close to 100 properties, avoiding data loss due to automatic schema inference limits.CustomersOrdersAndItems now has tttl set to keep data for six months only, which allows for another request units usage reduction, since there's a minimum of one request unit per GB in Azure Cosmos DB. Less data, fewer request units.The biggest takeaways from this article are to understand that data modeling in a world that's schema-free is as important as ever.
Just as there's no single way to represent a piece of data on a screen, there's no single way to model your data. You need to understand your application and how it produces, consume, and process the data. Then, by applying some of the guidelines presented here you can set about creating a model that addresses the immediate needs of your application. When your applications need to change, you can use the flexibility of a schema-free database to embrace that change and evolve your data model easily.
กิจกรรม
17 มี.ค. 21 - 21 มี.ค. 10
แอปอัจฉริยะ เข้าร่วมชุด meetup เพื่อสร้างโซลูชัน AI ที่ปรับขนาดได้ตามกรณีการใช้งานจริงกับนักพัฒนาและผู้เชี่ยวชาญร่วมกัน
ลงทะเบียนตอนนี้การฝึกอบรม
ใบรับรอง
ได้รับการรับรองจาก Microsoft: Azure Cosmos DB Developer Specialty - Certifications
เขียนคิวรีที่มีประสิทธิภาพ สร้างนโยบายการจัดทําดัชนี จัดการ และเตรียมใช้งานทรัพยากรใน SQL API และ SDK ด้วย Microsoft Azure Cosmos DB
เอกสาร
Model and partition data with a real-world example - Azure Cosmos DB for NoSQL
Learn how to model and partition data using a real-world example scenario and Azure Cosmos DB for NoSQL.
Databases, containers, and items - Azure Cosmos DB
Learn about the hierarchy of resources that composes an Azure Cosmos DB account in the service's hierarchical resource model.
Azure Cosmos DB for NoSQL accounts provides support for querying items with flexible schemas and native support for JSON.