Track ML models with MLflow and Azure Machine Learning
APPLIES TO:  Python SDK azureml v1
Python SDK azureml v1
In this article, learn how to enable MLflow Tracking to connect Azure Machine Learning as the backend of your MLflow experiments.
MLflow is an open-source library for managing the lifecycle of your machine learning experiments. MLflow Tracking is a component of MLflow that logs and tracks your training run metrics and model artifacts, no matter your experiment's environment--locally on your computer, on a remote compute target, a virtual machine, or an Azure Databricks cluster.
See MLflow and Azure Machine Learning for all supported MLflow and Azure Machine Learning functionality including MLflow Project support (preview) and model deployment.
Tip
If you want to track experiments running on Azure Databricks or Azure Synapse Analytics, see the dedicated articles Track Azure Databricks ML experiments with MLflow and Azure Machine Learning or Track Azure Synapse Analytics ML experiments with MLflow and Azure Machine Learning.
Note
The information in this document is primarily for data scientists and developers who want to monitor the model training process. If you are an administrator interested in monitoring resource usage and events from Azure Machine Learning, such as quotas, completed training jobs, or completed model deployments, see Monitoring Azure Machine Learning.
Prerequisites
Install the
mlflowpackage.- You can use the MLflow Skinny which is a lightweight MLflow package without SQL storage, server, UI, or data science dependencies. This is recommended for users who primarily need the tracking and logging capabilities without importing the full suite of MLflow features including deployments.
Install the
azureml-mlflowpackage.Install and set up Azure Machine Learning CLI (v1) and make sure you install the ml extension.
Important
Some of the Azure CLI commands in this article use the
azure-cli-ml, or v1, extension for Azure Machine Learning. Support for the v1 extension will end on September 30, 2025. You will be able to install and use the v1 extension until that date.We recommend that you transition to the
ml, or v2, extension before September 30, 2025. For more information on the v2 extension, see Azure ML CLI extension and Python SDK v2.Install and set up Azure Machine Learning SDK for Python.
Track runs from your local machine or remote compute
Tracking using MLflow with Azure Machine Learning lets you store the logged metrics and artifacts runs that were executed on your local machine into your Azure Machine Learning workspace.
Set up tracking environment
To track a run that is not running on Azure Machine Learning compute (from now on referred to as "local compute"), you need to point your local compute to the Azure Machine Learning MLflow Tracking URI.
Note
When running on Azure Compute (Azure Notebooks, Jupyter Notebooks hosted on Azure Compute Instances or Compute Clusters) you don't have to configure the tracking URI. It's automatically configured for you.
APPLIES TO:
Python SDK azureml v1
You can get the Azure Machine Learning MLflow tracking URI using the Azure Machine Learning SDK v1 for Python. Ensure you have the library azureml-sdk installed in the cluster you are using. The following sample gets the unique MLFLow tracking URI associated with your workspace. Then the method set_tracking_uri() points the MLflow tracking URI to that URI.
Using the workspace configuration file:
from azureml.core import Workspace import mlflow ws = Workspace.from_config() mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())Tip
You can download the workspace configuration file by:
- Navigate to Azure Machine Learning studio
- Click on the uper-right corner of the page -> Download config file.
- Save the file
config.jsonin the same directory where you are working on.
Using the subscription ID, resource group name and workspace name:
from azureml.core import Workspace import mlflow #Enter details of your Azure Machine Learning workspace subscription_id = '<SUBSCRIPTION_ID>' resource_group = '<RESOURCE_GROUP>' workspace_name = '<AZUREML_WORKSPACE_NAME>' ws = Workspace.get(name=workspace_name, subscription_id=subscription_id, resource_group=resource_group) mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
Set experiment name
All MLflow runs are logged to the active experiment. By default, runs are logged to an experiment named Default that is automatically created for you. To configure the experiment you want to work on use MLflow command mlflow.set_experiment().
experiment_name = 'experiment_with_mlflow'
mlflow.set_experiment(experiment_name)
Tip
When submitting jobs using Azure Machine Learning SDK, you can set the experiment name using the property experiment_name when you submit it. You don't have to configure it on your training script.
Start training run
After you set the MLflow experiment name, you can start your training run with start_run(). Then use log_metric() to activate the MLflow logging API and begin logging your training run metrics.
import os
from random import random
with mlflow.start_run() as mlflow_run:
mlflow.log_param("hello_param", "world")
mlflow.log_metric("hello_metric", random())
os.system(f"echo 'hello world' > helloworld.txt")
mlflow.log_artifact("helloworld.txt")
For details about how to log metrics, parameters and artifacts in a run using MLflow view How to log and view metrics.
Track runs running on Azure Machine Learning
APPLIES TO:
Python SDK azureml v1
Remote runs (jobs) let you train your models in a more robust and repetitive way. They can also leverage more powerful computes, such as Machine Learning Compute clusters. See Use compute targets for model training to learn about different compute options.
When submitting runs, Azure Machine Learning automatically configures MLflow to work with the workspace the run is running in. This means that there is no need to configure the MLflow tracking URI. On top of that, experiments are automatically named based on the details of the experiment submission.
Important
When submitting training jobs to Azure Machine Learning, you don't have to configure the MLflow tracking URI on your training logic as it is already configured for you. You don't need to configure the experiment name in your training routine neither.
Creating a training routine
First, you should create a src subdirectory and create a file with your training code in a train.py file in the src subdirectory. All your training code will go into the src subdirectory, including train.py.
The training code is taken from this MLflow example in the Azure Machine Learning example repo.
Copy this code into the file:
# imports
import os
import mlflow
from random import random
# define functions
def main():
mlflow.log_param("hello_param", "world")
mlflow.log_metric("hello_metric", random())
os.system(f"echo 'hello world' > helloworld.txt")
mlflow.log_artifact("helloworld.txt")
# run functions
if __name__ == "__main__":
# run main function
main()
Configuring the experiment
You will need to use Python to submit the experiment to Azure Machine Learning. In a notebook or Python file, configure your compute and training run environment with the Environment class.
from azureml.core import Environment
from azureml.core.conda_dependencies import CondaDependencies
env = Environment(name="mlflow-env")
# Specify conda dependencies with scikit-learn and temporary pointers to mlflow extensions
cd = CondaDependencies.create(
conda_packages=["scikit-learn", "matplotlib"],
pip_packages=["azureml-mlflow", "pandas", "numpy"]
)
env.python.conda_dependencies = cd
Then, construct ScriptRunConfig with your remote compute as the compute target.
from azureml.core import ScriptRunConfig
src = ScriptRunConfig(source_directory="src",
script=training_script,
compute_target="<COMPUTE_NAME>",
environment=env)
With this compute and training run configuration, use the Experiment.submit() method to submit a run. This method automatically sets the MLflow tracking URI and directs the logging from MLflow to your Workspace.
from azureml.core import Experiment
from azureml.core import Workspace
ws = Workspace.from_config()
experiment_name = "experiment_with_mlflow"
exp = Experiment(workspace=ws, name=experiment_name)
run = exp.submit(src)
View metrics and artifacts in your workspace
The metrics and artifacts from MLflow logging are tracked in your workspace. To view them anytime, navigate to your workspace and find the experiment by name in your workspace in Azure Machine Learning studio. Or run the below code.
Retrieve run metric using MLflow get_run().
from mlflow.tracking import MlflowClient
# Use MlFlow to retrieve the run that was just completed
client = MlflowClient()
run_id = mlflow_run.info.run_id
finished_mlflow_run = MlflowClient().get_run(run_id)
metrics = finished_mlflow_run.data.metrics
tags = finished_mlflow_run.data.tags
params = finished_mlflow_run.data.params
print(metrics,tags,params)
To view the artifacts of a run, you can use MlFlowClient.list_artifacts()
client.list_artifacts(run_id)
To download an artifact to the current directory, you can use MLFlowClient.download_artifacts()
client.download_artifacts(run_id, "helloworld.txt", ".")
For more details about how to retrieve information from experiments and runs in Azure Machine Learning using MLflow view Manage experiments and runs with MLflow.
Compare and query
Compare and query all MLflow runs in your Azure Machine Learning workspace with the following code. Learn more about how to query runs with MLflow.
from mlflow.entities import ViewType
all_experiments = [exp.experiment_id for exp in MlflowClient().list_experiments()]
query = "metrics.hello_metric > 0"
runs = mlflow.search_runs(experiment_ids=all_experiments, filter_string=query, run_view_type=ViewType.ALL)
runs.head(10)
Automatic logging
With Azure Machine Learning and MLFlow, users can log metrics, model parameters and model artifacts automatically when training a model. A variety of popular machine learning libraries are supported.
To enable automatic logging insert the following code before your training code:
mlflow.autolog()
Learn more about Automatic logging with MLflow.
Manage models
Register and track your models with the Azure Machine Learning model registry, which supports the MLflow model registry. Azure Machine Learning models are aligned with the MLflow model schema making it easy to export and import these models across different workflows. The MLflow-related metadata, such as run ID, is also tracked with the registered model for traceability. Users can submit training runs, register, and deploy models produced from MLflow runs.
If you want to deploy and register your production ready model in one step, see Deploy and register MLflow models.
To register and view a model from a run, use the following steps:
Once a run is complete, call the
register_model()method.# the model folder produced from a run is registered. This includes the MLmodel file, model.pkl and the conda.yaml. model_path = "model" model_uri = 'runs:/{}/{}'.format(run_id, model_path) mlflow.register_model(model_uri,"registered_model_name")View the registered model in your workspace with Azure Machine Learning studio.
In the following example the registered model,
my-modelhas MLflow tracking metadata tagged.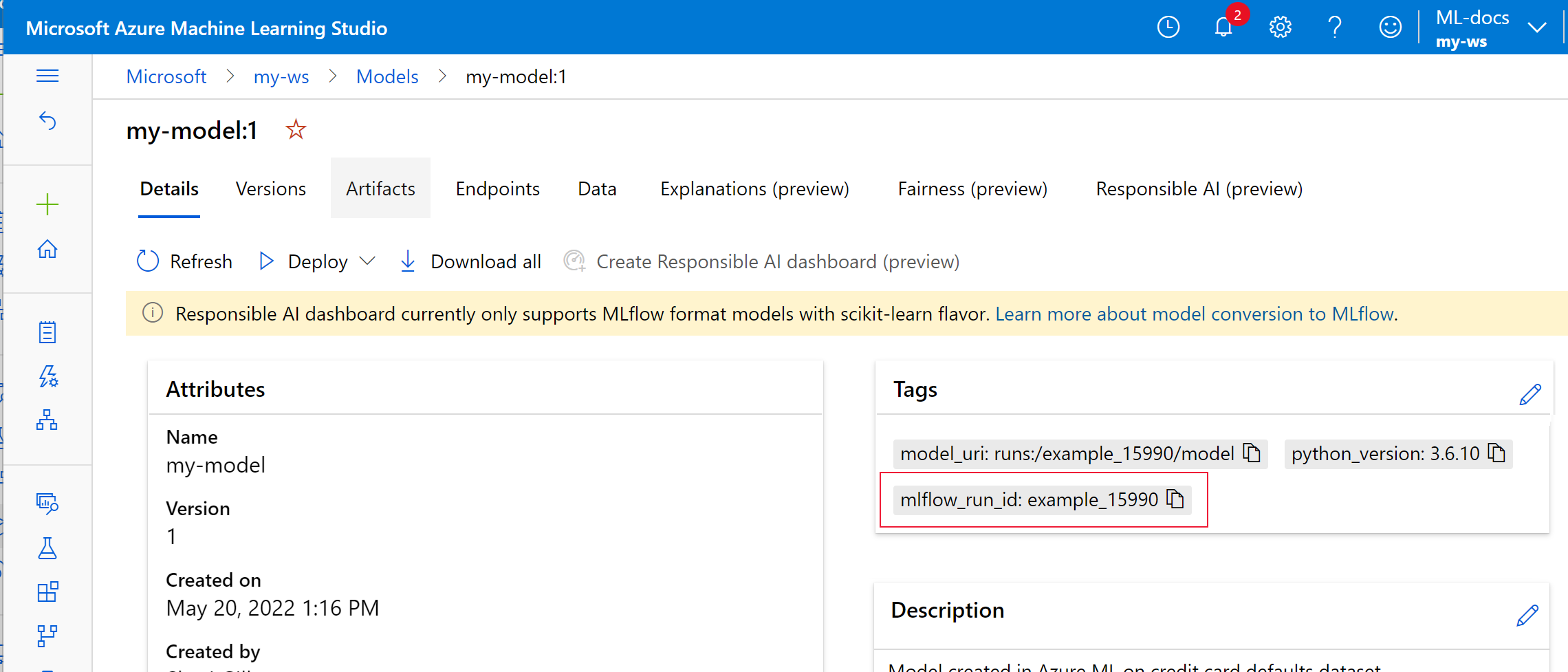
Select the Artifacts tab to see all the model files that align with the MLflow model schema (conda.yaml, MLmodel, model.pkl).
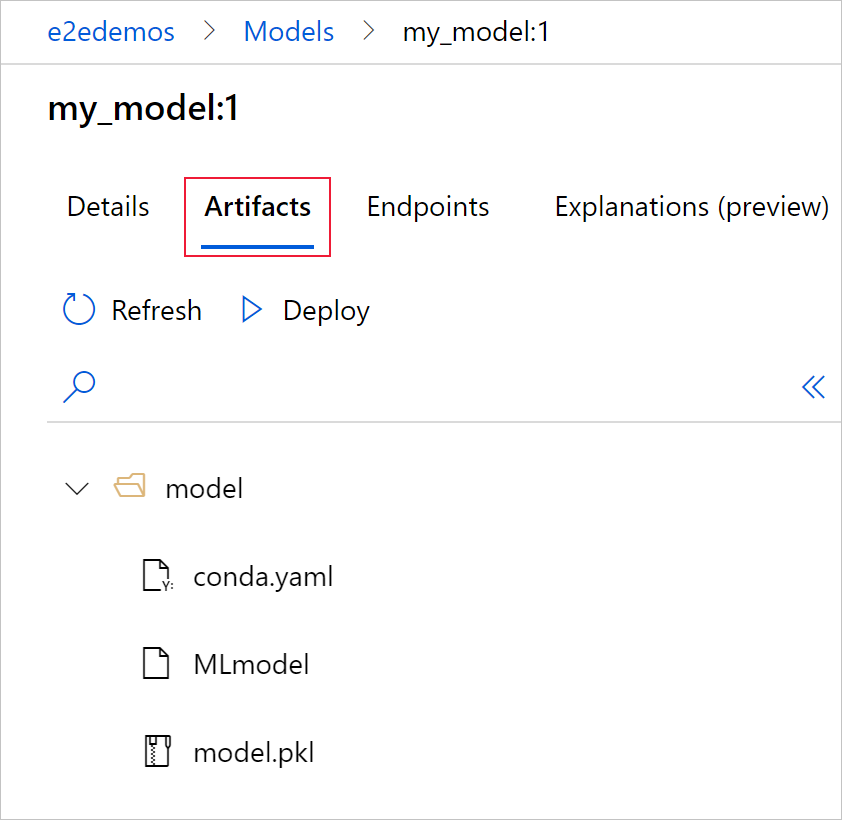
Select MLmodel to see the MLmodel file generated by the run.

Clean up resources
If you don't plan to use the logged metrics and artifacts in your workspace, the ability to delete them individually is currently unavailable. Instead, delete the resource group that contains the storage account and workspace, so you don't incur any charges:
In the Azure portal, select Resource groups on the far left.

From the list, select the resource group you created.
Select Delete resource group.
Enter the resource group name. Then select Delete.
Example notebooks
The MLflow with Azure Machine Learning notebooks demonstrate and expand upon concepts presented in this article. Also see the community-driven repository, AzureML-Examples.
Next steps
- Deploy models with MLflow.
- Monitor your production models for data drift.
- Track Azure Databricks runs with MLflow.
- Manage your models.