แนวทางปฏิบัติที่ดีที่สุดในการรวมข้อมูล
เมื่อคุณตั้งกฎเกณฑ์เพื่อรวมข้อมูลของคุณลงในโปรไฟล์ลูกค้า โปรดพิจารณาแนวทางปฏิบัติที่ดีที่สุดต่อไปนี้:
เวลาสมดุลในการรวมเข้ากับการจับคู่ที่สมบูรณ์ การพยายามที่จะจับคู่ให้ตรงกันทุกอันที่เป็นไปได้นั้นนำไปสู่กฎเกณฑ์ต่างๆ มากมาย และการรวมกันนั้นต้องใช้เวลานาน
เพิ่มกฎเกณฑ์อย่างค่อยเป็นค่อยไปและติดตามผลลัพธ์ ลบกฎที่ไม่ทำให้ผลการแข่งขันดีขึ้น
กำจัดข้อมูลที่ซ้ำกันในแต่ละตาราง เพื่อให้ลูกค้าแต่ละรายแสดงอยู่ในแถวเดียว
ใช้ การทำให้เป็นมาตรฐาน เพื่อทำให้การเปลี่ยนแปลง ในวิธีป้อนข้อมูลเป็นมาตรฐาน เช่น ถนน เทียบกับ ถนนสายหลัก เทียบกับ ถนนสายรอง
ใช้การจับคู่แบบคลุมเครือ อย่างมีกลยุทธ์เพื่อแก้ไขข้อผิดพลาดในการพิมพ์และข้อผิดพลาด เช่น และ bob@contoso.com การจับคู่แบบคลุมเครือจะใช้เวลาดำเนินการนานกว่าการจับคู่แบบตรงเป๊ะ bob@contoso.cm ทดสอบเสมอเพื่อดูว่าเวลาเพิ่มเติมที่ใช้ในการจับคู่แบบคลุมเครือคุ้มกับอัตราการจับคู่เพิ่มเติมหรือไม่
จำกัดขอบเขตการจับคู่ด้วย ตรงกันเป๊ะ ตรวจสอบให้แน่ใจว่ากฎทุกข้อที่มีเงื่อนไขคลุมเครือจะมีเงื่อนไขที่ตรงกันอย่างน้อยหนึ่งเงื่อนไข
อย่าจับคู่คอลัมน์ที่มีข้อมูลซ้ำกันหนักๆ ตรวจสอบให้แน่ใจว่าคอลัมน์ที่จับคู่แบบคลุมเครือไม่มีค่าที่ซ้ำกันบ่อยๆ เช่น ค่าเริ่มต้นของแบบฟอร์มที่เป็น "ชื่อ"
การดำเนินงานรวม
กฎแต่ละข้อจะใช้เวลาในการทำงาน รูปแบบต่างๆ เช่น การเปรียบเทียบตารางทั้งหมดกับตารางอื่นๆ หรือการพยายามจับคู่ระเบียนที่เป็นไปได้ทั้งหมดอาจทำให้การประมวลผลการรวมข้อมูลใช้เวลานาน นอกจากนี้ ยังส่งคืนผลลัพธ์ที่ตรงกันเพียงเล็กน้อยหรือไม่มีเลยในแผนที่เปรียบเทียบตารางแต่ละตารางกับตารางฐานข้อมูล
แนวทางที่ดีที่สุดคือเริ่มต้นด้วยชุดกฎพื้นฐานที่คุณทราบว่าจำเป็น เช่น การเปรียบเทียบตารางแต่ละตารางกับตารางหลักของคุณ ตารางหลักของคุณควรเป็นตารางที่มีข้อมูลที่สมบูรณ์และถูกต้องที่สุด ตารางนี้ควรเรียงลำดับที่ด้านบนในการรวมกฎการจับคู่ ขั้นตอน
เพิ่มกฎหลายๆ ข้อไปเรื่อยๆ แล้วดูว่าการเปลี่ยนแปลงใช้เวลาดำเนินการนานเท่าใด และผลลัพธ์ของคุณดีขึ้นหรือไม่ ไปที่ การตั้งค่า>ระบบ>สถานะ และเลือก การจับคู่ เพื่อดูว่าการลบข้อมูลซ้ำซ้อนและการจับคู่ใช้เวลานานแค่ไหนสำหรับการทำงานรวมกันแต่ละครั้ง
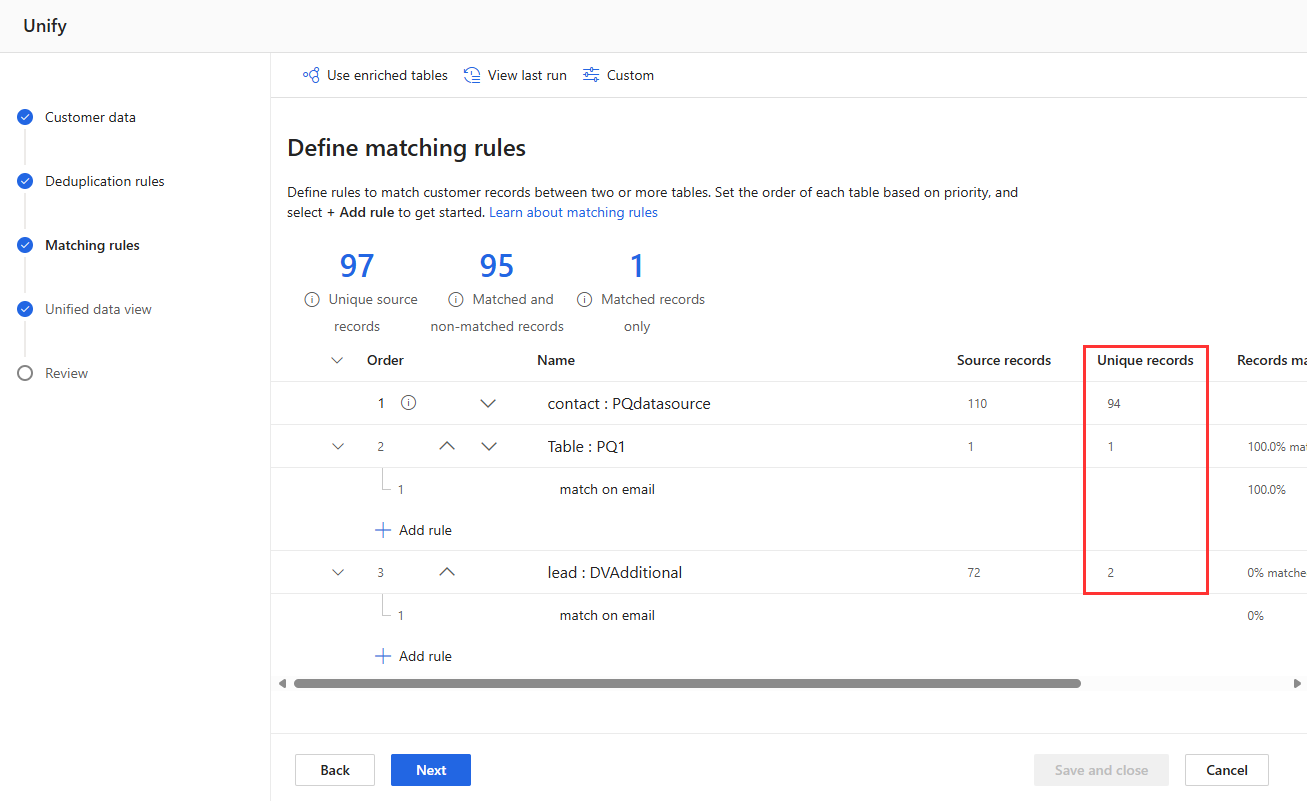
ดูสถิติกฎในหน้า กฎการกำจัดข้อมูลซ้ำซ้อน และ กฎการจับคู่ เพื่อดูว่าจำนวน ระเบียนที่ไม่ซ้ำกัน เปลี่ยนแปลงไปหรือไม่ หากกฎใหม่ตรงกับบางรายการ และจำนวนรายการที่ไม่ซ้ำกันไม่เปลี่ยนแปลง กฎก่อนหน้าจะระบุรายการที่ตรงกันเหล่านั้น
การลบข้อมูลซ้ำซ้อน
ใช้กฎการกำจัดข้อมูลซ้ำซ้อนเพื่อลบข้อมูลลูกค้าที่ซ้ำกันภายในตารางเพื่อให้แถวเดียวในแต่ละตารางแสดงถึงลูกค้าแต่ละราย กฎที่ดีจะระบุถึงลูกค้าที่ไม่ซ้ำกัน
ในตัวอย่างง่ายๆ นี้ บันทึก 1, 2 และ 3 ใช้อีเมลหรือหมายเลขโทรศัพท์ร่วมกัน และแสดงถึงบุคคลเดียวกัน
| ID | Name | หมายเลขโทรศัพท์ | |
|---|---|---|---|
| 1 | บุคคลที่ 1 | (425) 555-1111 | AAA@A.com |
| 2 | บุคคลที่ 1 | (425) 555-1111 | BBB@B.com |
| 3 | บุคคลที่ 1 | (425) 555-2222 | BBB@B.com |
| 4 | บุคคลที่ 2 | (206) 555-9999 | Person2@contoso.com |
เราไม่ต้องการที่จะจับคู่กับชื่อเพียงชื่อเดียว เนื่องจากจะจับคู่บุคคลอื่นที่มีชื่อเดียวกัน
สร้างกฎข้อที่ 1 โดยใช้ชื่อและหมายเลขโทรศัพท์ ซึ่งตรงกับระเบียนที่ 1 และ 2
สร้างกฎข้อที่ 2 โดยใช้ชื่อและอีเมล ซึ่งตรงกับระเบียนที่ 2 และ 3
การรวมกันของกฎข้อที่ 1 และกฎข้อที่ 2 จะสร้างกลุ่มการจับคู่กลุ่มเดียว เนื่องจากทั้งสองกลุ่มมีเรกคอร์ดที่ 2 ร่วมกัน
คุณกำหนดจำนวนกฎและเงื่อนไขที่สามารถระบุตัวลูกค้าของคุณได้อย่างชัดเจน กฎเกณฑ์ที่แน่นอนจะขึ้นอยู่กับข้อมูลที่คุณมีเพื่อจับคู่ คุณภาพของข้อมูลของคุณ และความครอบคลุมที่คุณต้องการให้กระบวนการลบข้อมูลซ้ำซ้อนครอบคลุมแค่ไหน
ผู้ชนะและเรกคอร์ดสำรอง
เมื่อกฎถูกเรียกใช้และระบุระเบียนที่ซ้ำกัน กระบวนการลบข้อมูลซ้ำซ้อนจะเลือก "แถวผู้ชนะ" แถวที่ไม่ชนะจะถูกเรียกว่า "แถวสำรอง" แถวสำรองจะถูกใช้ในการรวมกฎการจับคู่ ขั้นตอน เพื่อจับคู่ระเบียนจากตารางอื่นกับแถวผู้ชนะ แถวจะถูกจับคู่กับข้อมูลในแถวสำรองนอกเหนือจากแถวผู้ชนะ
เมื่อคุณเพิ่มกฎลงในตารางแล้ว คุณสามารถกำหนดค่าแถวที่จะเลือกเป็นแถวผู้ชนะได้ผ่าน การกำหนดค่าการผสาน การตั้งค่าการรวมถูกกำหนดไว้ตามตาราง ไม่ว่าจะเลือกนโยบายการผสานแบบใด หากมีการเสมอกันในแถวผู้ชนะ แถวแรกในลำดับข้อมูลจะถูกใช้เป็นตัวตัดสินเสมอ
การทำให้เป็นมาตรฐาน
ใช้การทำให้เป็นมาตรฐานเพื่อสร้างข้อมูลให้ตรงกันมากขึ้น การทำให้เป็นมาตรฐานมีประสิทธิภาพดีกับชุดข้อมูลขนาดใหญ่
ข้อมูลที่เป็นมาตรฐานจะใช้เพื่อวัตถุประสงค์ในการเปรียบเทียบ เพื่อให้ตรงกับเรกคอร์ดของลูกค้าอย่างมีประสิทธิภาพมากขึ้นเท่านั้น จะไม่เปลี่ยนแปลงข้อมูลในผลลัพธ์โปรไฟล์ลูกค้าแบบรวมสุดท้าย
| การทำให้เป็นมาตรฐาน | ตัวอย่าง |
|---|---|
| ตัวเลข | แปลงสัญลักษณ์ Unicode จำนวนมากที่แสดงตัวเลขให้เป็นตัวเลขธรรมดา ตัวอย่าง: ❽ และ Ⅷ ทั้งคู่ได้รับการทำให้เป็นมาตรฐานเป็นเลข 8 หมายเหตุ: สัญลักษณ์จะต้องเข้ารหัสในรูปแบบ Unicode Point |
| สัญลักษณ์ | ลบสัญลักษณ์และอักขระพิเศษ ตัวอย่าง: !?"#$%&'( )+,.-/:;<=>@^~{}`[ ] |
| ข้อความเป็นตัวพิมพ์เล็ก | แปลงอักขระตัวพิมพ์ใหญ่เป็นตัวพิมพ์เล็ก ตัวอย่าง: "นี่คือตัวอย่าง" ถูกแปลงเป็น "นี่คือตัวอย่าง" |
| ชนิด – โทรศัพท์ | แปลงโทรศัพท์ในรูปแบบต่างๆ ให้เป็นตัวเลข และคำนึงถึงรูปแบบต่างๆ ในการแสดงรหัสประเทศและหมายเลขต่อ ตัวอย่าง: +01 425.555.1212 = 1 (425) 555-1212 |
| ชนิด - ชื่อ | แปลงชื่อและชื่อเรื่องทั่วไปมากกว่า 500 รายการ ตัวอย่าง: "debby" -> "deborah" "prof" and "professor" -> "Prof." |
| ชนิด - ที่อยู่ | แปลงส่วนทั่วไปของที่อยู่ ตัวอย่าง: "street" -> "st" and "northwest" -> "nw" |
| ชนิด - องค์กร | ลบคำที่ไม่สำคัญในชื่อบริษัทประมาณ 50 คำ เช่น "co" "corp" "corporation" และ "ltd" |
| Unicode เป็น ASCII | แปลงอักขระ Unicode เป็นตัวอักษรเทียบเท่ากับ ASCII ตัวอย่าง: อักขระ 'à,' 'á,' 'â,' 'À,' 'Á,' 'Â,' 'Ã,' 'Ä,' 'Ⓐ,' และ 'A' ทั้งหมดถูกแปลงเป็น 'a' |
| ช่องว่าง | ลบช่องว่างทั้งหมด |
| การแมปนามแฝง | ช่วยให้คุณสามารถอัปโหลดรายการคู่สตริงที่กำหนดเอง ซึ่งสามารถใช้เพื่อระบุสตริงที่ควรพิจารณาว่าเป็นการทำงานแบบตรงทั้งหมดเสมอ ใช้การแมปนามแฝงเมื่อคุณมีตัวอย่างข้อมูลเฉพาะที่คุณคิดว่าควรตรงกันและไม่ตรงกัน โดยใช้รูปแบบการปรับมาตรฐานอย่างใดอย่างหนึ่ง ตัวอย่าง: Scott และ Scooter หรือ MSFT และ Microsoft |
| บายพาสแบบกําหนดเอง | ช่วยให้คุณสามารถอัปโหลดรายการสตริงที่ ซึ่งสามารถใช้เพื่อระบุสตริงที่ไม่ควรตรงกัน การหลีกเลี่ยงแบบกำหนดเองนั้นมีประโยชน์เมื่อคุณมีข้อมูลที่มีค่าทั่วไปที่ควรจะละเว้น เช่น หมายเลขโทรศัพท์หลอกหรืออีเมลหลอก ตัวอย่าง: ไม่ตรงกับโทรศัพท์ 555-1212 หรือ test@contoso.com |
ตรงกันทุกประการ
ใช้ความแม่นยำในการกำหนดว่าควรให้สตริงทั้งสองใกล้เคียงกันแค่ไหนจึงจะถือว่าตรงกัน การตั้งค่าความแม่นยำเริ่มต้นต้องใช้ค่าที่ตรงกันทุกประการ ค่าอื่น ๆ ช่วยให้สามารถจับคู่แบบคลุมเครือสำหรับเงื่อนไขนั้นได้
ความแม่นยำสามารถตั้งค่าเป็นต่ำ (ตรงกัน 30%) ปานกลาง (ตรงกัน 60%) และสูง (ตรงกัน 80%) หรือคุณสามารถปรับแต่งและตั้งค่าความแม่นยำได้ครั้งละ 1%
เงื่อนไขที่ตรงกันเป๊ะ
ก่อนอื่นจะมีการเรียกใช้เงื่อนไขการจับคู่ที่แน่นอนเพื่อให้ได้ชุดค่าที่เล็กกว่าสำหรับการจับคู่แบบคลุมเครือ เพื่อให้มีประสิทธิภาพ เงื่อนไขการจับคู่ที่ตรงกันทุกประการควรมีความเป็นเอกลักษณ์ในระดับที่เหมาะสม ตัวอย่างเช่น หากลูกค้าของคุณทั้งหมดอาศัยอยู่ในประเทศ/ภูมิภาคเดียวกัน การมีข้อมูลที่ตรงกันกับประเทศ/ภูมิภาคนั้นจะไม่ช่วยจำกัดขอบเขตได้
คอลัมน์ เช่น ช่องชื่อนามสกุล อีเมล หมายเลขโทรศัพท์ หรือที่อยู่ มีเอกลักษณ์เฉพาะตัวที่ดีและเป็นคอลัมน์ที่ยอดเยี่ยมในการใช้เป็นข้อมูลที่ตรงกันแน่นอน
ตรวจสอบให้แน่ใจว่าคอลัมน์ที่คุณใช้สำหรับเงื่อนไขการจับคู่ที่แน่นอนไม่มีค่าใดๆ ที่ซ้ำกันบ่อยๆ เช่น ค่าเริ่มต้น "ชื่อ" ที่จับโดยแบบฟอร์ม ข้อมูลเชิงลึกของลูกค้าสามารถสร้างโปรไฟล์คอลัมน์ข้อมูลเพื่อให้เข้าใจถึงค่าที่เกิดซ้ำสูงสุด คุณสามารถเปิดใช้งานการจัดทำโปรไฟล์ข้อมูลบนการเชื่อมต่อ Azure Data Lake (โดยใช้ Common Data Model หรือรูปแบบ Delta) และ Synapse ได้ โปรไฟล์ข้อมูลจะทำงานเมื่อมีการรีเฟรช แหล่งข้อมูล ครั้งถัดไป หากต้องการข้อมูลเพิ่มเติม โปรดไปที่ การจัดทำโปรไฟล์ข้อมูล -
การจับคู่แบบฟัซซี่
ใช้การจับคู่แบบคลุมเครือเพื่อจับคู่สตริงที่ใกล้เคียงแต่ไม่ตรงกันเนื่องจากการพิมพ์ผิดหรือความแตกต่างเล็กๆ น้อยๆ อื่นๆ ใช้การจับคู่แบบคลุมเครืออย่างมีกลยุทธ์ เนื่องจากจะช้ากว่าการจับคู่แบบแน่นอน ตรวจสอบให้แน่ใจว่ามีเงื่อนไขที่ตรงกันอย่างน้อยหนึ่งเงื่อนไขในกฎใดๆ ที่มีเงื่อนไขคลุมเครือ
การจับคู่แบบคลุมเครือไม่ได้มีวัตถุประสงค์เพื่อจับรูปแบบชื่อที่แตกต่างกันเช่น Suzzie และ Suzanne การเปลี่ยนแปลงเหล่านี้จะถูกจับภาพได้ดีขึ้นโดยใช้รูปแบบการทำให้เป็นมาตรฐาน ประเภท: ชื่อ หรือ การจับคู่นามแฝง แบบกำหนดเอง ซึ่งลูกค้าสามารถป้อนรายชื่อรูปแบบชื่อที่ต้องการพิจารณาให้ตรงกันได้
คุณสามารถเพิ่มเงื่อนไขให้กับกฎ เช่น การจับคู่ชื่อและหมายเลขโทรศัพท์ เงื่อนไขภายในกฎที่กำหนดคือเงื่อนไข "AND" ทุกเงื่อนไขต้องตรงกันจึงจะตรงกันได้ กฎที่แยกกันคือเงื่อนไข "หรือ" หากกฎข้อที่ 1 ไม่ตรงกับแถว ก็จะมีการเปรียบเทียบแถวกับกฎข้อที่ 2
หมายเหตุ
เฉพาะคอลัมน์ชนิดข้อมูลสตริงเท่านั้นที่สามารถใช้การจับคู่แบบคลุมเครือได้ สำหรับคอลัมน์ที่มีประเภทข้อมูลอื่นเช่น จำนวนเต็ม สองเท่า หรือวันที่และเวลา ฟิลด์ความแม่นยำจะเป็นแบบอ่านอย่างเดียวและตั้งค่าให้ตรงกันแน่นอน
การคำนวณการจับคู่แบบคลุมเครือ
การจับคู่แบบฟัซซี่จะถูกกำหนดโดยการคำนวณคะแนนระยะทางการแก้ไขระหว่างสตริงสองสตริง หากคะแนนตรงตามหรือเกินเกณฑ์ความแม่นยำ สตริงนั้นจะถือว่าตรงกัน
ระยะการแก้ไขคือจำนวนการแก้ไขที่จำเป็นในการเปลี่ยนสตริงหนึ่งเป็นอีกสตริงหนึ่ง โดยการเพิ่ม ลบ หรือเปลี่ยนแปลงอักขระ
ตัวอย่างเช่น สตริง "Jacqueline" และ "Jaclyne" มีระยะการแก้ไขห้าเมื่อเราลบอักขระ q, u, e, i และ e และแทรกอักขระ y เข้าไป
ในการคำนวณคะแนนระยะการแก้ไข ให้ใช้สูตรนี้: (ความยาวสตริงฐาน – ระยะการแก้ไข) / ความยาวสตริงฐาน
| สตริงฐาน | การเปรียบเทียบสตริง | คะแนน |
|---|---|---|
| Jacqueline | Jaclyne | (10-4)/10=.6 |
| fred@contoso.com | fred@contso.cm | (14-2) / 14 = 0.857 |
| franklin | frank | (8-3) / 8 = 0.625 |