Endpoints for inference in production
APPLIES TO:
 Azure CLI ml extension v2 (current)
Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)
Python SDK azure-ai-ml v2 (current)
Once you've trained machine learning models or pipelines, or you've found models from the model catalog that suit your needs, you need to deploy them to production so that others can use them for inference. Inference is the process of applying new input data to a machine learning model or pipeline to generate outputs. While these outputs are typically referred to as "predictions," inferencing can be used to generate outputs for other machine learning tasks, such as classification and clustering. In Azure Machine Learning, you perform inferencing by using endpoints.
Endpoints and deployments
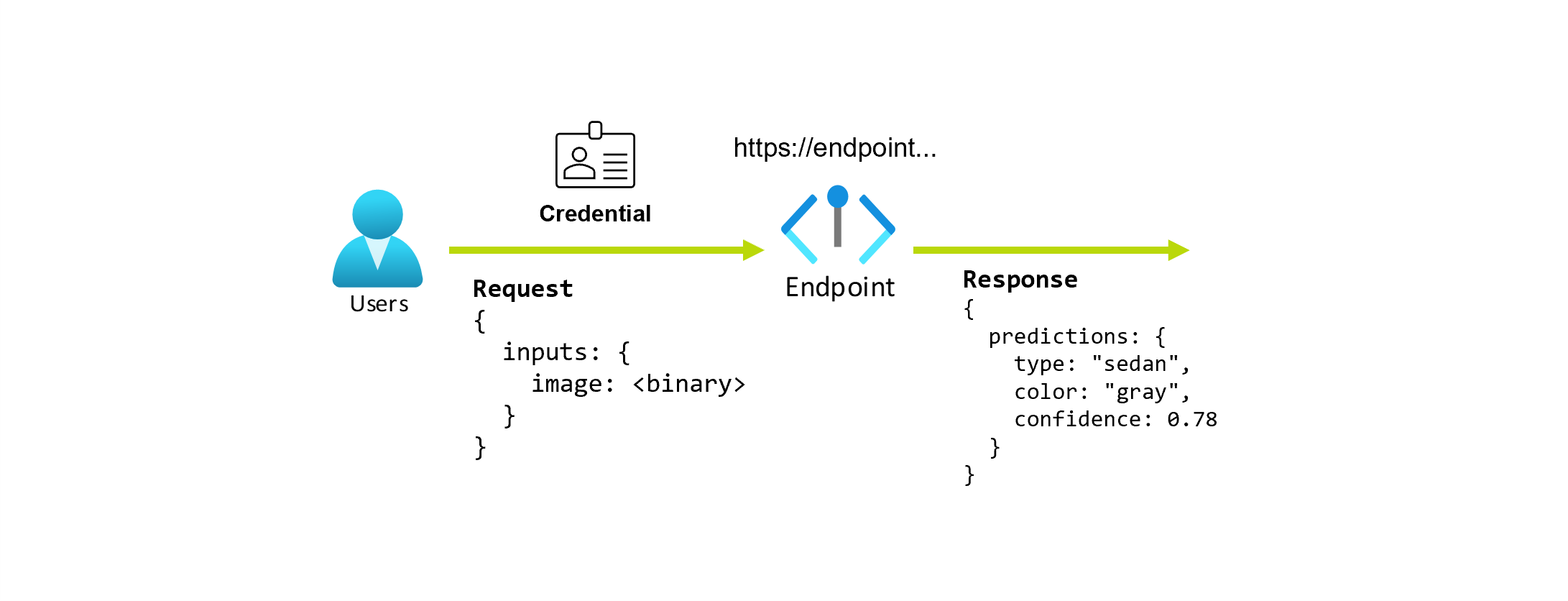
An endpoint is a stable and durable URL that can be used to request or invoke a model. You provide the required inputs to the endpoint and get the outputs back. Azure Machine Learning allows you to implement serverless API endpoints, online endpoints, and batch endpoints. An endpoint provides:
- a stable and durable URL (like endpoint-name.region.inference.ml.azure.com),
- an authentication mechanism, and
- an authorization mechanism.
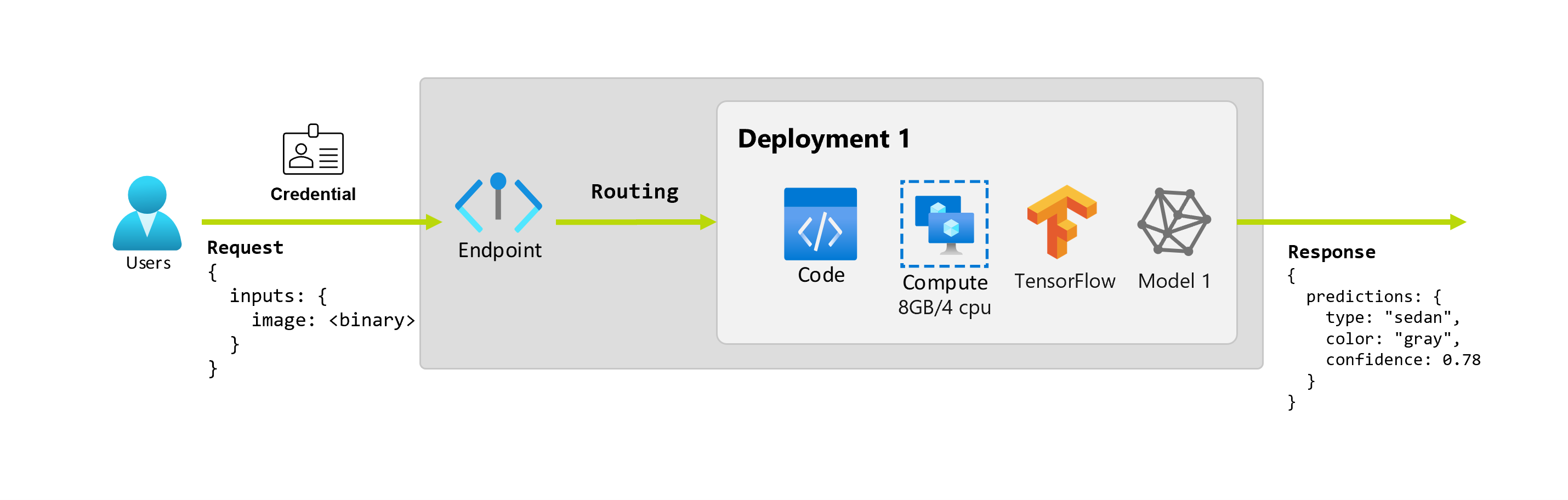
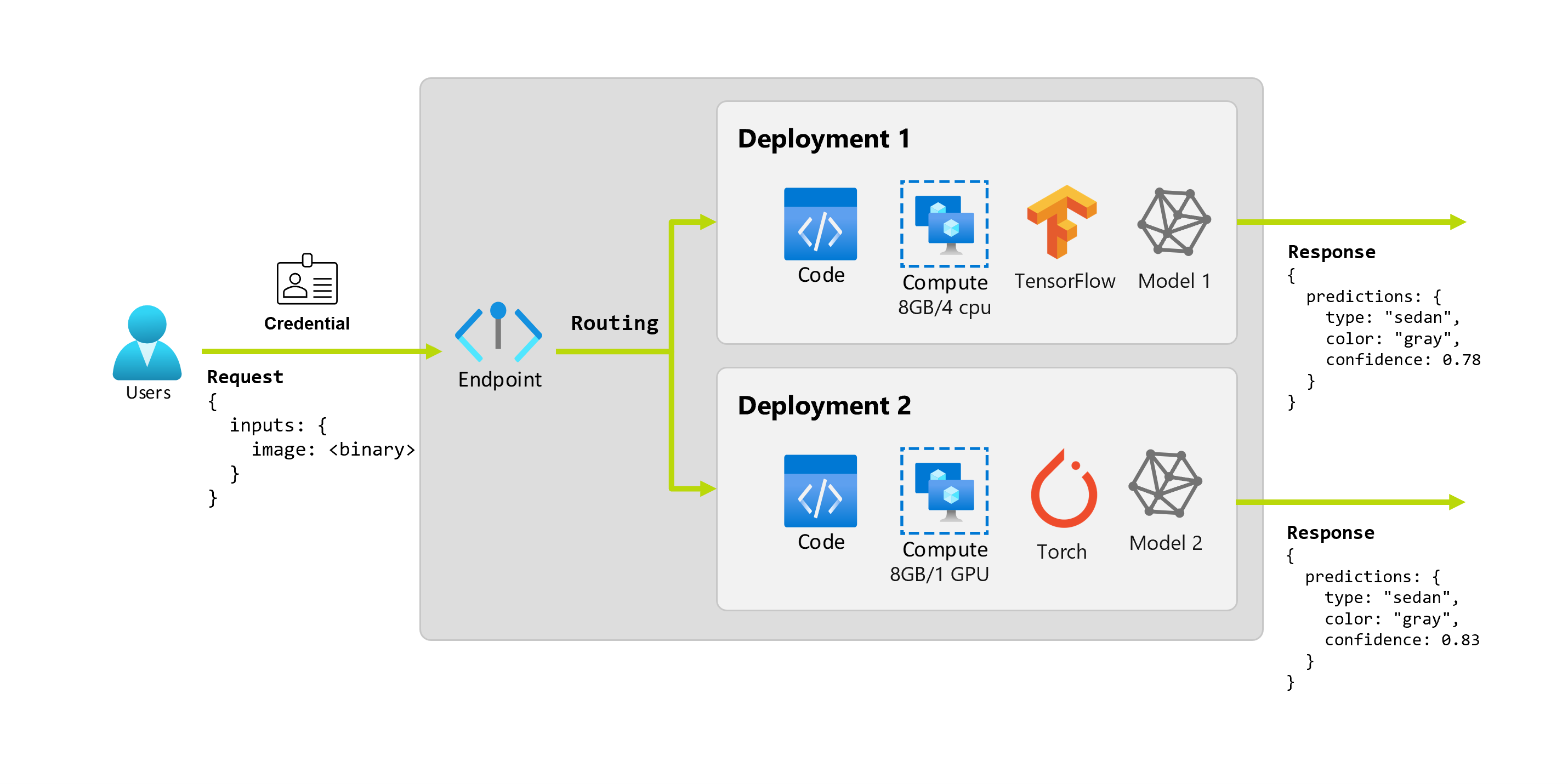
A deployment is a set of resources and computes required for hosting the model or component that does the actual inferencing. An endpoint contains a deployment, and for online and batch endpoints, one endpoint can contain several deployments. The deployments can host independent assets and consume different resources, based on the needs of the assets. Furthermore, an endpoint has a routing mechanism that can direct requests to any of its deployments.
On one hand, some types of endpoints in Azure Machine Learning consume dedicated resources on their deployments. For these endpoints to run, you must have compute quota on your Azure subscription. On the other hand, certain models support a serverless deployment—allowing them to consume no quota from your subscription. For serverless deployment, you're billed based on usage.
Intuition
Suppose you're working on an application that predicts the type and color of a car, given its photo. For this application, a user with certain credentials makes an HTTP request to a URL and provides a picture of a car as part of the request. In return, the user gets a response that includes the type and color of the car as string values. In this scenario, the URL serves as an endpoint.
Furthermore, say that a data scientist, Alice, is working on implementing the application. Alice knows a lot about TensorFlow and decides to implement the model using a Keras sequential classifier with a RestNet architecture from the TensorFlow Hub. After testing the model, Alice is happy with its results and decides to use the model to solve the car prediction problem. The model is large in size and requires 8 GB of memory with 4 cores to run. In this scenario, Alice's model and the resources, such as the code and the compute, that are required to run the model make up a deployment under the endpoint.
Let's imagine that after a couple of months, the organization discovers that the application performs poorly on images with less than ideal illumination conditions. Bob, another data scientist, knows a lot about data augmentation techniques that help a model build robustness on that factor. However, Bob feels more comfortable using Torch to implement the model and trains a new model with Torch. Bob wants to try this model in production gradually until the organization is ready to retire the old model. The new model also shows better performance when deployed to GPU, so the deployment needs to include a GPU. In this scenario, Bob's model and the resources, such as the code and the compute, that are required to run the model make up another deployment under the same endpoint.
Endpoints: serverless API, online, and batch
Azure Machine Learning allows you to implement serverless API endpoints, online endpoints, and batch endpoints.
Serverless API endpoints and online endpoints are designed for real-time inference. Whenever you invoke the endpoint, the results are returned in the endpoint's response. Serverless API endpoints don't consume quota from your subscription; rather, they're billed with pay-as-you-go billing.
Batch endpoints are designed for long-running batch inference. Whenever you invoke a batch endpoint, you generate a batch job that performs the actual work.
When to use serverless API, online, and batch endpoints
Serverless API endpoints:
Use serverless API endpoints to consume large foundational models for real-time inferencing off-the-shelf or for fine-tuning such models. Not all models are available for deployment to serverless API endpoints. We recommend using this deployment mode when:
- Your model is a foundational model or a fine-tuned version of a foundational model that is available for serverless API deployments.
- You can benefit from a quota-less deployment.
- You don't need to customize the inferencing stack used to run the model.
Online endpoints:
Use online endpoints to operationalize models for real-time inference in synchronous low-latency requests. We recommend using them when:
- Your model is a foundational model or a fine-tuned version of a foundational model, but it's not supported in serverless API endpoints.
- You have low-latency requirements.
- Your model can answer the request in a relatively short amount of time.
- Your model's inputs fit on the HTTP payload of the request.
- You need to scale up in terms of number of requests.
Batch endpoints:
Use batch endpoints to operationalize models or pipelines for long-running asynchronous inference. We recommend using them when:
- You have expensive models or pipelines that require a longer time to run.
- You want to operationalize machine learning pipelines and reuse components.
- You need to perform inference over large amounts of data that are distributed in multiple files.
- You don't have low latency requirements.
- Your model's inputs are stored in a storage account or in an Azure Machine Learning data asset.
- You can take advantage of parallelization.
Comparison of serverless API, online, and batch endpoints
All serverless API, online, and batch endpoints are based on the idea of endpoints, therefore, you can transition easily from one to the other. Online and batch endpoints are also capable of managing multiple deployments for the same endpoint.
Endpoints
The following table shows a summary of the different features available to serverless API, online, and batch endpoints at the endpoint level.
| Feature | Serverless API endpoints | Online endpoints | Batch endpoints |
|---|---|---|---|
| Stable invocation URL | Yes | Yes | Yes |
| Support for multiple deployments | No | Yes | Yes |
| Deployment's routing | None | Traffic split | Switch to default |
| Mirror traffic for safe rollout | No | Yes | No |
| Swagger support | Yes | Yes | No |
| Authentication | Key | Key and Microsoft Entra ID (preview) | Microsoft Entra ID |
| Private network support (legacy) | No | Yes | Yes |
| Managed network isolation | Yes | Yes | Yes (see required additional configuration) |
| Customer-managed keys | NA | Yes | Yes |
| Cost basis | Per endpoint, per minute1 | None | None |
1A small fraction is charged for serverless API endpoints per minute. See the deployments section for the charges related to consumption, which are billed per token.
Deployments
The following table shows a summary of the different features available to serverless API, online, and batch endpoints at the deployment level. These concepts apply to each deployment under the endpoint (for online and batch endpoints), and apply to serverless API endpoints (where the concept of deployment is built into the endpoint).
| Feature | Serverless API endpoints | Online endpoints | Batch endpoints |
|---|---|---|---|
| Deployment types | Models | Models | Models and Pipeline components |
| MLflow model deployment | No, only specific models in the catalog | Yes | Yes |
| Custom model deployment | No, only specific models in the catalog | Yes, with scoring script | Yes, with scoring script |
| Model package deployment 2 | Built-in | Yes (preview) | No |
| Inference server 3 | Azure AI Model Inference API | - Azure Machine Learning Inferencing Server - Triton - Custom (using BYOC) |
Batch Inference |
| Compute resource consumed | None (serverless) | Instances or granular resources | Cluster instances |
| Compute type | None (serverless) | Managed compute and Kubernetes | Managed compute and Kubernetes |
| Low-priority compute | NA | No | Yes |
| Scaling compute to zero | Built-in | No | Yes |
| Autoscaling compute4 | Built-in | Yes, based on resource use | Yes, based on job count |
| Overcapacity management | Throttling | Throttling | Queuing |
| Cost basis5 | Per token | Per deployment: compute instances running | Per job: compute instanced consumed in the job (capped to the maximum number of instances of the cluster) |
| Local testing of deployments | No | Yes | No |
2 Deploying MLflow models to endpoints without outbound internet connectivity or private networks requires packaging the model first.
3 Inference server refers to the serving technology that takes requests, processes them, and creates responses. The inference server also dictates the format of the input and the expected outputs.
4 Autoscaling is the ability to dynamically scale up or scale down the deployment's allocated resources based on its load. Online and batch deployments use different strategies for autoscaling. While online deployments scale up and down based on the resource utilization (like CPU, memory, requests, etc.), batch endpoints scale up or down based on the number of jobs created.
5 Both online and batch deployments charge by the resources consumed. In online deployments, resources are provisioned at deployment time. In batch deployment, resources aren't consumed at deployment time but at the time that the job runs. Hence, there's no cost associated with the batch deployment itself. Likewise, queued jobs don't consume resources either.
Developer interfaces
Endpoints are designed to help organizations operationalize production-level workloads in Azure Machine Learning. Endpoints are robust and scalable resources, and they provide the best capabilities to implement MLOps workflows.
You can create and manage batch and online endpoints with several developer tools:
- The Azure CLI and the Python SDK
- Azure Resource Manager/REST API
- Azure Machine Learning studio web portal
- Azure portal (IT/Admin)
- Support for CI/CD MLOps pipelines using the Azure CLI interface & REST/ARM interfaces