หมายเหตุ
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลอง ลงชื่อเข้าใช้หรือเปลี่ยนไดเรกทอรีได้
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลองเปลี่ยนไดเรกทอรีได้
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Data Factory in Microsoft Fabric is the next generation of Azure Data Factory, with a simpler architecture, built-in AI, and new features. If you're new to data integration, start with Fabric Data Factory. Existing ADF workloads can upgrade to Fabric to access new capabilities across data science, real-time analytics, and reporting.
The HDInsight Pig activity in a Data Factory pipeline executes Pig queries on your own or on-demand HDInsight cluster. This article builds on the data transformation activities article, which presents a general overview of data transformation and the supported transformation activities.
To learn more, read through the introduction to Azure Data Factory or Synapse Analytics and do the Tutorial: transform data before reading this article.
Add an HDInsight Pig activity to a pipeline with UI
To use an HDInsight Pig activity to a pipeline, complete the following steps:
Search for Pig in the pipeline Activities pane, and drag a Pig activity to the pipeline canvas.
Select the new Pig activity on the canvas if it is not already selected.
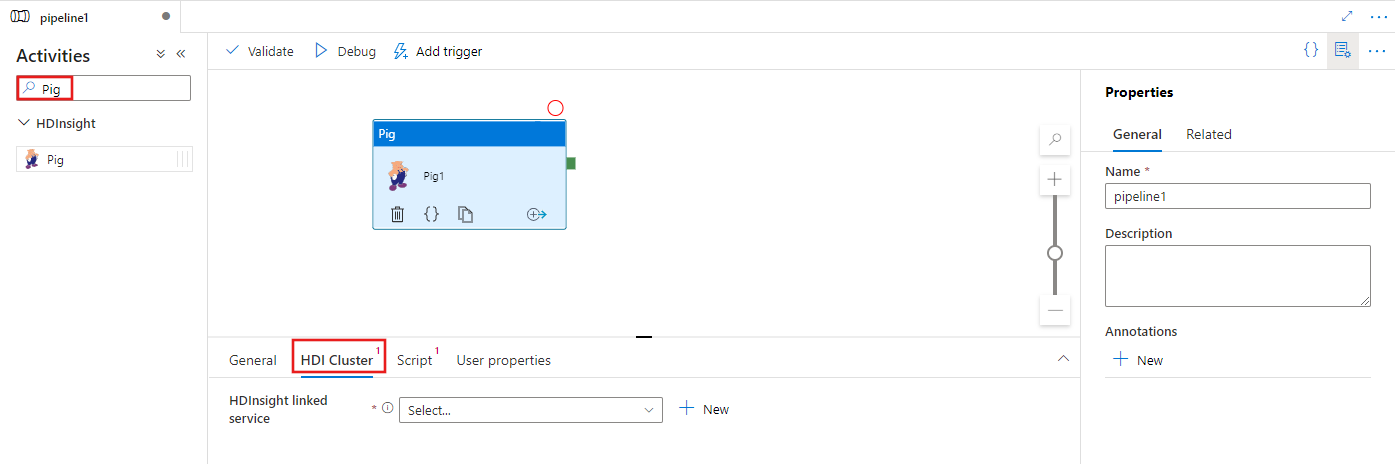
Select the HDI Cluster tab to select or create a new linked service to an HDInsight cluster that will be used to execute the MapReduce activity.
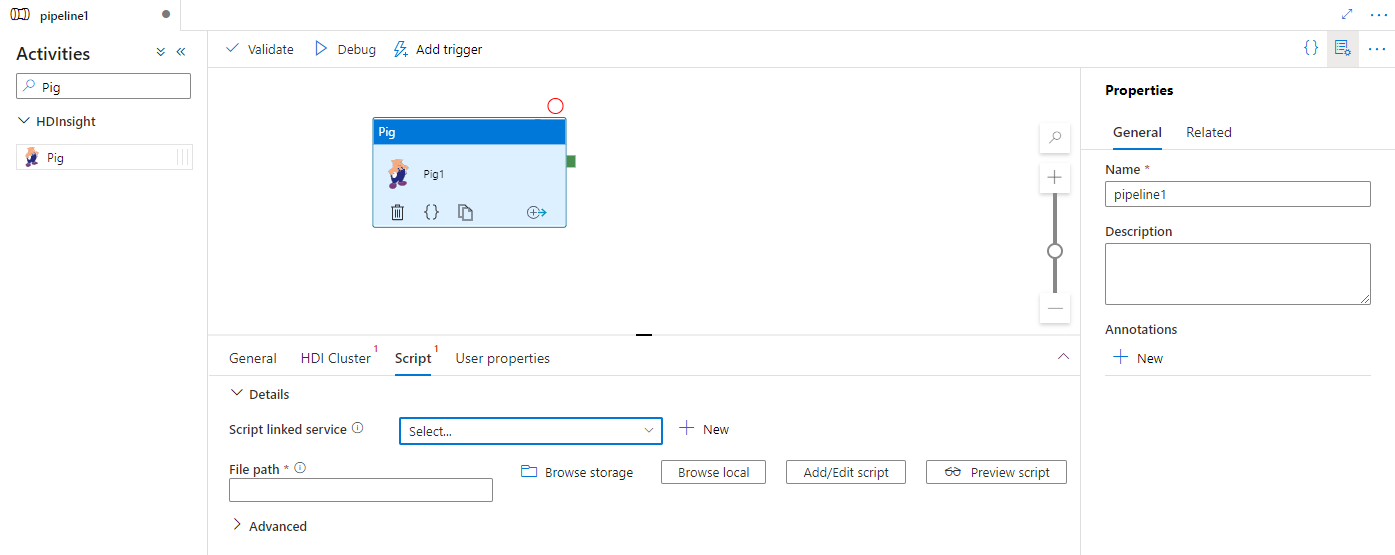
Select the Script tab to select or create a new script linked service to an Azure Storage location where your script will be hosted. Specify a class name to be executed there, and a file path within the storage location. You can also configure advanced details including debugging configuration, and arguments and parameters to be passed to the script.
Syntax
{
"name": "Pig Activity",
"description": "description",
"type": "HDInsightPig",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"scriptLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"scriptPath": "MyAzureStorage\\PigScripts\\MyPigScript.pig",
"getDebugInfo": "Failure",
"arguments": [
"SampleHadoopJobArgument1"
],
"defines": {
"param1": "param1Value"
}
}
}
Syntax details
| Property | Description | Required |
|---|---|---|
| name | Name of the activity | Yes |
| description | Text describing what the activity is used for | No |
| type | For Hive Activity, the activity type is HDinsightPig | Yes |
| linkedServiceName | Reference to the HDInsight cluster registered as a linked service. To learn about this linked service, see Compute linked services article. | Yes |
| scriptLinkedService | Reference to an Azure Storage Linked Service used to store the Pig script to be executed. Only Azure Blob Storage and ADLS Gen2 linked services are supported here. If you don't specify this Linked Service, the Azure Storage Linked Service defined in the HDInsight Linked Service is used. | No |
| scriptPath | Provide the path to the script file stored in the Azure Storage referred by scriptLinkedService. The file name is case-sensitive. | No |
| getDebugInfo | Specifies when the log files are copied to the Azure Storage used by HDInsight cluster (or) specified by scriptLinkedService. Allowed values: None, Always, or Failure. Default value: None. | No |
| arguments | Specifies an array of arguments for a Hadoop job. The arguments are passed as command-line arguments to each task. | No |
| defines | Specify parameters as key/value pairs for referencing within the Pig script. | No |
Related content
See the following articles that explain how to transform data in other ways: